def print(*values: object, sep: str | None = “ “, end: str | None = “\n”, file: SupportsWrite[str] | None = None, flush: Literal[False] = False) -> None Prints the values to a stream, or to sys.stdout by default.
sep string inserted between values, default a space. end string appended after the last value, default a newline. file a file-like object (stream); defaults to the current sys.stdout. flush whether to forcibly flush the stream. print(*values, sep=" ", end="\n", file=None, flush=False)
1 2 3 4 5 6 7
print('Hello, World!') print("Hello, World!") print(1 + 2) print(7 * 6) print() # The end or is it? keep watching to learn more about python 3 print("The end", "or is it?", "keep watching to learn more about python", 3)
literal: a value of some type
input()
def input(__prompt: object = “”) -> str Read a string from standard input. The trailing newline is stripped. The prompt string, if given, is printed to standard output without a trailing newline before reading input. If the user hits EOF (nix: Ctrl-D, Windows: Ctrl-Z+Return), raise EOFError. Onnix systems, readline is used if available. input(__prompt="")
type()
type(object) -> the object’s type
sum()
Return the sum of a ‘start’ value (default: 0) plus an iterable of numbers
id()
def id(__obj: object) -> int Return the identity of an object. This is guaranteed to be unique among simultaneously existing objects. (CPython uses the object’s memory address.)
immutable type
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
# result = True # another_result = result # # print(id(result)) # 140714778504272 # print(id(another_result)) # 140714778504272 # # result = False # print(id(result)) # 140714778504304
print("Today is a good day to learn Python") print("Python's string are easy to use") print('We can even include "quotes" in strings') print("hello" + " world") # 'hello world'
greeting = "Hello" # name = "Bruce" name = input("Please enter your name ")
print(greeting + name) # HelloBruce # if we want space, we can add that too print(greeting + ' ' + name) # Hello Bruce
# 'This string has been ' # 'split over ' # 'several ' # 'lines' splitString = "This string has been \nsplit over \nseveral \nlines" print(splitString)
# The pet shop owner said "No, no, 'e's uh, ...he's resting". print('The pet shop owner said "No, no, \'e\'s uh, ...he\'s resting".') print("The pet shop owner said \"No, no, 'e's uh, ...he's resting\".")
print("""The pet shop owner said "No, no, 'e's uh, ...he's resting".""")
# This string has been # split over # several # lines anotherSplitString = """This string has been split over several lines""" print(anotherSplitString)
anotherSplitString_1 =""" This string has been split over several lines """ # '' # This string has been # split over # several # lines # '' print(anotherSplitString_1)
# This string has not been split over several lines notSplitString = """This string has not been \ split over \ several \ lines""" print(notSplitString)
# perfered!!! print("C:\\Users\\timbuchalka\\notes.txt") # raw string print(r"C:\Users\timbuchalka\notes.txt")
variable names
must begin with a letter(either upper or lower case) or an underscore_ character
can contain letters, numbers or underscore characters(but cannot begin with a number)
are case sensitive, so greeting and Greeting would refer to 2 different variables
greeting = "Hello" age = 24 # TypeError: can only concatenate str (not "int") to str # print(name + " is " + age + " years old")
constants
Constants are usually defined on a module level and written in all capital letters with underscores separating words. Examples include MAX_OVERFLOW and TOTAL.
numeric data type
int: python has no maximun size of the number float: 64bit, max1.79e+308, min 2.22e-308, 52 digits of percison Deicmal: more precise decimal numbers complex: contain a real and imaginary part, base on the square root of minus one
1 2 3 4 5 6 7 8 9
a = 12 b = 3
print(a + b) # 15 print(a - b) # 9 print(a * b) # 36 print(a / b) # 4.0 float print(a // b) # 4 integer division, rounded down towards minus infinity print(a % b) # 0 modulo: the remainder after integer division
value = "".join(char if char notin seperators else" "for char in number).split() print([int(val) for val in value]) ## [2, 123, 456, 123, 478, 124, 807]
values = [] for char in number: if char notin seperators: values.append(char) else: values.append(' ') value_1 = "".join(values).split() print(value_1) # ['2', '123', '456', '123', '478', '124', '807']
##example print(letters[16:13:-1]) # 'qpo' print(letters[4::-1]) # 'edcba' # first 5 letters print(letters[:-9:-1]) # 'zyxwvuts' # last 8 letters
1 2 3 4 5
letters = []
print(letters[0]) ## first letter, when null have error: IndexError: list index out of range print(letters[:1]) ## first letter, when null no error print(letters[-1:]) ## last letter, when null no error
# Pi is approximately 3.14285714285714279370154144999105483293533325195312 print(f"Pi is approximately {22 / 7:55.50f}") pi = 22 / 7 # Pi is approximately 3.14285714285714279370154144999105483293533325195312 print(f"Pi is approximately {pi:12.50f}")
class str(Sequence[str]) str(object=’’) -> str str(bytes_or_buffer[, encoding[, errors]]) -> str Create a new string object from the given object. If encoding or errors is specified, then the object must expose a data buffer that will be decoded using the given encoding and error handler. Otherwise, returns the result of object.__str__() (if defined) or repr(object). encoding defaults to sys.getdefaultencoding(). errors defaults to ‘strict’.
