python web scraping
http
uri url
URL stands for Uniform Resource Locator. A URL is nothing more than the address of a given unique resource on the Web. In theory, each valid URL points to a unique resource.

http https
tls/ssl
Transport Layer Security (TLS) is a cryptographic protocol designed to provide communications security over a computer network. The protocol is widely used in applications such as email, instant messaging, and voice over IP, but its use in securing HTTPS remains the most publicly visible.
TLS builds on the now-deprecated SSL (Secure Sockets Layer) specifications (1994, 1995, 1996)
chrome developer tool
network
Status. The HTTP response code.
Type. The resource type.
Initiator. What caused a resource to be requested. Clicking a link in the Initiator column takes you to the source code that caused the request.
Time. How long the request took.
Waterfall. A graphical representation of the different stages of the request. Hover over a Waterfall to see a breakdown.
detail
The Headers tab is shown. Use this tab to inspect HTTP headers.
the Preview tab. A basic rendering of the HTML is shown.
the Response tab. The HTML source code is shown.
the Timing tab. A breakdown of the network activity for this resource is shown.
http request
header
content-type: internet media type MIME
HTML –> text/html
GIF –> image/gif
JSON –> application/json
xml –> text/xml
form file –> multipart/form-data
form data –> application/x-www-form-urlencoded
http response
Information responses
100 Continue
This interim response indicates that the client should continue the request or ignore the response if the request is already finished.
101 Switching Protocols
This code is sent in response to an Upgrade request header from the client and indicates the protocol the server is switching to.
102 Processing (WebDAV)
This code indicates that the server has received and is processing the request, but no response is available yet.
103 Early Hints
This status code is primarily intended to be used with the Link header, letting the user agent start preloading resources while the server prepares a response or preconnect to an origin from which the page will need resources.
Successful responses
200 OK
The request succeeded. The result meaning of “success” depends on the HTTP method:
GET: The resource has been fetched and transmitted in the message body.
HEAD: The representation headers are included in the response without any message body.
PUT or POST: The resource describing the result of the action is transmitted in the message body.
TRACE: The message body contains the request message as received by the server.
201 Created
The request succeeded, and a new resource was created as a result. This is typically the response sent after POST requests, or some PUT requests.
202 Accepted
The request has been received but not yet acted upon. It is noncommittal, since there is no way in HTTP to later send an asynchronous response indicating the outcome of the request. It is intended for cases where another process or server handles the request, or for batch processing.
203 Non-Authoritative Information
This response code means the returned metadata is not exactly the same as is available from the origin server, but is collected from a local or a third-party copy. This is mostly used for mirrors or backups of another resource. Except for that specific case, the 200 OK response is preferred to this status.
204 No Content
There is no content to send for this request, but the headers may be useful. The user agent may update its cached headers for this resource with the new ones.
205 Reset Content
Tells the user agent to reset the document which sent this request.
206 Partial Content
This response code is used when the Range header is sent from the client to request only part of a resource.
207 Multi-Status (WebDAV)
Conveys information about multiple resources, for situations where multiple status codes might be appropriate.
208 Already Reported (WebDAV)
Used inside a dav:propstat response element to avoid repeatedly enumerating the internal members of multiple bindings to the same collection.
226 IM Used (HTTP Delta encoding)
The server has fulfilled a GET request for the resource, and the response is a representation of the result of one or more instance-manipulations applied to the current instance.
Redirection messages
300 Multiple Choices
The request has more than one possible response. The user agent or user should choose one of them. (There is no standardized way of choosing one of the responses, but HTML links to the possibilities are recommended so the user can pick.)
301 Moved Permanently
The URL of the requested resource has been changed permanently. The new URL is given in the response.
302 Found
This response code means that the URI of requested resource has been changed temporarily. Further changes in the URI might be made in the future. Therefore, this same URI should be used by the client in future requests.
303 See Other
The server sent this response to direct the client to get the requested resource at another URI with a GET request.
304 Not Modified
This is used for caching purposes. It tells the client that the response has not been modified, so the client can continue to use the same cached version of the response.
305 Use Proxy Deprecated
Defined in a previous version of the HTTP specification to indicate that a requested response must be accessed by a proxy. It has been deprecated due to security concerns regarding in-band configuration of a proxy.
306 unused
This response code is no longer used; it is just reserved. It was used in a previous version of the HTTP/1.1 specification.
307 Temporary Redirect
The server sends this response to direct the client to get the requested resource at another URI with the same method that was used in the prior request. This has the same semantics as the 302 Found HTTP response code, with the exception that the user agent must not change the HTTP method used: if a POST was used in the first request, a POST must be used in the second request.
308 Permanent Redirect
This means that the resource is now permanently located at another URI, specified by the Location: HTTP Response header. This has the same semantics as the 301 Moved Permanently HTTP response code, with the exception that the user agent must not change the HTTP method used: if a POST was used in the first request, a POST must be used in the second request.
Client error responses
400 Bad Request
The server cannot or will not process the request due to something that is perceived to be a client error (e.g., malformed request syntax, invalid request message framing, or deceptive request routing).
401 Unauthorized
Although the HTTP standard specifies “unauthorized”, semantically this response means “unauthenticated”. That is, the client must authenticate itself to get the requested response.
402 Payment Required Experimental
This response code is reserved for future use. The initial aim for creating this code was using it for digital payment systems, however this status code is used very rarely and no standard convention exists.
403 Forbidden
The client does not have access rights to the content; that is, it is unauthorized, so the server is refusing to give the requested resource. Unlike 401 Unauthorized, the client’s identity is known to the server.
404 Not Found
The server cannot find the requested resource. In the browser, this means the URL is not recognized. In an API, this can also mean that the endpoint is valid but the resource itself does not exist. Servers may also send this response instead of 403 Forbidden to hide the existence of a resource from an unauthorized client. This response code is probably the most well known due to its frequent occurrence on the web.
405 Method Not Allowed
The request method is known by the server but is not supported by the target resource. For example, an API may not allow calling DELETE to remove a resource.
406 Not Acceptable
This response is sent when the web server, after performing server-driven content negotiation, doesn’t find any content that conforms to the criteria given by the user agent.
407 Proxy Authentication Required
This is similar to 401 Unauthorized but authentication is needed to be done by a proxy.
