Regex 正则表达式
正则表达式(Regular Expression简写为Regex),又称为规则表达式,它是一种强大的文本匹配模式,其用于在字符串中查找匹配符合特定规则的子串。
正则表达式由一些普通字符(比如英文字母,数字)和元字符(代表特定含义)组成。
正则表达式作为一个字符模板,在字符串中匹配一个或多个符合特定规则的子串。
基本匹配
正则表达式其实就是在执⾏搜索时的格式,它由⼀些字⺟和数字组合⽽成。 例如:⼀个正则表达式 the ,它表示⼀个规则:由字⺟t 开始,接着是h ,再接着是e 。
“the” => The fat cat sat on the mat.
正则表达式123匹配字符串123。它逐个字符的与输⼊的正则表达式做⽐较。
正则表达式是⼤⼩写敏感的,所以The不会匹配the。
“The” => The fat cat sat on the mat.
\ 转义字符,常用于转义元字符
反斜线 \ 在表达式中⽤于转义紧跟其后的字符。⽤于指定 { } [ ] / \ + * . $ ^ | ? 这些特殊字符。
\s搜索空格,这个小写的s有“空格”之意。此模式不仅匹配空格,还包括回车符、制表符、换页符和换行符等字符。你可以将其看做与字符集[\r\t\f\n\v]类似。
\S搜索非空格。使用它将不再匹配回车符、制表符、换页符和换行符等字符,也可用否定字符集[^\r\t\f\n\v]表示。
空白字符有:空格(‘ ’)、换页(‘\f’)、换行(‘\n’)、回车(‘\r’)、水平制表符(‘\t’)、垂直制表符(‘\v’)六个。
\f 匹配换页符
换页: \f = U+000c
在打印机上,加载下一页.在某些终端模拟器中,它会清除屏幕.
\n 匹配换行符
\r 匹配回车符
终端中,回车效果是输出回到本行行首,结果可能会将这一行之前的输出覆盖掉
在文本文件中
在Windows平台上,换行符是回车符(CR,Carriage Return)和换行符(LF,Line Feed)的组合(即CRLF);在Unix/Linux平台上,换行符只是一个LF字符;在MacOS上,换行符是一个CR字符。
setting -> eol -> \n (LF)
\t 匹配制表符
\v 匹配垂直制表符
垂直制表: \v = U+000b
将表单放在下一行标签位置.
一般文本编辑器对\r \v \f 的显示是没有控制效果的。
qita
\w \d \s
元字符
元字符. 可匹配任意(除了换行符\n)的单字符,意思就是. 可以代表任意(除了换行符\n)的单字符。
定位符
单词边界\b与\B
符号\b 是指一个单词边界,比如空白字符和标点符号、其他符号(如-)、换行符等。
符号\B 表示非单词边界。
开始位置^与结束位置$
符号^ 表示匹配的子串在行首,符号$ 表示匹配的子串在行尾。
限定符用于限定一个子表达式出现的次数,一共6 种
| 字符 | 含义 |
|---|---|
| * | 匹配前面的子表达式零次或多次 |
| + | 匹配前面的子表达式一次或多次 |
| ? | 匹配前面的子表达式零次或一次 |
| {n} | 匹配前面的子表达式n次 |
| {n,} | 匹配前面的子表达式至少n次 |
| {n,m} | 匹配前面的子表达式n 到m 次 |
符号*
模式串ab*c,表示字符a和c 之间需要出现0 次或多次字符b。
符号+
模式串ab+c,表示字符a和c 之间需要出现1 次或多次字符b,即至少出现1次字符b。
符号?
模式串ab?c,表示字符a和c 之间需要出现0 次或1次字符b。
符号{n}和{n,}和{n,m}
ab{3}c:符号b 出现的次数必须是3
ab{3,}c:符号b 出现的次数必须大于等于3
ab{3,5}c:符号b 出现的次数必须在3 和5之间,包括3 和 5
不常用
贪婪匹配和懒惰匹配
*和 + 限定符都是贪婪的,因为它们会尽可能多的匹配文字,只有在它们的后面加上一个 ? 就可以实现非贪婪或最小匹配。
在正则表达式中,可用贪婪(greedy)匹配查找符合正则表达式的字符串的最长的可能字符串,并将其作为匹配结果返回。而懒惰(lazy)匹配是查找符合正则表达式的字符串的最短的可能字符串。
正则表达式默认采⽤贪婪匹配模式,在该模式下意味着会匹配尽可能⻓的⼦串。
我们可以使⽤ ? 将贪婪匹配模式转化为惰性匹配模式。 “.at” => The fat cat sat on the mat.