format()
def format(self: LiteralString, *args: LiteralString, **kwargs: LiteralString) -> LiteralString S.format(*args,**kwargs) -> str Return a formatted version of S, using substitutions from args and kwargs. The substitutions are identified by braces (‘{‘ and ‘}’)
age = 24 print("My age is " + str(age) + " years") # "My age is 24 years" # replacement fields print("My age is {0} years".format(age))
## There are 31 days in Jan, Mar, May, Jul, Aug, Oct and Dec print("There are {0} days in {1}, {2}, {3}, {4}, {5}, {6} and {7}" .format(31, 'Jan', 'Mar','May', 'Jul', 'Aug', 'Oct', 'Dec'))
# No. 1 squared is 1 and cubed is 1 # No. 2 squared is 4 and cubed is 8 # No. 3 squared is 9 and cubed is 27 # No. 4 squared is 16 and cubed is 64
for i inrange(1, 13): print("No. {} squared is {} and cubed is {}".format(i, i ** 2, i ** 3))
# No. 1 squared is 1 and cubed is 1 # No. 2 squared is 4 and cubed is 8 # No. 3 squared is 9 and cubed is 27
for i inrange(1, 13): print("No. {0:2} squared is {1:4} and cubed is {2:4}".format(i, i ** 2, i ** 3))
### < left align, ^ center # No. 1 squared is 1 and cubed is 1 # No. 2 squared is 4 and cubed is 8 # No. 3 squared is 9 and cubed is 27 # No. 4 squared is 16 and cubed is 64 # No. 5 squared is 25 and cubed is 125 print() for i inrange(1, 13): print("No. {0:2} squared is {1:<3} and cubed is {2:^4}".format(i, i ** 2, i ** 3))
print() # Pi is approximately 3.142857142857143 print("Pi is approximately {0:12}".format(22 / 7)) # Pi is approximately 3.142857 ## 6 digits print("Pi is approximately {0:12f}".format(22 / 7))
# Pi is approximately 3.14285714285714279370154144999105483293533325195312 # Pi is approximately 3.14285714285714279370154144999105483293533325195312 # Pi is approximately 3.14285714285714279370154144999105483293533325195312 print("Pi is approximately {0:12.50f}".format(22 / 7)) print("Pi is approximately {0:52.50f}".format(22 / 7)) print("Pi is approximately {0:62.50f}".format(22 / 7))
# Pi is approximately 3.142857142857142793701541449991054832935333252 # Pi is approximately 3.14285714285714279370154144999105483293533325195312 # Pi is approximately 3.142857142857142793701541449991054832935333251953125000 print("Pi is approximately {0:<72.45f}".format(22 / 7)) print("Pi is approximately {0:<72.50f}".format(22 / 7)) print("Pi is approximately {0:<72.54f}".format(22 / 7))
join()
def join(self: LiteralString, __iterable: Iterable[LiteralString]) -> LiteralString Concatenate any number of strings. The string whose method is called is inserted in between each given string. The result is returned as a new string. Example: ‘.’.join([‘ab’, ‘pq’, ‘rs’]) -> ‘ab.pq.rs’
def split(self: LiteralString, sep: LiteralString | None = None, maxsplit: SupportsIndex = -1) -> list[LiteralString] Return a list of the substrings in the string, using sep as the separator string.
sep The separator used to split the string. When set to None (the default value), will split on any whitespace character (including newline, tab and spaces) and will discard empty strings from the result. maxsplit Maximum number of splits (starting from the left). -1 (the default value) means no limit
1 2 3 4 5 6 7 8 9 10
panagram = "The quick brown fox jumps over the lazy dog" panagram = """The quick brown fox jumps\tover the lazy dog"""
def center(self: LiteralString, __width: SupportsIndex, __fillchar: LiteralString = “ “) -> LiteralString Return a centered string of length width. Padding is done using the specified fill character (default is a space).
1 2 3 4 5 6 7 8 9 10 11 12
defbanner_text(text): screen_width = 80 iflen(text) > screen_width -4: print("The text is too long to fit in the specified width") if text == '*': print('*' * screen_width) else: output_string = '**{0}**'.format(text.center(screen_width -4)) print(output_string)
def casefold(self: LiteralString) -> LiteralString Return a version of the string suitable for caseless comparisons
isnumeric()
def isnumeric(self) -> bool Return True if the string is a numeric string, False otherwise. A string is numeric if all characters in the string are numeric and there is at least one character in the string.
isalpha()
def isalpha(self) -> bool Return True if the string is an alphabetic string, False otherwise. A string is alphabetic if all characters in the string are alphabetic and there is at least one character in the string.
The operators in and not in test for collection membership. x in s evaluates to true if x is a member of the collection s, and false otherwise. x not in s returns the negation of x in s. in it make sense for many other object types to support membership tests without being a sequence. In particular, dictionaries (for keys) and sets support membership testing.
if letter in parrot: print("{} is in {}".format(letter, parrot)) else: print("I don't need that letter")
### not in
# activity = input("What would you like to do today? ") # activity = "I want to learn Python" activity = "I want to go to the Cinema"# But I want to go to the cinema if"cinema"notin activity: print("But I want to go to the cinema")
activity = "I want to go to the Cinema"# But I want to go to the cinema if"cinema"notin activity.casefold(): print("But I want to go to the cinema")
count()
def count(self, x: str, __start: SupportsIndex | None = …, __end: SupportsIndex | None = …) -> int S.count(sub[, start[, end]]) -> int Return the number of non-overlapping occurrences of substring sub in string S[start:end]. Optional arguments start and end are interpreted as in slice notation.
def index(self, __value: _T, __start: SupportsIndex = 0, __stop: SupportsIndex = sys.maxsize) -> int Return first index of value. Raises ValueError if the value is not present.