408 Request Timeout
This response is sent on an idle connection by some servers, even without any previous request by the client. It means that the server would like to shut down this unused connection. This response is used much more since some browsers, like Chrome, Firefox 27+, or IE9, use HTTP pre-connection mechanisms to speed up surfing. Also note that some servers merely shut down the connection without sending this message.
409 Conflict
This response is sent when a request conflicts with the current state of the server.
410 Gone
This response is sent when the requested content has been permanently deleted from server, with no forwarding address. Clients are expected to remove their caches and links to the resource. The HTTP specification intends this status code to be used for “limited-time, promotional services”. APIs should not feel compelled to indicate resources that have been deleted with this status code.
411 Length Required
Server rejected the request because the Content-Length header field is not defined and the server requires it.
412 Precondition Failed
The client has indicated preconditions in its headers which the server does not meet.
413 Payload Too Large
Request entity is larger than limits defined by server. The server might close the connection or return an Retry-After header field.
414 URI Too Long
The URI requested by the client is longer than the server is willing to interpret.
415 Unsupported Media Type
The media format of the requested data is not supported by the server, so the server is rejecting the request.
416 Range Not Satisfiable
The range specified by the Range header field in the request cannot be fulfilled. It’s possible that the range is outside the size of the target URI’s data.
417 Expectation Failed
This response code means the expectation indicated by the Expect request header field cannot be met by the server.
418 I’m a teapot
The server refuses the attempt to brew coffee with a teapot.
421 Misdirected Request
The request was directed at a server that is not able to produce a response. This can be sent by a server that is not configured to produce responses for the combination of scheme and authority that are included in the request URI.
422 Unprocessable Content (WebDAV)
The request was well-formed but was unable to be followed due to semantic errors.
423 Locked (WebDAV)
The resource that is being accessed is locked.
424 Failed Dependency (WebDAV)
The request failed due to failure of a previous request.
425 Too Early Experimental
Indicates that the server is unwilling to risk processing a request that might be replayed.
426 Upgrade Required
The server refuses to perform the request using the current protocol but might be willing to do so after the client upgrades to a different protocol. The server sends an Upgrade header in a 426 response to indicate the required protocol(s).
428 Precondition Required
The origin server requires the request to be conditional. This response is intended to prevent the ‘lost update’ problem, where a client GETs a resource’s state, modifies it and PUTs it back to the server, when meanwhile a third party has modified the state on the server, leading to a conflict.
429 Too Many Requests
The user has sent too many requests in a given amount of time (“rate limiting”).
431 Request Header Fields Too Large
The server is unwilling to process the request because its header fields are too large. The request may be resubmitted after reducing the size of the request header fields.
451 Unavailable For Legal Reasons