“.?at” => The fat cat sat on the mat.
lizi:
玩儿吃鸡游戏,晚上一起上游戏,干嘛呢?打游戏啊
玩.*游戏
玩儿吃鸡游戏,晚上一起上游戏,干嘛呢?打游戏
玩.*?游戏
玩儿吃鸡游戏
逻辑或|
符号 | 写在两个子表达式之间表示逻辑或的意思。
字符簇[]
写在中括号[] 内的多个字符代表逻辑或的意思。
模式串a[bef]c,表示a和c中间的字符必须是b或e或f。
当符号^ 写在中括号[] 内时,表示逻辑非的意思。
模式串a[^bef]c,表示a和c中间的字符不能是b或e或f。
符号- 写在中括号[],表示范围的意思:
| 示例 | 含义 |
|---|---|
| [a-z] | 表示a 到z 之间的任意字符 |
| [A-Z] | 表示A 到Z 之间的任意字符 |
| [0-9] | 表示0 到9 之间的任意数字,含义同\d |
| [^0-9] | 表示任意非数字,含义同\D |
| [A-Za-z0-9_] | 表示任意字母,数字或下划线,含义同\w |
| [^A-Za-z0-9_] | 表示任意非字母,非数字,非下划线,含义同\W |
| [ \f\r\t\n] | 表示任意的空白字符,含义同\s |
| [^ \f\r\t\n] | 表示任意的非空白字符,含义同\S |
字符组合()
写在小括号()中的多个字符,会被看成一个整体。
(…) 中包含的内容将会被看成⼀个整体,和数学中⼩括号 () 的作⽤相同。
例如, 表达式 (ab)匹配连续出现 0 或更多个 ab 的字符串 。 如果
没有使⽤ (…) ,那么表达式 ab 将匹配连续出现 0 或更多个 b 。
再⽐如之前说的 {} 是⽤来表示前⾯⼀个字符出现指定次数。
但如果在 {} 前加上特征标群(…) 则表示整个标群内的字符重复 n 次。
我们还可以在 () 中⽤ 或字符 | 表示或。 例如, (c|g|p)ar 匹配 car 或 gar 或 par
“(c|g|p)ar” => The car is parked in the garage.
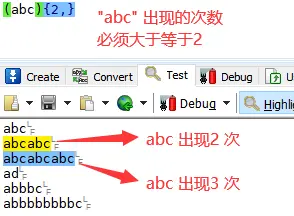
(abc){2,}
abc出现的次数必须大于等于2
捕获组
使用捕获组复用模式
正则表达式中的字符串模式多次出现,手动重复输入这些正则表达式是浪费时间的。有一个更好的方法可以用于你的字符串中有多个重复子串时进行指定,这个方法就是捕获组。
用括号”()”可以定义捕获组,用于查找重复的子串,即把会重复的字符串模式的正则表达式放在括号内。
要指定重复字符串出现的位置,可以使用反斜线”" + 数字的形式。该数字从1开始,并随着用括号定义的捕获组数量而增加。比如\1匹配正则表达式中通过括号定义的第一个捕获组。
使用捕获组来匹配字符串中连续出现3次的数字,每个数字由空格分隔,正则表达式为
(\d+)\s\1\s\1
\1代表捕获组(\d+)内正则表达式匹配的结果,而不是正则表达式\d+。因此,这个正则表示可以匹配123 123 123,但是不能匹配120 210 220。