# # find the first item in a list # for index in range(len(shopping_list)): # if shopping_list[index] == item_to_find: # found_at = index # break
if item_to_find in shopping_list: found_at = shopping_list.index(item_to_find)
if found_at isnotNone: print("Item found at index {}".format(found_at)) else: print("{} not found".format(item_to_find))
some random meaning
What are iterator, iterable, and iteration?
Iteration is a general term for taking each item of something, one after another. Any time you use a loop, explicit or implicit, to go over a group of items, that is iteration.
In Python, iterable and iterator have specific meanings.
An iterable is an object that has an __iter__ method which returns an iterator, or which defines a __getitem__ method that can take sequential indexes starting from zero (and raises an IndexError when the indexes are no longer valid). So an iterable is an object that you can get an iterator from.
An iterator is an object with a next (Python 2) or __next__ (Python 3) method.
Whenever you use a for loop, or map, or a list comprehension, etc. in Python, the next method is called automatically to get each item from the iterator, thus going through the process of iteration.
pseudocode
epression
evaluated to a value
refactoring
means changing its structure, without changing its behaviour
edge case and corner cases testing
outlying values at both the low and high ends outlying values at the low end only outlying values at the high end only no outlying values only outlying values(no valid ones) an empty data set
data = [4,5,104,105,110,120,130,130,150, 160,170,183,185,187,188,191,350,360] # data = [4,5,104,105,110,120,130,130,150, # 160,170,183,185,187,188,191] # data = [104,105,110,120,130,130,150, # 160,170,183,185,187,188,191,350,360] # data = [104,105,110,120,130,130,150, # 160,170,183,185,187,188,191] # data = [350,3601,1464,1541,1132,3112,4682] # data = []
## wrong approche # for index, value in enumerate(data): # if value < min_valid or value > max_valid: # del data[index] # print(data)
#### for ordered list # process the low values in the list stop = 0 for index, value inenumerate(data): if value >= min_valid: stop = index break print(stop) # 2 del data[:stop] print(data) # [104, 105, 110, 120, 130, 130, 150, 160, 170, 183, 185, 187, 188, 191, 350, 360] # process the high values in the list # ### error the high outlying test fell # start = -1 # for index, value in enumerate(data): # if value >= max_valid: # start = index # break # print(start) # del data[start:] # print(data) ### more efficient start = 0 for index inrange(len(data) - 1, -1, -1): print(index) if data[index] <= max_valid: start = index + 1 break print(start) del data[start:] print(data)
# process the low values in the list stop = 0 for index, value inenumerate(data): if value >= min_valid: stop = index break del data[:stop] # process the high values in the list
start = 0 for index inrange(len(data) - 1, -1, -1): if data[index] <= max_valid: start = index + 1 break del data[start:]
defsanitise_2(data): top_index = len(data) - 1 for index, value inenumerate(reversed(data)): if value < min_valid or value > max_valid: del data[top_index - index]
defsanitise_3(data): for index inrange(len(data) - 1, -1, -1): current = data[index] if current < min_valid or current > max_valid: del data[index]
if __name__ == '__main__': print("Timing") x = timeit.timeit("sanitise_1(data_list1)", setup="from __main__ import sanitise_1, data_list1", number=1) print("{:15.15f}".format(x)) y = timeit.timeit("sanitise_2(data_list2)", setup="from __main__ import sanitise_2, data_list2", number=1) print("{:15.15f}".format(y)) z = timeit.timeit("sanitise_3(data_list3)", setup="from __main__ import sanitise_3, data_list3", number=1) print("{:15.15f}".format(z))
# name = input("Please enter your name: ") name = 'lucfe' # age = int(input("How old are you, {0}? ".format(name))) age = 15 print(age)
if age >= 18: print("You are old enough to vote") print("Please put an x in the box") else: print("Please come back in {0} years".format(18 - age))
if age < 18: print("Please come back in {0} years".format(18 - age)) elif age == 900: print("Sorry, Yoda, you die in Return of the Jedi") else: print("You are old enough to vote") print("Please put an x in the box")
print("Please guess number between 1 and 10: ") guess = int(input())
if guess < answer: print("Pleaser guess higher") guess = int(input()) if guess == answer: print("Well done, you guessed it") else: print("Sorry, you have not guessed correctly") elif guess > answer: print("Pleaser guess lower") guess = int(input()) if guess == answer: print("Well done, you guessed it") else: print("Sorry, you have not guessed correctly") else: print("You got it first time")
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
answer = 5
print("Please guess number between 1 and 10: ") guess = int(input())
if guess != answer: if guess < answer: print("Please guess higher") else: # guess must be greater than answer print("Please guess lower") guess = int(input()) if guess == answer: print("Well done, you guessed it") else: print("Sorry, you have not guessed correctly") else: print("You guess it first time!")
Boolean expression
or and not
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
age = int(input("How old are you? "))
if age >= 16and age <= 65: print("Have a good day at work")
# Simplify chained comparison if16 <= age <= 65: print("Have a good day at work") else: print("Enjoy your free time")
#### or if age < 16or age > 65: print("Enjoy your free time") else: print("Have a good day at work")
when comparing conditions using and, Python will stop checking as soon as it finds a condition that is False.
when comparing conditions using or, Python will stop checking as soon as it finds a condition that is True.