The user agent requested a resource that cannot legally be provided, such as a web page censored by a government.
Server error responses
500 Internal Server Error
The server has encountered a situation it does not know how to handle.
501 Not Implemented
The request method is not supported by the server and cannot be handled. The only methods that servers are required to support (and therefore that must not return this code) are GET and HEAD.
502 Bad Gateway
This error response means that the server, while working as a gateway to get a response needed to handle the request, got an invalid response.
503 Service Unavailable
The server is not ready to handle the request. Common causes are a server that is down for maintenance or that is overloaded. Note that together with this response, a user-friendly page explaining the problem should be sent. This response should be used for temporary conditions and the Retry-After HTTP header should, if possible, contain the estimated time before the recovery of the service. The webmaster must also take care about the caching-related headers that are sent along with this response, as these temporary condition responses should usually not be cached.
504 Gateway Timeout
This error response is given when the server is acting as a gateway and cannot get a response in time.
505 HTTP Version Not Supported
The HTTP version used in the request is not supported by the server.
506 Variant Also Negotiates
The server has an internal configuration error: the chosen variant resource is configured to engage in transparent content negotiation itself, and is therefore not a proper end point in the negotiation process.
507 Insufficient Storage (WebDAV)
The method could not be performed on the resource because the server is unable to store the representation needed to successfully complete the request.
508 Loop Detected (WebDAV)
The server detected an infinite loop while processing the request.
510 Not Extended
Further extensions to the request are required for the server to fulfill it.
511 Network Authentication Required
Indicates that the client needs to authenticate to gain network access.
response header
content-type:
application/x-javascript –> javascirpt file
web 基础
html css js
html dom
document object model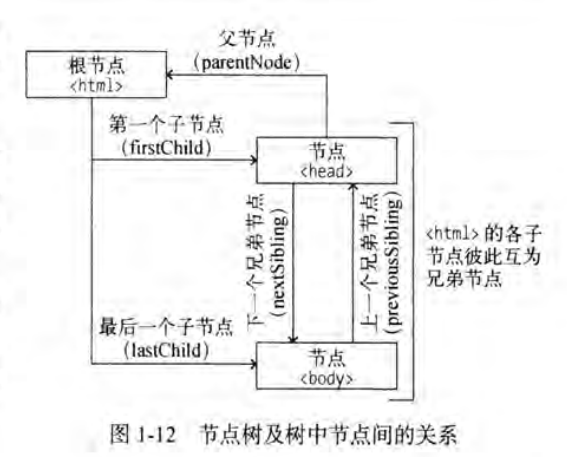
css selector
| Selector | Example | Example description |
|---|---|---|
| .class | .intro | Selects all elements with class=”intro” |
| .class1.class2 | .name1.name2 | Selects all elements with both name1 and name2 set within its class attribute |
| .class1 .class2 | .name1 .name2 | Selects all elements with name2 that is a descendant of an element with name1 |
| #id | #firstname | Selects the element with id=”firstname” |
| * | * | Selects all elements |
| element | p | Selects all <p> elements |
| element.class | p.intro | Selects all <p> elements with class=”intro” |
| element,element | div, p | Selects all <div> elements and all <p> elements |
| element element | div p | Selects all <p> elements inside <div> elements |
| element>element | div > p | Selects all <p> elements where the parent is a <div> element |
| element+element | div + p | Selects the first <p> element that is placed immediately after <div> elements |
| element1~element2 | p ~ ul | Selects every <ul> element that is preceded by a <p> element |
| [attribute] | [target] | Selects all elements with a target attribute |
| [attribute=value] | [target=”_blank”] | Selects all elements with target=”_blank” |
| [attribute~=value] | [title~=”flower”] | Selects all elements with a title attribute containing the word “flower” |