(注意:是先捕获后复用,即先执行表达式得到结果之后再复用)
在替换中使用捕获组复用模式
如果我们在搜索替换中希望保留搜索字符串中的某些字符串作为替换字符串的一部分,可以使用”$”符号访问搜索字符串中的捕获组。
比如,在搜索正则表达式中的捕获组为capture groups,则替换的正则表达式中可以直接使用$1复用搜索正则表达式中的捕获组capture groups。
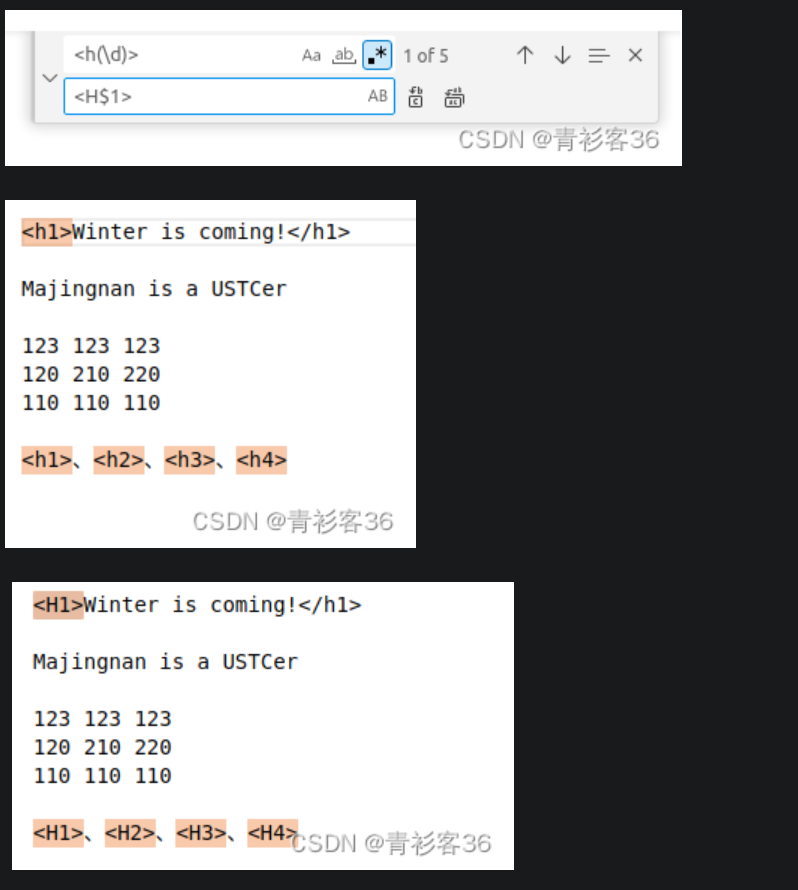
在VSCode中,如果想要把项目中所有的HTML标签中的h改为H,搜索正则表达式<h(\d)>就可以查找出所有标签,如<h1>、<h2>、<h3>、<h4>等,其中还定义了捕获组(\d)。 替换的正则表达式<H$1>使用$1复用了搜索正则表达式中定义的捕获组(\d),如下图所示。
(pattern)
匹配 pattern 并获取这一匹配。所获取的匹配可以从产生的 Matches 集合得到,在VBScript 中使用 SubMatches 集合,在JScript 中则使用 $0…$9 属性。要匹配圆括号字符,请使用 ‘(‘ 或 ‘)‘。
(?:pattern)
匹配 pattern 但不获取匹配结果,也就是说这是一个非获取匹配,不进行存储供以后使用。
这在使用 “或” 字符 (|) 来组合一个模式的各个部分是很有用。例如, ‘industr(?:y|ies) 就是一个比 ‘industry|industries’ 更简略的表达式。
(?=pattern)
正向肯定预查(look ahead positive assert),在任何匹配pattern的字符串开始处匹配查找字符串。
这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。
例如,”Windows(?=95|98|NT|2000)”能匹配”Windows2000”中的”Windows”,但不能匹配”Windows3.1”中的”Windows”。
预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。
| (exp) | 匹配exp并捕获到自动命名的组中
| (?<name&>exp) | 匹配exp并捕获到名为name的组中
| (?:exp) | 匹配exp但是不捕获匹配的文本
| (?=exp) | 匹配exp前面的位置
| (?<=exp) | 匹配exp后面的位置
(?<name>exp) 匹配exp并捕获到名为name的组中
*? 重复任意次,但尽可能少重复
a.b
a.?b
将正则表达式应用于aabab,前者会匹配整个字符串aabab,后者会匹配aab和ab两个字符串
+? 重复1次或多次,但尽可能少重复
?? 重复0次或1次,但尽可能少重复
{M,N}? 重复M到N次,但尽可能少重复
{M,}? 重复M次以上,但尽可能少重复