1 2 3 4 5 6 7 8 9 10
# day = "Monday" day = "Saturday" temperature = 30 # raining = True raining = False
if (day == "Saturday"and temperature > 27) ornot raining: print("Go swimming") else: print("Learn Python")
truthy value
Here are most of the built-in objects considered false:
constants defined to be false: None and False
zero of any numeric type: 0, 0.0, 0j, Decimal(0), Fraction(0, 1)
empty sequences and collections: ‘’, (), [], {}, set(), range(0)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
if0 : print("True") else: print("False")
if'' : print("True") else: print("False")
name = input("Please enter your name: ") # if name != '': if name: print("Hello, {}". format(name)) else: print("Are you the man with no name")
seperators = '' for char in number: ifnot char.isnumeric(): seperators = seperators + char print(seperators) # ",;: ,;"
nest for loop
1 2 3 4
for i inrange(1, 9): for j inrange(1, 9): print("{0} times {1} is {2}".format(j, i, i * j)) print("----------------------")
range()
class range(Sequence[int]) range(stop) -> range object range(start, stop[, step]) -> range object Return an object that produces a sequence of integers from start (inclusive) to stop (exclusive) by step. range(i, j) produces i, i+1, i+2, …, j-1. start defaults to 0, and stop is omitted! range(4) produces 0, 1, 2, 3. These are exactly the valid indices for a list of 4 elements. When step is given, it specifies the increment (or decrement).
1 2 3 4 5
# i is now 1 # i is now 2 # i is now 3 for i inrange(1, 4): print("i is now {}".format(i))
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
# 0 # 1 # 2 # 3 for i inrange(4): print(i)
# 1 # 3 for i inrange(1, 4, 2): print(i)
# 4 # 2 for i inrange(4, 1, -2): print(i)
1 2 3 4 5 6 7
age = int(input("How old are you? ")) ## more efficient if16 <= age <= 65: # if age in range(16,66): print("Have a good day at work") else: print("Enjoy your free time")
print("Please think of a number between {} and {}".format(low, high)) input("Press ENTER to start")
my_number = 837 guesses = 1 whileTrue: print(f"\tGuessing in the range of {low} to {high}") guess = low + (high - low) // 2 low_or_high = input("is {0} the number? enter '0' for correct. " "{0} is higher or lower than the answer? enter '+' for higher, '-' for lower ".format(guess)) if low_or_high == '0': print(f"the number is {guess}") print(f"I guess {guesses} times") break elif low_or_high == '+': # guess is higher than the answer high = guess - 1 elif low_or_high == '-': # guess is lower than the answer low = guess + 1 else: print("Please enter '+', '-', '0'")
guesses = guesses + 1
else in a loop
if the loop terminate normal
for loop end without a break
while loop condition false without break
1 2 3 4 5 6 7 8 9 10
# numbers = [1, 45, 32, 12, 60] # The numbers are unacceptable numbers = [1, 45, 31, 12, 60] # All those numbers are fine
for number in numbers: if number % 8 == 0: print("The numbers are unacceptable") break else: print("All those numbers are fine")
print("Please think of a number between {} and {}".format(low, high)) input("Press ENTER to start")
my_number = 837 guesses = 1 while low != high: print(f"\tGuessing in the range of {low} to {high}") guess = low + (high - low) // 2 low_or_high = input("is {0} the number? enter '0' for correct. " "{0} is higher or lower than the answer? " "enter '+' for higher, '-' for lower ".format(guess)) if low_or_high == '0': print(f"the number is {guess}") print(f"I guess {guesses} times") break elif low_or_high == '+': # guess is higher than the answer high = guess - 1 elif low_or_high == '-': # guess is lower than the answer low = guess + 1 else: print("Please enter '+', '-', '0'")
guesses = guesses + 1 else: print(f"You thought of the number {low}")
chosen_exit = '' while chosen_exit notin available_exits: chosen_exit = input("Please choose a direction: ").casefold() if chosen_exit == 'quit': print("Game over") break else: print("aren't you glad you got out of there")
list comprehensions and generator expressions
modules
each .py file created by you becomes a new python module
virtualenv venv
active venv
cd C:\Users\liucf\Documents\learning\Learn-Python-Programming-Masterclass Set-ExecutionPolicy Unrestricted -Scope Process .\.venv\Scripts\activate
deactivate deactivate
random module
1 2
import random answer = random.randint(1, 10)
def randint(self, a: int, b: int) -> int Return random integer in range [a, b], including both end points.