| [attribute|=value] | [lang|=”en”] | Selects all elements with a lang attribute value equal to “en” or starting with “en-“ |
| [attribute^=value] | a[href^=”https”] | Selects every <a> element whose href attribute value begins with “https” |
| [attribute$=value] | a[href$=”.pdf”] | Selects every <a> element whose href attribute value ends with “.pdf” |
| [attribute*=value] | a[href*=”w3schools”] | Selects every <a> element whose href attribute value contains the substring “w3schools” |
| :active | a:active | Selects the active link |
| ::after | p::after | Insert something after the content of each <p> element |
| ::before | p::before | Insert something before the content of each <p> element |
| :checked | input:checked | Selects every checked <input> element |
| :default | input:default | Selects the default <input> element |
| :disabled | input:disabled | Selects every disabled <input> element |
| :empty | p:empty | Selects every <p> element that has no children (including text nodes) |
| :enabled | input:enabled | Selects every enabled <input> element |
| :first-child | p:first-child | Selects every <p> element that is the first child of its parent |
| ::first-letter | p::first-letter | Selects the first letter of every <p> element |
| ::first-line | p::first-line | Selects the first line of every <p> element |
| :first-of-type | p:first-of-type | Selects every <p> element that is the first <p> element of its parent |
| :focus | input:focus | Selects the input element which has focus |
| :fullscreen | :fullscreen | Selects the element that is in full-screen mode |
| :hover | a:hover | Selects links on mouse over |
| :in-range | input:in-range | Selects input elements with a value within a specified range |
| :indeterminate | input:indeterminate | Selects input elements that are in an indeterminate state |
| :invalid | input:invalid | Selects all input elements with an invalid value |
| :lang(language) | p:lang(it) | Selects every <p> element with a lang attribute equal to “it” (Italian) |
| :last-child | p:last-child | Selects every <p> element that is the last child of its parent |
| :last-of-type | p:last-of-type | Selects every <p> element that is the last <p> element of its parent |
| :link | a:link | Selects all unvisited links |
| ::marker | ::marker | Selects the markers of list items |
| :not(selector) | :not(p) | Selects every element that is not a <p> element |
| :nth-child(n) | p:nth-child(2) | Selects every <p> element that is the second child of its parent |
| :nth-last-child(n) | p:nth-last-child(2) | Selects every <p> element that is the second child of its parent, counting from the last child |
| :nth-last-of-type(n) | p:nth-last-of-type(2) | Selects every <p> element that is the second <p> element of its parent, counting from the last child |
| :nth-of-type(n) | p:nth-of-type(2) | Selects every <p> element that is the second <p> element of its parent |
| :only-of-type | p:only-of-type | Selects every <p> element that is the only <p> element of its parent |
| :only-child | p:only-child | Selects every <p> element that is the only child of its parent |
| :optional | input:optional | Selects input elements with no “required” attribute |
| :out-of-range | input:out-of-range | Selects input elements with a value outside a specified range |
| ::placeholder | input::placeholder | Selects input elements with the “placeholder” attribute specified |
| :read-only | input:read-only | Selects input elements with the “readonly” attribute specified |
| :read-write | input:read-write | Selects input elements with the “readonly” attribute NOT specified |
| :required | input:required | Selects input elements with the “required” attribute specified |
| :root | :root | Selects the document’s root element |
| ::selection | ::selection | Selects the portion of an element that is selected by a user |
| :target | #news:target | Selects the current active #news element (clicked on a URL containing that anchor name) |
| :valid | input:valid | Selects all input elements with a valid value |
| :visited | a:visited | Selects all visited links |
1 | from urllib.request import urlopen |
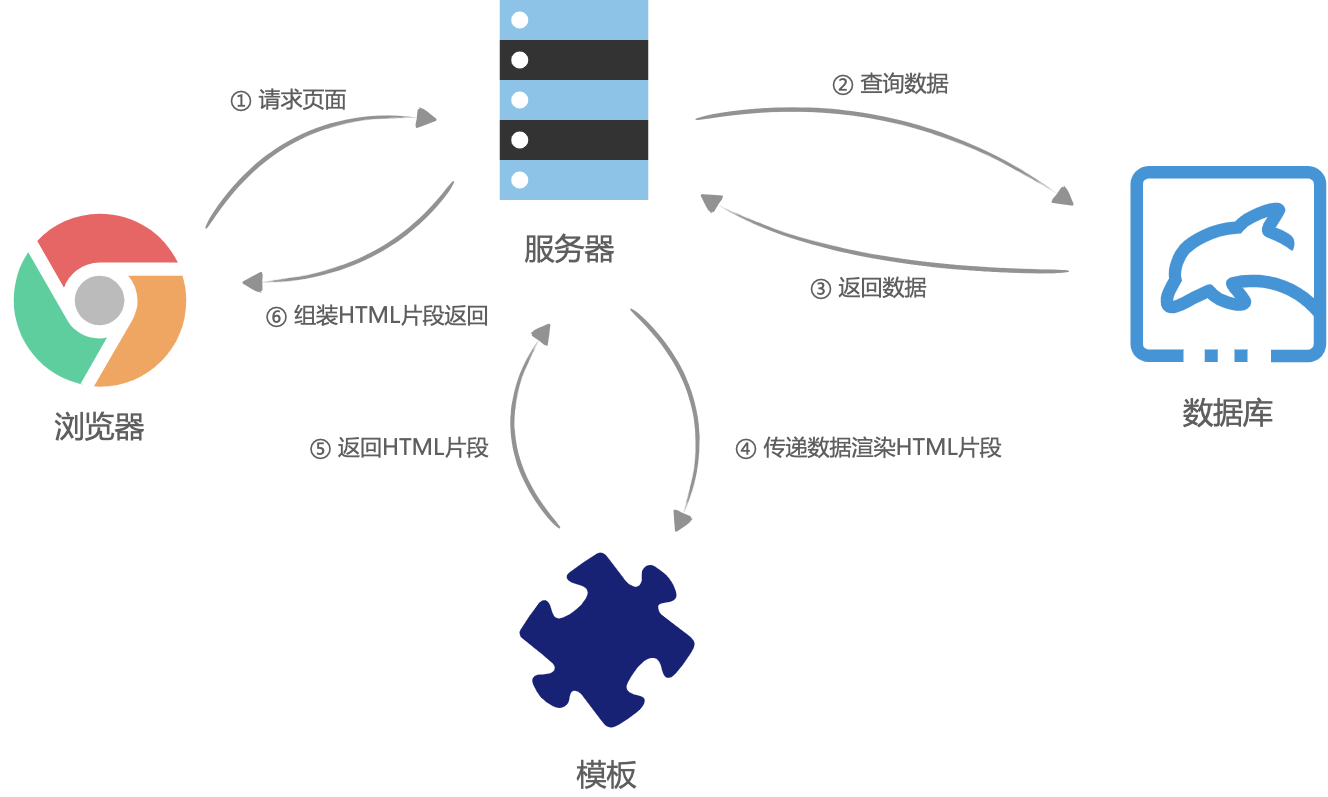
服务器渲染
在没有AJAX的时候,也就是web1.0时代,几乎所有应用都是服务端渲染(此时服务器渲染非现在的服务器渲染),那个时候的页面渲染大概是这样的,浏览器请求页面URL,然后服务器接收到请求之后,到数据库查询数据,将数据丢到后端的组件模板(php、asp、jsp等)中,并渲染成HTML片段,接着服务器在组装这些HTML片段,组成一个完整的HTML,最后返回给浏览器,这个时候,浏览器已经拿到了一个完整的被服务器动态组装出来的HTML文本,然后将HTML渲染到页面中
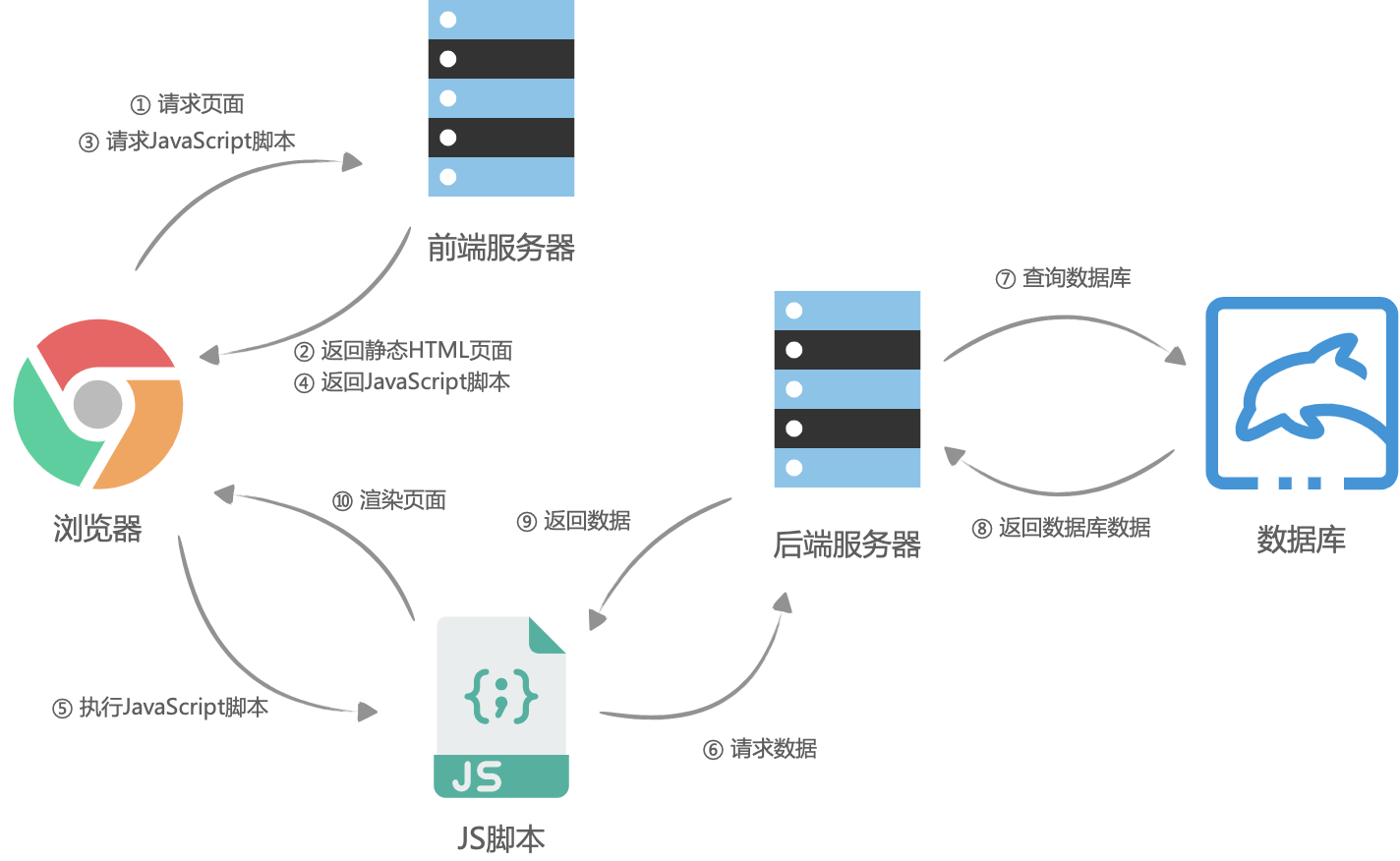
客户端渲染
前后端分离之后,网页开始被当成了独立的应用程序(SPA,Single Page Application),前端团队接管了所有页面渲染的事,后端团队只负责提供所有数据查询与处理的API,大体流程是这样的:首先浏览器请求URL,前端服务器直接返回一个空的静态HTML文件(不需要任何查数据库和模板组装),这个HTML文件中加载了很多渲染页面需要的 JavaScript 脚本和 CSS 样式表,浏览器拿到 HTML 文件后开始加载脚本和样式表,并且执行脚本,这个时候脚本请求后端服务提供的API,获取数据,获取完成后将数据通过JavaScript脚本动态的将数据渲染到页面中,完成页面显示。
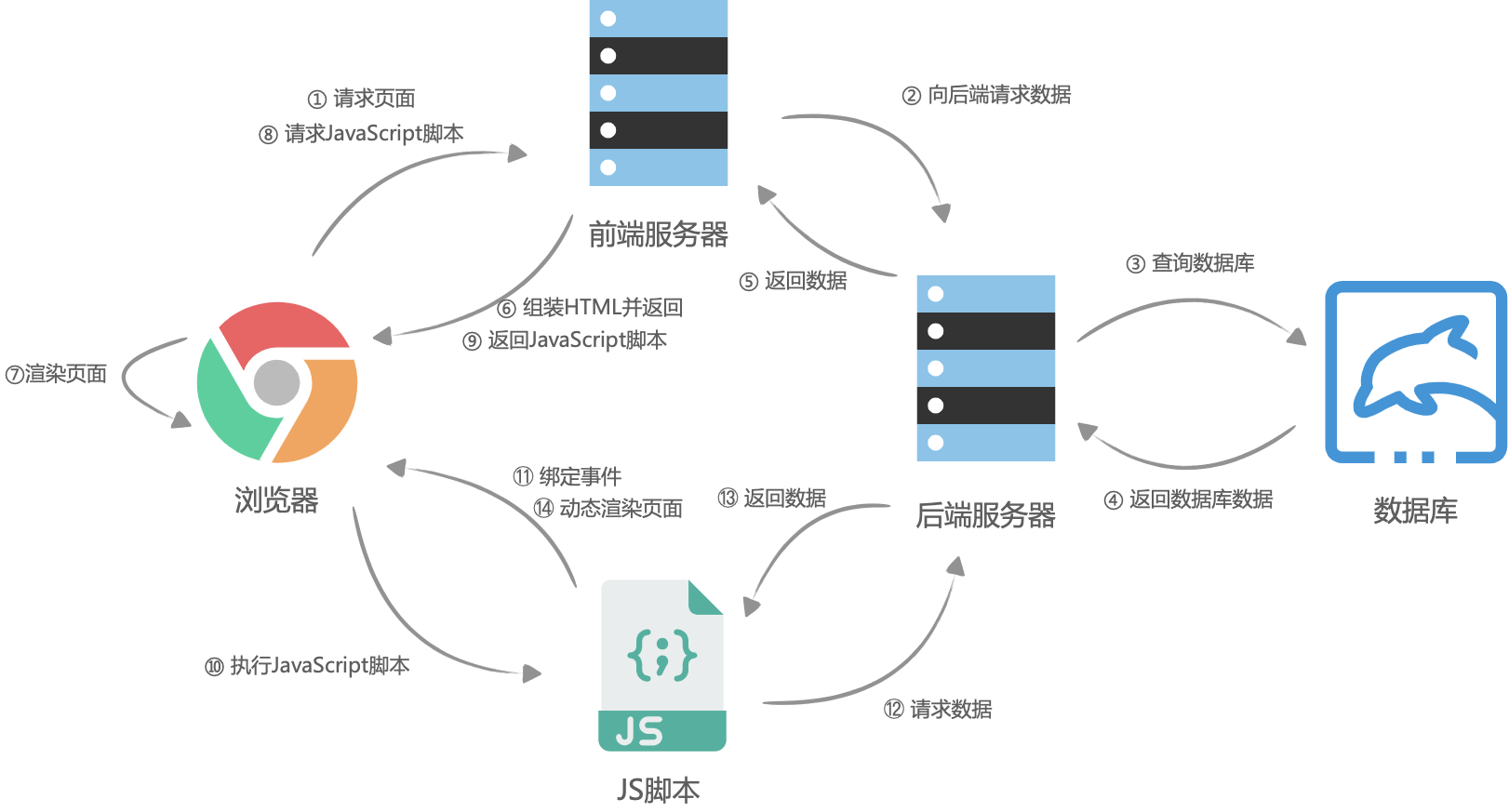
服务端渲染
服务端渲染。大体流程与客户端渲染有些相似,首先是浏览器请求URL,前端服务器接收到URL请求之后,根据不同的URL,前端服务器向后端服务器请求数据,请求完成后,前端服务器会组装一个携带了具体数据的HTML文本,并且返回给浏览器,浏览器得到HTML之后开始渲染页面,同时,浏览器加载并执行 JavaScript 脚本,给页面上的元素绑定事件,让页面变得可交互,当用户与浏览器页面进行交互,如跳转到下一个页面时,浏览器会执行 JavaScript 脚本,向后端服务器请求数据,获取完数据之后再次执行 JavaScript 代码动态渲染页面。
响应头
- cookie
- token
请求头
- user-agent
- referer请求从那一页面来的(即上一页面地址)
- cookie
GET
POST
1 | import requests |
1 | import requests |
string
the most common string methods
- s.lower(), s.upper() – returns the lowercase or uppercase version of the string
- s.strip() – returns a string with whitespace removed from the start and end
- s.isalpha()/s.isdigit()/s.isspace()… – tests if all the string chars are in the various character classes
- s.startswith(‘other’), s.endswith(‘other’) – tests if the string starts or ends with the given other string
- s.find(‘other’) – searches for the given other string (not a regular expression) within s, and returns the first index where it begins or -1 if not found
- s.replace(‘old’, ‘new’) – returns a string where all occurrences of ‘old’ have been replaced by ‘new’
- s.split(‘delim’) – returns a list of substrings separated by the given delimiter. The delimiter is not a regular expression, it’s just text. ‘aaa,bbb,ccc’.split(‘,’) -> [‘aaa’, ‘bbb’, ‘ccc’]. As a convenient special case s.split() (with no arguments) splits on all whitespace chars.
- s.join(list) – opposite of split(), joins the elements in the given list together using the string as the delimiter. e.g. ‘—‘.join([‘aaa’, ‘bbb’, ‘ccc’]) -> aaa—bbb—ccc
str.rsplit(sep=None, maxsplit=-1)
Return a list of the words in the string, using sep as the delimiter string. If maxsplit is given, at most maxsplit splits are done, the rightmost ones. If sep is not specified or None, any whitespace string is a separator. Except for splitting from the right, rsplit() behaves like split() which is described in detail below.
str.split(sep=None, maxsplit=- 1)
Return a list of the words in the string, using sep as the delimiter string. If maxsplit is given, at most maxsplit splits are done (thus, the list will have at most maxsplit+1 elements). If maxsplit is not specified or -1, then there is no limit on the number of splits (all possible splits are made).