augmented assignment
guesses = 0 guesses = guesses + 1 guesses += 1
when binary operation(it take 2 operands to work on) and there is an assignment change to augmented assignment
in python, the augmented assignment form only evaluates the assignee(guesses in the example) once, so more efficient using an augmented assignment, it can perform the operation in-place where possible, modifying the original variable(not create a new one)
evaluating a variable basically consists of looking its value
python_program = """for i in range(10): print(i) """ print(python_program)
# def chr(__i: int) -> str # Return a Unicode string of one character with ordinal i; 0 <= i <= 0x10ffff. # 102 f # 111 o # 114 r # ... # for b in python_program.encode('utf-8'): # print(b, chr(b)) # print(python_program.encode('utf-8')) # b'for i in range(10):\nprint(i)\n'
# the code and been modified if new_hash.hexdigest() == original_hash.hexdigest(): print('the code has not changed') else: print('the code and been modified')
## wrong approche # for index, value in enumerate(data): # if value < min_valid or value > max_valid: # del data[index] # print(data)
#### for ordered list # process the low values in the list stop = 0 for index, value inenumerate(data): if value >= min_valid: stop = index break print(stop) # 2 del data[:stop] print(data) # [104, 105, 110, 120, 130, 130, 150, 160, 170, 183, 185, 187, 188, 191, 350, 360] # process the high values in the list
#### more efficient start = 0 for index inrange(len(data) - 1, -1, -1): print(index) if data[index] <= max_valid: start = index + 1 break print(start) del data[start:] print(data)
itarate backwards
1 2 3 4 5 6 7 8 9 10 11 12 13
#### for not sorted list data = [104,101,4,105,308,103,5, 107,100,306,106,102,108]
min_valid = 100 max_valid = 200
for index inrange(len(data) - 1, -1, -1): if data[index] < min_valid or data[index] > max_valid: # print(index, data) del data[index] ### [104, 101, 105, 103, 107, 100, 106, 102, 108] print(data)
data = [104,101,4,105,308,103,5, 107,100,306,106,102,108]
min_valid = 100 max_valid = 200
# for index in range(len(data) - 1, -1, -1): # if data[index] < min_valid or data[index] > max_valid: # # print(index, data) # del data[index] # ### [104, 101, 105, 103, 107, 100, 106, 102, 108] # print(data)
## more efficient top_index = len(data) - 1 for index, value inenumerate(reversed(data)): i = top_index - index # print(i) if value < min_valid or value > max_valid: print(i, data) del data[i] print(data)
s.append(x)
appends x to the end of the sequence (same as s[len(s):len(s)] = [x])
valid_choices = [] for i inrange(1, len(available_parts) + 1): valid_choices.append(str(i)) print(valid_choices) # ['1', '2', '3', '4', '5', '6']
while current_choice != '0': if current_choice in valid_choices:
index = int(current_choice) - 1 chosen_part = available_parts[index]
# remove method if chosen_part in computer_parts: print(f"Removing {current_choice}") computer_parts.remove(chosen_part) else: print(f"Adding {current_choice}") computer_parts.append(chosen_part) print(computer_parts) else: print("Please add options from the list below:")
for number, part inenumerate(available_parts): print(f"{number + 1}: {part}")
current_choice = input()
print(computer_parts)
s.reverse()
reverses the items of s in place
buildin method reversed()
Return a reverse iterator over the values of the given sequence.
data = [104,101,4,105,308,103,5, 107,100,306,106,102,108]
min_valid = 100 max_valid = 200
# for index in range(len(data) - 1, -1, -1): # if data[index] < min_valid or data[index] > max_valid: # # print(index, data) # del data[index] # ### [104, 101, 105, 103, 107, 100, 106, 102, 108] # print(data)
## more efficient top_index = len(data) - 1 for index, value inenumerate(reversed(data)): i = top_index - index # print(i) if value < min_valid or value > max_valid: print(i, data) del data[i] print(data)
list
list are mutalbe
list() function
Built-in mutable sequence. If no argument is given, the constructor creates a new empty list. The argument must be an iterable if specified.
for meal in menu: for index inrange(len(meal) - 1, -1, -1): if meal[index] == 'spam': del meal[index] print(meal)
for meal in menu: for item in meal: if item != 'spam': print(item, end=' ') print()
buildin function: enumerate()
class enumerate(Iterator[tuple[int, _T]], Generic[_T]) Return an enumerate object.
iterable an object supporting iteration The enumerate object yields pairs containing a count (from start, which defaults to zero) and a value yielded by the iterable argument. enumerate is useful for obtaining an indexed list: (0, seq[0]), (1, seq[1]), (2, seq[2]), …
1 2 3 4 5
# 0 a # 1 b # 2 c for index, character inenumerate("abc"): print(index, character)
1 2 3 4 5 6 7 8
# (0, 'a') # (1, 'b') # (2, 'c') for t inenumerate("abc"): print(t) index, character = t print(index) print(character)
list methods
sort()
def sort(self: list[SupportsRichComparisonT], *, key: None = None, reverse: bool = False) -> None Sort the list in ascending order and return None. The sort is in-place (i.e. the list itself is modified) and stable (i.e. the order of two equal elements is maintained). If a key function is given, apply it once to each list item and sort them, ascending or descending, according to their function values. The reverse flag can be set to sort in descending order. sort(self, *, key=None, reverse=False)