If sep is given, consecutive delimiters are not grouped together and are deemed to delimit empty strings (for example, '1,,2'.split(',') returns ['1', '', '2']). The sep argument may consist of multiple characters (for example, '1<>2<>3'.split('<>') returns['1', '2', '3']). Splitting an empty string with a specified separator returns [‘’].
Strings (Unicode vs bytes)
To convert a regular Python string to bytes, call the encode() method on the string. Going the other direction, the byte string decode() method converts encoded plain bytes to a unicode string:
1 | > ustring = 'A unicode \u018e string \xf1' |
urllib
1 | from urllib import request |
urllib.request headers
1 | from urllib import request |
urllib.parse.urlencode
1 | # 对URL编码 |
example: baidutieba
1 | from urllib import request, parse |
requests
import requests
headers
1 | headers = { |
get
1 | params = { |
post
1 | data = { |
response
1 | resp = requests.get(url) |
解析
re
- Method/Attribute Purpose
match()
Determine if the RE matches at the beginning of the string.
search()
Scan through a string, looking for any location where this RE matches.
findall()
Find all substrings where the RE matches, and returns them as a list.
finditer()
Find all substrings where the RE matches, and returns them as an iterator.
- Match object instances
group()
Return the string matched by the RE
Method/Attribute Purpose
start()
Return the starting position of the match
end()
Return the ending position of the match
span()
Return a tuple containing the (start, end) positions of the match
- Compilation flags let you modify some aspects of how regular expressions work. Flags are available in the re module under two names, a long name such as IGNORECASE and a short, one-letter form such as I
re.S
re.DOTALL
Makes the ‘.’ special character match any character at all, including a newline; without this flag, ‘.’ will match anything except a newline.
- named groups: instead of referring to them by numbers, groups can be referenced by a name.
The syntax for a named group is one of the Python-specific extensions:(?P<name>...). name is, obviously, the name of the group.
The match object methods that deal with capturing groups all accept either integers that refer to the group by number or strings that contain the desired group’s name.
1 | p = re.compile(r'(?P<word>\b\w+\b)') |
1 | import re |
效率不高
1 | # iterator |
1 | # match object group() return the first result |
正则预加载
1 | obj = re.compile(r"\d+") |
提取字符段
1 | # 提取字符段 |
Python 3 the file must be opened in untranslated text mode with the parameters 'w', newline=''(empty string) or it will write \r\r\n on Windows, where the default text mode will translate each \n into \r\n.
1 | import csv |
re
1 | import re |
“?”
1 | html_content = """ |
group
1 | html = 'A B C D' |
example
1 | import re |
example: maoyan.com
1 | import csv |
1 | import csv |
example: baidu image
1 | import os.path |
lxml xpath
1 | <html> |
For getting the text inside the <p> tag,
XPath : html/body/p/text()
Result : This is the first paragraph
For getting a value inside the <href> attribute in the anchor or <a> tag,
XPath : html/body/a/@href
Result: www.example.com
For getting the value inside the second <h2> tag,
XPath : html/body/h2[2]/text()
Result: Hello World
注意//h1/text()结果是个数组
- Specifying a complete path with / as separator
title = root.xpath('/html/body/div/div/div[2]/h1')
is the full path to my blog title. Notice how we request the 2nd element of the third set of div elements using div[2] – xpath arrays are one-based, not zero-based.
- Specifying a path with wildcards using //
This expression also finds the title but the preamble of /html/body/div/div is absorbed by the // wildcard match:
title = root.xpath('//div[2]/h1')
- Specifying an element by attribute
We can select elements which have particular attribute values:
tagcloud = root.xpath('//*[@class="tagcloud"]')
this selects the tag cloud on my blog by selecting elements which having the class attribute “tagcloud”.
- Select via a parent or sibling relationship
Sometimes we want to select elements by their relationship to another element, for example:
subtitle = root.xpath(‘//h1[contains(@class,”header_title”)]/../h2’)
this selects the h1 title of my blog (SomeBeans) then navigates to the parent with .. and selects the sibling h2 element (the subtitle “the makings of a small casserole”).
The same effect can be achieved with the following-sibling keyword:
subtitle = root.xpath(‘//h1[contains(@class,”header_title”)]/following-sibling::h2’)
1 | from lxml import etree |
The fromstring() function
The fromstring() function is the easiest way to parse a string:
some_xml_data = “
data “
root = etree.fromstring(some_xml_data)
print(root.tag)
root
etree.tostring(root)
b’data ‘
The XML() function
The XML() function behaves like the fromstring() function, but is commonly used to write XML literals right into the source:
There is also a corresponding function HTML() for HTML literals.
root = etree.HTML("<p>data</p>")
The parse() function
The parse() function is used to parse from files and file-like objects.
example
1 | from lxml import etree |
xpath
//tagname
at nay level of parent element//tagename[1]//tagname[@attributeName="value"]
contain()//tagname[contains(@attributeName,'value')]
starts-with()
and or//tagname[(expression 1)and(expression 2)]
get text//h1/text()
/
the children//
all the children within any level.
current..
parent*
any elements
css selector
xpath: /html/body/p
CSS selector: html > body > p
Basic CSS Selectors Cheatsheet
| Selector | Description | Example | Explanation |
|---|---|---|---|
| Tag Selector | Selects elements based on their tag name. | p | Selects all <p> elements. |
| Class Selector | Selects elements based on their class name. | .example | Selects all elements with the class name “example”. |
| ID Selector | Selects an element based on its ID. | #example | Selects the element with the ID “example”. |
| Attribute Selector | Selects elements based on their attribute and value. | [type=”text”] | Selects all elements with the attribute “type” and |
| Descendant Selector | Selects elements that are descendants of another element. | div p | Selects all <p> elements that are descendants of a <div> |
| Child Selector | Selects elements that are direct children of another element. | ul > li | Selects all <li> elements that are direct children of a <ul> element. |
| Pseudo-Class Selector | Selects elements based on their state or position in the document. | a:hover | Selects all <a> elements when the mouse is |
There are many pseudo-class selectors, some of which are described in this table.
| Pseudo-class Selector | Description |
|---|---|
| :hover | Selects an element when the mouse pointer |
| :active | Selects an element when it is being |
| :visited | Selects a link that has been visited by |
| :focus | Selects an element when it has focus (e.g. |
| :first-child | Selects the first child element of its |
| :last-child | Selects the last child element of its |
| :nth-child(n) | Selects the nth child element of its |
| :nth-of-type(n) | Selects the nth element of its type |
| :last-of-type | Selects the last occurrence of an |
The CSS expression below shows how to select the first div of the body element.
html > body > div:nth-of-type(1)
1 | <html> |
The next-sibling combinator (+) separates two selectors and matches the second element only if it immediately follows the first element, and both are children of the same parent element.
1 | <ul> |
select the <li>Two!</li>
1 | li:first-of-type + li { |
Select by attribute value containinginput[class*="example"]
Select by attribute value starting withinput[id^="example"]
Select by attribute value ending witha[href$="example"]
XPath to CSS Selector Conversion
| Equivalency | XPath Notation | CSS Selector |
|---|---|---|
| Select by element type | //div | div |
| Select by class name | //div[@class=”example”] |
div.example |
| Select by ID | //*[@id=”example”] |
#example |
| Select by attribute | //input[@name=”example”] |
input[name=”example”] |
| Select by attribute value containing | //input[contains(@class, “example”)] |
input[class*=”example”] |
| Select by attribute value starting with | //input[starts-with(@id, “example”)] |
input[id^=”example”] |
| Select by attribute value ending with | //a[ends-with(@href, “example”)] |
a[href$=”example”] |
| Select by sibling | //div/following-sibling::p | div + p |
| Select by descendant | //div//p | div p |
| Select by first child | //div/p[1] |
div > |
| Select by last child | //div/p[last()] |
div > |
parsel.Selector
$ pip install parsel
.xpath() and .css() methods return a SelectorList instance, which is a list of new selectors.
If you want to extract only the first matched element, you can call the selector .get()
1 | from parsel import Selector |
selecting the text inside the title tag:
1 | selector.xpath('//title/text()') |
To actually extract the textual data, you must call the selector .get() or .getall() methods, as follows:
1 | selector.xpath('//title/text()').getall() |
query for attributes using .attrib property of a Selector:
1 | [img.attrib['src'] for img in selector.css('img')] |
As a shortcut, .attrib is also available on SelectorList directly; it returns attributes for the first matching element:
1 | selector.css('img').attrib['src'] |
1 | from parsel import Selector |
bs4
1 | page = BeautifulSoup(content, "html.parser") |
1 | img = article.find_all("img")[0] |
bs4 lxml
1 | html = requests.get("https://www.google.com/search?q=minecraft", headers=headers) |
bs4

获取信息:
1 | html = """ |
节点名称print(first_a_link.name) # "a"
节点属性
1 | print(first_a_link.attrs) # dictinary : {'href': 'http://news.baidu.com', 'class': ['mnav'], 'name': 'tj_trnews'} |
节点文本内容print(first_a_link.string) # "news"
嵌套选择节点
1 | first_div_element = bs.find(name="div") |
find findall
findall(name=””, attrs={}, text=””)
name节点名称
attrs节点属性
常用属性id class 直接传入
1 | print(bs.find(id="head")) |
text节点文本内容
1 | a_link = bs.find_all("a", attrs={"href": "http://news.baidu.com"}) |
beautifulsoup
install packages:
requests
beautifulsoup4
lxml
bs4
1 | import requests |
subscript = soup.find('div', class_='full-script').get_text(separator="\n", strip=True)
def get_text(self,
separator: str = “”,
strip: bool = False,
types: tuple[Type[NavigableString], …] = …) -> str
Get all child strings of this PageElement, concatenated using the given separator.
Params:
separator – Strings will be concatenated using this separator.
strip – If True, strings will be stripped before being concatenated.
types – A tuple of NavigableString subclasses. Any strings of a subclass not found in this list will be ignored. Although there are exceptions, the default behavior in most cases is to consider only NavigableString and CData objects. That means no comments, processing instructions, etc.
Returns:
A string.
1 | movie_urls = movie_list.find_all('a', href=True) |
subslikescript.com
1 | import requests |
css select
1 | print(bs.select("div")) |
pandas
1 | import pandas |
json
json_string = resp.text().decode() # 是 json格式字符串
json_dict = json.loads(json_string, encoding=’utf-8’)
json dict -> json string
json.dumps()
example
1 | response = requests.post(url, data=data, headers=headers) |
session
1 | import requests |
1 | my_header = { |
referer
1 | my_headers = { |
pycrypto 安装
The Visual C++ Redistributable installs Microsoft C and C++ (MSVC) runtime libraries. These libraries are required by many applications built by using Microsoft C and C++ tools. If your app uses those libraries, a Microsoft Visual C++ Redistributable package must be installed on the target system before you install your app.