def sorted(__iterable: Iterable[SupportsRichComparisonT], *, key: None = None, reverse: bool = False) -> list[SupportsRichComparisonT] Return a new list containing all items from the iterable in ascending order. A custom key function can be supplied to customize the sort order, and the reverse flag can be set to request the result in descending order. sorted(__iterable, *, key=None, reverse=False)
1 2 3 4 5 6 7 8 9 10 11 12 13 14
pangram = "The quick brown fox jumps over the lazy dog"
albums = [("Welcome to my Nightmare", "Alice Cooper", 1975), ("Bad Company", "Bad Company", 1974), ("Nightflight", "Budgie", 1981), ("More Mayhem", "Emilda May", 2011), ("Ride the Lightning", "Meallica", 1984), ]
print(len(albums))
for album in albums: title, artist, year = album print(f"Album: {title}, Artist: {artist}, Year: {year}") print("Album: {0}, Artist: {1}, Year: {2}".format(title, artist, year))
### more efficient for title, artist, year in albums: print("Album: {0}, Artist: {1}, Year: {2}".format(title, artist, year))
albums = [ ("Welcome to my Nightmare", "Alice Cooper", 1975, [ (1, "Welcome to my Nightmare"), (2, "Devil's Food"), (3, "The Black Widow"), (4, "Some Folks"), (5, "Only Women Bleed"), ] ), ("Bad Company", "Bad Company", 1974, [ (1, "Can't Get Enough"), (2, "Rock Steady"), (3, "Ready for Love"), (4, "Don't Let Me Down"), (5, "Bad Company"), (6, "The Way I Choose"), (7, "Movin' On"), (8, "Seagull"), ] ), ("Nightflight", "Budgie", 1981, [ (1, "I Turned to Stone"), (2, "Keeping a Rendezvous"), (3, "Reaper of the Glory"), (4, "She Used Me Up"), ] ), ("More Mayhem", "Imelda May", 2011, [ (1, "Pulling the Rug"), (2, "Psycho"), (3, "Mayhem"), (4, "Kentish Town Waltz"), ] ), ]
for name, artist, year, songs in albums: print(f"Album: {name}, Artist: {artist}, Year: {year}") print("Songs: ") for index, song_name in songs: print(f"Song {index}: {song_name}")
print(albums[3]) # ('More Mayhem', 'Imelda May', 2011, [(1, 'Pulling the Rug'), (2, 'Psycho'), (3, 'Mayhem'), (4, 'Kentish Town Waltz')]) print(albums[3][3]) # [(1, 'Pulling the Rug'), (2, 'Psycho'), (3, 'Mayhem'), (4, 'Kentish Town Waltz')] print(albums[3][3][2]) # (3, 'Mayhem') print(albums[3][3][2][1]) # Mayhem
defis_palindrome_sentence(sentence): sentence_without = '' for character in sentence: ifstr(character).isalpha(): sentence_without += character return is_palindrome(sentence_without)
print(is_palindrome_sentence("Was it a car, or a cat, I saw?"))
positional argument
default parameter values
1 2 3 4 5 6 7 8 9 10 11 12 13 14
defbanner_text(text, screen_width=80): iflen(text) > screen_width - 4: # print("The text is too long to fit in the specified width") raise ValueError("String {0} is larger than specified width {1}" .format(text, screen_width)) if text == '*': print('*' * screen_width) else: output_string = '**{0}**'.format(text.center(screen_width -4)) print(output_string)
Don’t use spaces around the = sign when used to indicate a keyword argument, or when used to indicate a default value for an unannotated function parameter:
# Some ANSI escape sequences for colours and effects BLACK = '\u001b[30m' RED = '\u001b[31m' GREEN = '\u001b[32m' YELLOW = '\u001b[33m' BLUE = '\u001b[34m' MAGENTA = '\u001b[35m' CYAN = '\u001b[36m' WHITE = '\u001b[37m' RESET = '\u001b[0m'
# print(RED, "this will be in red") # print("and so is this") # print(RESET) # print("this is normal")
defcolour_print(text: str, *effects: str) -> None: """ Print `text` using the Ansi sequences to change colour, etc. :param text: the text to print :param effects: the effects we want, one of the constants defined at the start of this module """ effects_joined = ''.join(effects) output_string = "{0}{1}{2}".format(effects_joined, text, RESET) print(output_string)
colour_print("Hello, Blue", BLUE) colour_print("Hello, Underline and Red", UNDERLINE, RED)
positional/keyword argument
keyword argument: an argument preceded by an identifier (e.g. name=) in a function call or passed as a value in a dictionary preceded by **. For example, 3 and 5 are both keyword arguments in the following calls to complex():
positional argument: an argument that is not a keyword argument. Positional arguments can appear at the beginning of an argument list and/or be passed as elements of an iterable preceded by *. For example, 3 and 5 are both positional arguments in the following calls:
defbanner_text(text=' ', screen_width=80): iflen(text) > screen_width - 4: # print("The text is too long to fit in the specified width") raise ValueError("String {0} is larger than specified width {1}" .format(text, screen_width)) if text == '*': print('*' * screen_width) else: output_string = '**{0}**'.format(text.center(screen_width -4)) print(output_string)
defbanner_text(text): screen_width = 80 iflen(text) > screen_width -4: # print("The text is too long to fit in the specified width") raise ValueError("String {0} is larger than specified width {1}" .format(text, screen_width)) if text == '*': print('*' * screen_width) else: output_string = '**{0}**'.format(text.center(screen_width -4)) print(output_string)
exception ValueError Raised when an operation or function receives an argument that has the right type but an inappropriate value, and the situation is not described by a more precise exception such as IndexError.