Microsoft C++ 生成工具通过可编写脚本的独立安装程序提供 MSVC 工具集,无需使用 Visual Studio。 如果从命令行界面(例如,持续集成工作流中)生成面向 Windows 的 C++ 库和应用程序, 则推荐使用此工具。
Win7安装pycrypto报错ucrt\inttypes.h(26): error C2061: syntax error: identifier ‘intmax_t‘
1.将C:\Program Files (x86)\Microsoft Visual Studio 14.0\VC\include下的stdint.h复制到C:\Program Files (x86)\Windows Kits\10\Include\10.0.18362.0\ucrt2.编辑C:\Program Files (x86)\Windows Kits\10\Include\10.0.18362.0\ucrt下的inttypes.h将#include <stdint.h>改为#include “stdint.h”, 目的是让它使用上面第一点复制的头文件stdint.h
pycrypto is no longer maintained: see pycrypto.org pycryptodome is the modern maintained replacement for pycrypto
视频
m3u8
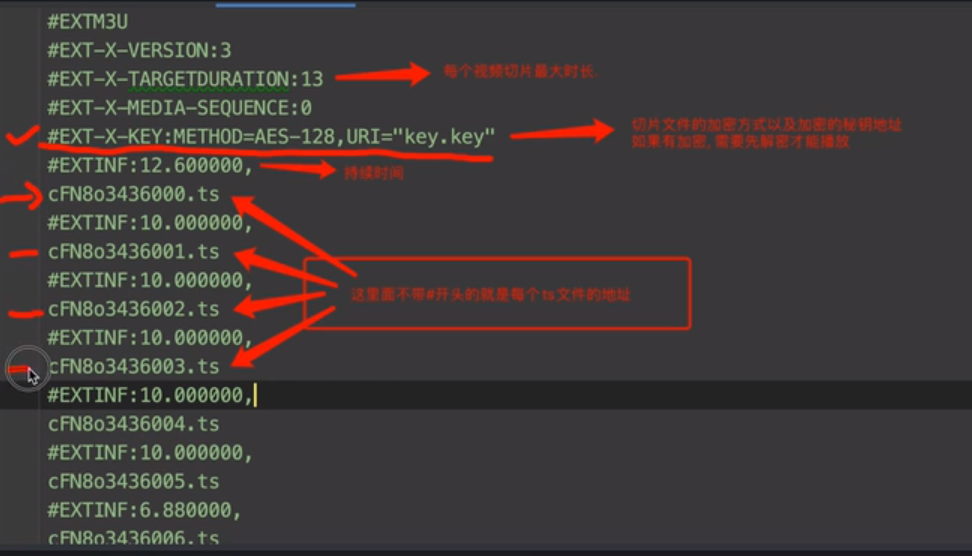
https%3A%2F%2Fnew.1080pzy.co%2F20230116%2F34sxZOJQ%2Findex.m3u8
1 | https://new.1080pzy.co/20230116/34sxZOJQ/index.m3u8 |
1 | https://new.1080pzy.co/20230116/34sxZOJQ/1100kb/hls/index.m3u8 |
The data is UTF-8 encoded bytes escaped with URL quoting, so you want to decode, with urllib.parse.unquote(), which handles decoding from percent-encoded data to UTF-8 bytes and then to text, transparently:
1 | >>> from urllib.parse import unquote |
ffmpeg使用语法:
具体一点来说:
-f concat,-f 一般设置输出文件的格式,如-f psp(输出psp专用格式),但是如果跟concat,则表示采用concat协议,对文件进行连接合并。
-safe 0,用于忽略一些文件名错误,如长路径、空格、非ANSIC字符
-i D:\ProgramData\study\mov\order.m3u8,-i后面加输入文件名,当然也可以加输入文件名组成的文件名,即order.m3u8,但是要满足文件格式,即类似于下面这种:
file ‘D:\ProgramData\study\mov\tsfiles\MQJ9iKoM.ts’
file ‘D:\ProgramData\study\mov\tsfiles\8LeDe7Wu.ts’-c copy D:\ProgramData\study\mov\hello.mp4,-c表示输出文件采用的编码器,后面跟copy,表示直接复制,不重新编码。
并发
1 | from threading import Thread |
1 | from threading import Thread |
池
1 | from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor |
协程coroutine
阻塞requests.get(url)
网络请求返回数据之前,处于阻塞状态。
协程:
当程序遇见IO操作时,选择性的切换到其他任务
微观上,单线程下,一个任务一个任务的进行切换,切换条件即IO操作
宏观上,多个任务同时执行,即多任务异步操作。
DeprecationWarning: The explicit passing of coroutine objects to asyncio.wait() is deprecated since Python 3.8, and scheduled for removal in Python 3.11.
The asyncio.wait() documentation obviously says nothing about this or what you’re supposed to do instead, but as far as I can figure out you replace asyncio.wait([a, b]) with asyncio.gather(a, b).
1 | import time |
1 | import aiohttp |
aes 解密 TS
1 | async def dec_ts(name, key): |
ts合并
1 | # mac os |
selenium
pip install selenium
install chrome driver
copy to the python.exe and scripts folder
if you have selenium above the 4.6.0 you don’t need to add executable_url and in the latest version of Selenium you don’t need to download webdriver.
With latest selenium(v4.6.0 and onwards), its in-built tool known as SeleniumManger can download and handle the driver.exe if you do not specify.
Selenium Manager provides automated driver management for: Google Chrome, Mozilla Firefox, Microsoft Edge.
Selenium Manager is invoked transparently by the Selenium bindings when:
No browser driver is detected on the PATH
No third party driver manager is being used
1 | from selenium.webdriver import Chrome, ChromeOptions |
With WebDriverWait, you don’t really have to take that into account. It will wait only as long as necessary until the desired element shows up (or it hits a timeout).
A WebElement is a Selenium object representing an HTML element.
There are many actions that you can perform on those objects, here are the most useful:
Accessing the text of the element with the property element.text
Clicking the element with element.click()
Accessing an attribute with element.get_attribute('class')
Sending text to an input with element.send_keys('mypassword')
WebDriver provides two main methods for finding elements.
find_element
find_elements
| Type | Description | DOM Sample | Example |
|---|---|---|---|
| By.ID | Searches for elements based on their HTML ID | <div id="myID"> |
find_element(By.ID, “myID”) |
| By.NAME | Searches for elements based on their name attribute | <input name="myNAME"> |
find_element(By.NAME, “myNAME”) |
| By.XPATH | Searches for elements based on an XPath expression | <span>My <a>Link</a></span> |
find_element(By.XPATH, “//span/ |
| By.LINK_TEXT | Searches for anchor elements based on a match of their text content | <a>My Link</a> |
find_element(By.LINK_TEXT, “My Link”) |
| By.PARTIAL_LINK_TEXT | Searches for anchor elements based on a sub-string match of their text content | <a>My Link</a> |
find_element(By.PARTIAL_LINK_TEXT, “Link”) |
| By.TAG_NAME | Searches for elements based on their tag name | <h1> |
find_element(By.TAG_NAME, “h1”) |
| By.CLASS_NAME | Searches for elements based on their HTML classes | <div class="myCLASS"> |
find_element(By.CLASSNAME, |
| By.CSS_SELECTOR | Searches for elements based on a CSS selector | <span>My <a>Link</a></span> |
find_element(By.CSS_SELECTOR, |
1 | # from selenium.webdriver import Chrome, ChromeOptions |
1 | browser = Chrome() |
1 | from selenium.webdirver import ChromeOptions |
selenium
1 | from selenium import webdriver |
headless mode
1 | from selenium import webdriver |
audible.com
1 | import time |
twitter.com login
1 | from selenium import webdriver |
快速生成由复制的文本生成 DICT
regex: (.*): (.*)
replace: "$1": "$2",
1 | i: 好人 |
1 | "i": "好人", |
md5
from hashlib import md5
def md5_string(string_0):
s = md5()
s.update(string_0.encode())
return s.hexdigest()