return statement
1 2 3 4 5 6 7 8 9 10
defget_integer(prompt): whileTrue: temp = input(prompt) if temp.isnumeric(): returnint(temp) # else: # print("Please enter a number") print("Please enter a number")
guess = get_integer("Please guess the number: ")
return None
1 2 3 4 5 6
defmultiply(x, y): result = x * y
answer = multiply(10.5, 4) print(answer) # None
documentation for functions
python pep docstring
pycharm -> ctrl + q
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
defget_integer(prompt): """ Get an integer form Standard Input (stdin). The function will continue looping, and prompting the user, until a valid `int` is entered :param prompt: The String that the user will see, when they are prompted to enter to value :return: The integer thar the user enters """ whileTrue: temp = input(prompt) if temp.isnumeric(): returnint(temp) else: print("Please enter a number")
print(get_integer.__doc__) help(get_integer)
function annotations and type hints
def fibonacci(n: int) -> int Return the n th Fibonacci number, for positive n.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
deffibonacci(n: int) -> int: """ Return the `n` th Fibonacci number, for positive `n`. """ if0 <= n <= 1: return n
n_minus1, n_minus2 = 1, 0
result = None for f inrange(n - 1): result = n_minus2 + n_minus1 n_minus2 = n_minus1 n_minus1 = result
return result
1 2 3
defmultiply(x: float, y: float) -> float: result = x * y return result
When combining an argument annotation with a default value, however, do use spaces around the = sign:
defbanner_text(text: str = ' ', screen_width: int = 80) -> None: iflen(text) > screen_width - 4: # print("The text is too long to fit in the specified width") raise ValueError("String {0} is larger than specified width {1}" .format(text, screen_width)) if text == '*': print('*' * screen_width) else: output_string = '**{0}**'.format(text.center(screen_width -4)) print(output_string)
section 5: dictionaries and sets
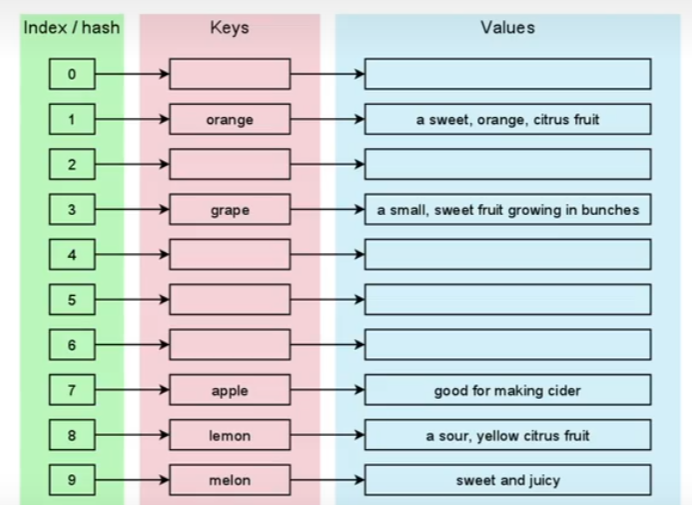
dictionary
a collection of values, that are stored using a key
Mapping Types — dict A mapping object maps hashable values to arbitrary objects. Mappings are mutable objects. There is currently only one standard mapping type, the dictionary
dictionaries are indexed by keys, which can be any immutable type; strings and numbers can always be keys. Tuples can be used as keys if they contain only strings, numbers, or tuples; if a tuple contains any mutable object either directly or indirectly, it cannot be used as a key. You can’t use lists as keys, since lists can be modified in place using index assignments, slice assignments, or methods like append() and extend().
hashable: an object is hashable if it has a hash value that doesn’t change during its lifetime and can be compared to other objects. In practice, it means that to be hashable objects need methods __hash__() and __eq__() .
# def get(self, __key: _KT) -> _VT | None # Return the value for key if key is in the dictionary, else default. learner = vehicles.get('er5') # 'Kawasaki ER5' learner = vehicles.get('ER5') # None print(learner)
data = [ ('orange', 'a sweet, orange, citrus fruit'), ('apple', 'good for making cider'), ('lemon', 'a sour, yellow citrus fruit'), ('grape', 'a small, sweet fruit growing in bunches'), ('melon', 'sweet and juicy'), ] # def ord(__c: str | bytes | bytearray) -> int # Return the Unicode code point for a one-character string # print(ord('a')) # 97
# for key in vehicles: # print(key, vehicles[key], sep=', ')
## more efficient # def items(self) -> dict_items[_KT, _VT] # D.items() -> a set-like object providing a view on D's items for key, value in vehicles.items(): print(key, value, sep=', ')
# dream, Honda 250T # er5, Kawasaki ER5 # can-am, Bombardier Can-Am 250 for key, value in vehicles.items(): print(key, value, sep=', ')
# KeyError: 'notexist' # del vehicles['notexist']
# vehicles.pop('f1') # KeyError: 'f1' # D.pop(k[,d]) -> v, remove specified key and return the corresponding value. # If the key is not found, return the default if given; otherwise, raise a KeyError. result = vehicles.pop('f1', None) print(result)
current_choice = None while current_choice != '0': if current_choice in available_parts: # if current_choice in available_parts.keys(): chosen_part = available_parts[current_choice] print(f"Adding {chosen_part}") else: print("Please add options from the list") for index, part in available_parts.items(): print(index, part, sep=': ') print("0: to finish")
for ingredient, required_quantity in ingredients.items(): quantity_in_pantry = pantry.get(ingredient, 0) if quantity_in_pantry >= required_quantity: print(f"\t{ingredient} OK") pantry[ingredient] -= required_quantity else: quantity_to_buy = required_quantity - quantity_in_pantry print(f"\tYou need to buy {quantity_to_buy} of {ingredient}") add_shopping_item(items_to_buy, ingredient, quantity_to_buy) if ingredient in pantry: pantry[ingredient] -= 0
for key, value in pantry.items(): print(f"there is {key} of {value}") for key, value in items_to_buy.items(): print(f"buy {key} of {value}")
dict methods
def fromkeys(cls, __iterable: Iterable[_T], __value: None = None) -> dict[_T, Any | None] Create a new dictionary with keys from iterable and values set to value.
keys = d.keys() print(keys, type(keys)) # dict_keys([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]) <class 'dict_keys'> # for item in d: for item in d.keys(): print(item)
update()
update([other]) Update the dictionary with the key/value pairs from other, overwriting existing keys. Return None.
update() accepts either another dictionary object or an iterable of key/value pairs (as tuples or other iterables of length two). If keyword arguments are specified, the dictionary is then updated with those key/value pairs: d.update(red=1, blue=2).
d2 = { 7: 'lucky seven', 10: 'tem', 3: 'this is the new three', }
d.update(d2)
# 0 zero # 1 one # 2 two # 3 this is the new three ## changed # 4 four # 5 five # 6 six # 7 lucky seven ## changed # 8 eight # 9 nine # 10 tem ## new for key, value in d.items(): print(key, value)
print()
# 0 chicken ## changed # 1 spam ## changed # 2 egg ## changed # 3 bread ## changed # 4 lemon ## changed # 5 five # 6 six # 7 lucky seven # 8 eight # 9 nine # 10 tem d.update(enumerate(pantry_items)) for key, value in d.items(): print(key, value)
values() keys() items()
Dictionary view objects The objects returned by dict.keys(), dict.values() and dict.items() are view objects. They provide a dynamic view on the dictionary’s entries, which means that when the dictionary changes, the view reflects these changes.
Dictionary views can be iterated over to yield their respective data, and support membership tests:
## not efficient keys = list(d.keys()) values = list(d.values()) if"four"in values: index = values.index("four") key = keys[index] print(f"{d[key]} was found with the key {key}")
print()
for key, value in d.items(): if value == "four": print(f"{d[key]} was found with the key {key}")
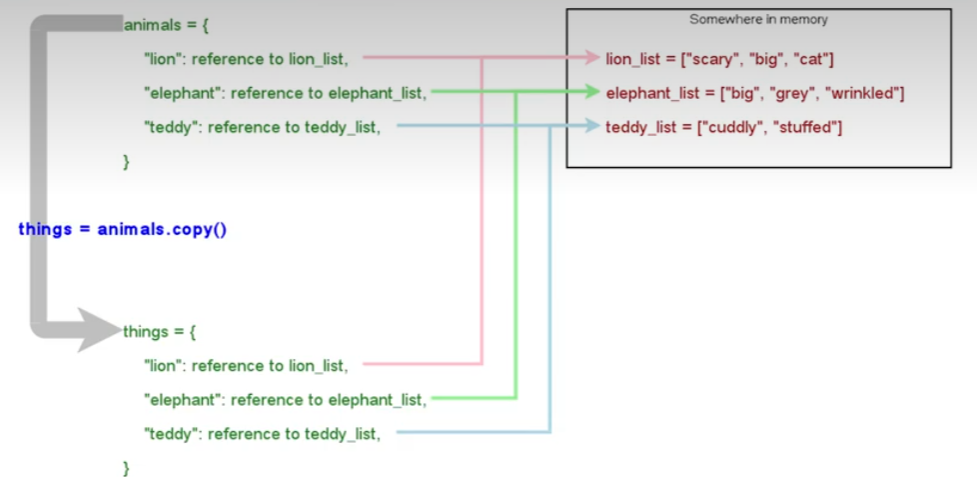
animals['teddy'].append('added via `animals`') things['teddy'].append('added via `things`') print(things['teddy']) # ['cuddly', 'stuffed', 'toy', 'added via `animals`', 'added via `things`'] print(animals['teddy']) # ['cuddly', 'stuffed', 'toy', 'added via `animals`', 'added via `things`']
# sheep # hen # cow # goat # horse for animal in farm_animals: print(animal)
# goat # cow # sheep # hen # horse for animal in farm_animals: print(animal)
# print('Indexing a set is not possible') ## Class 'set' does not define '__getitem__', so the '[]' operator cannot be used on its instances # goat = farm_animals[3] # TypeError: 'set' object is not subscriptable # print(goat)
# if choose in '12345': ## have bug if '123' # if choose in list('12345'): ## set more effecient # print(set("12345")) # {'4', '2', '5', '1', '3'} # if choose in set('12345'): if choose in {'4', '2', '5', '1', '3'}: print(options[int(choose) - 1]) else: print("Please choose your option from the list below:") for option in options: print(option) choose = input() else: print("Game over")
# def remove(self, __element: _T) -> None # Remove an element from a set; it must be a member. # If the element is not a member, raise a KeyError small_ints.remove(10) small_ints.discard(11) print(small_ints) # {0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 12, 13, 14, 15, 16, 17, 18, 19, 20}
# def discard(self, __element: _T) -> None # Remove an element from a set if it is a member. # Unlike set.remove(), the discard() method does not raise an exception when an element is missing from the set. small_ints.discard(99) print(small_ints)
for patient in trial_patients: prescription = patients[patient] if warfarin in prescription: prescription.remove(warfarin) prescription.add(edoxaban) else: print('dont have warfarin') prescription.add(edoxaban)
## more efficient for patient in trial_patients: prescription = patients[patient] try: prescription.remove(warfarin) prescription.add(edoxaban) except KeyError: print('dont have warfarin') prescription.add(edoxaban)
## create a list of unique colours, keeping the order they appear # def fromkeys(cls, # __iterable: Iterable[_T], # __value: None = None) -> dict[_T, Any | None] # Create a new dictionary with keys from iterable and values set to value # print(dict.fromkeys(data)) # {'blue': None, 'red': None, 'green': None, 'white': None} unique_data = list(dict.fromkeys(data)) # ['blue', 'red', 'green', 'white'] print(unique_data)