Hello, world!
;` This funny tag syntax is neither a string nor HTML. It is called JSX, and it is a syntax extension to JavaScript. We recommend using it with React to describe what the UI should look like. JSX may remind you of a template language, but it comes with the full power of JavaScript. JSX produces React “elements”. Instead of artificially separating technologies by putting markup and logic in separate files, React separates concerns with loosely coupled units called “components” that contain both. - Embedding Expressions in JSX In the example below, we declare a variable called name and then use it inside JSX by wrapping it in curly braces: const name = 'Josh Perez'; const element =Hello, {name}
; - JSX is an Expression Too After compilation, JSX expressions become regular JavaScript function calls and evaluate to JavaScript objects. This means that you can use JSX inside of if statements and for loops, assign it to variables, accept it as arguments, and return it from functions:1 | function getGreeting(user) { |
1 | const element = ( |
{title}
; By default, React DOM escapes any values embedded in JSX before rendering them. Thus it ensures that you can never inject anything that’s not explicitly written in your application. Everything is converted to a string before being rendered. This helps prevent XSS (cross-site-scripting) attacks. - Which characters need to be escaped in HTML inserting text content in your document in a location where text content is expected By "a location where text content is expected", I mean inside of an element or quoted attribute value where normal parsing rules apply. For example:HERE
or...
. Inside of an element, this just includes the entity escape ampersand & and the element delimiter less-than and greater-than signs < >: & becomes & < becomes < > becomes > Inside of attribute values you must also escape the quote character you're using: " becomes " ' becomes ' I encourage you to escape all five in all cases to reduce the chance of making a mistake. In general, you should not escape spaces as . is not a normal space, it's a non-breaking space. You can use these instead of normal spaces to prevent a line break from being inserted between two words, or to insert extra space without it being automatically collapsed, but this is usually a rare case. Don't do this unless you have a design constraint that requires it. - ! content that has special parsing rules or meaning, such as inside of a script or style tag, or as an element or attribute name. For example: `...
.` In these contexts, the rules are more complicated and it's much easier to introduce a security vulnerability. I strongly discourage you from ever inserting dynamic content in any of these locations. There's usually a safer alternative, such as putting the dynamic value in an attribute and then handling it with JavaScript. - JSX Represents Objects Babel compiles JSX down to React.createElement() calls. These two examples are identical:1 | const element = ( |
1 | const root = ReactDOM.createRoot( |
Hello, {props.name}
; } This function is a valid React component because it accepts a single “props” (which stands for properties) object argument with data and returns a React element. We call such components “function components” because they are literally JavaScript functions. You can also use an ES6 class to define a component:1 | class Welcome extends React.Component { |
1 | function Welcome(props) { |
1 | function Comment(props) { |
1 | function Avatar(props) { |
1 | function Comment(props) { |
1 | function UserInfo(props) { |
1 | function Comment(props) { |
1 | class Clock extends React.Component { |
1 | class Clock extends React.Component { |
1 | this.setState({ |
1 | this.setState((state, props) => ({ |
1 | class Toggle extends React.Component { |
1 | class LoggingButton extends React.Component { |
1 | class LoggingButton extends React.Component { |
1 | render() { |
1 | function WarningBanner(props) { |
- element:
When you run code, you’ll be given a warning that a key should be provided for list items. A “key” is a special string attribute you need to include when creating lists of elements.
1 | function NumberList(props) { |
1 | function ListItem(props) { |
1 | function ListItem(props) { |
1 | function NumberList(props) { |
1 | function FancyBorder(props) { |
1 | function WelcomeDialog() { |
1 | function SplitPane(props) { |
1 | function Dialog(props) { |
the complete javascript course zero to expert
fundamentas 01
alert("Hello World!")
1 | let js = 'amazing'; |
javascript is a high-level object-oriented, multi-paradigm programming language
programming language: instruct computer to do things
high level: we dont have to worry about complex stuff like memory management
object oriented: based on objects, for storing most kinds of data
multi paradigm: we can use different styles of programming
- dynamic effects and web applications in the browser -> react agular vue
- web applications on web servers -> nodejs
- native mobile applications -> native react, ionic
- native desktop applications -> electorn
ES6/ES2015
1 | 40 + 8 + 23 - 10; |
value and variables
1 | console.log('Jonas'); |
camlcaselet first = 'Jonas';let firstNamePerson;
error number firstlet 2ads = 2;
letter
number8
undersocre_
dollarsign$
no key word
constantsPI
class namePerson
name descriptivelet myFirstJob = 'Programmer';let myCurrentJob = 'Teacher';
notlet job1 = 'Programmer';let job2 = 'Teacher';
data types
dymatic type
object or primitive
primitive
number
floating point used for dicimals and integers
string
sequence of characters
boolean
true or false
undifined
value taken by a variable that is not yet defined(‘empty value’)
let children;
null
symbol(es2015)
unique and cannot be changed
bigint(es2020)
larger integers
1 |
|
let const var
1 | let age = 30; |
basic operators
1 | const now = 2037 |
percedence
1 | const now = 2037; |
Coding Challenge #1
string and template literal
1 | const firstName = 'Jonas' |
if else control structure
1 | const age = 15; |
type conversion and coercion
coercion auto
conversion manually
1 |
|
truthy and falsy values
boolean coercion
- logical operator
- logical context: if else statement
1 | // 5 falsy values: 0, '', undefined, null, NaN |
equal operators
1 | const age = 18; |
boolean logic operators
and or not
1 |
|
switch statement
1 |
|
statement and expression
expression produce a value
3 + 41991true && false && !false
statement
not produce a value
if else statement
// error
console.log(i am ${2037 - 1991} years old ${if(true){console.log('hello');}});
condition operator (ternary)
it is an expression
only one line block of code
es5 es6+
use babel to transpile and polyfill code
coverting back to es5 to ensure browser compatibility for all users
fundamentas 02
strict mode
first line'use strict';
1 | ; |
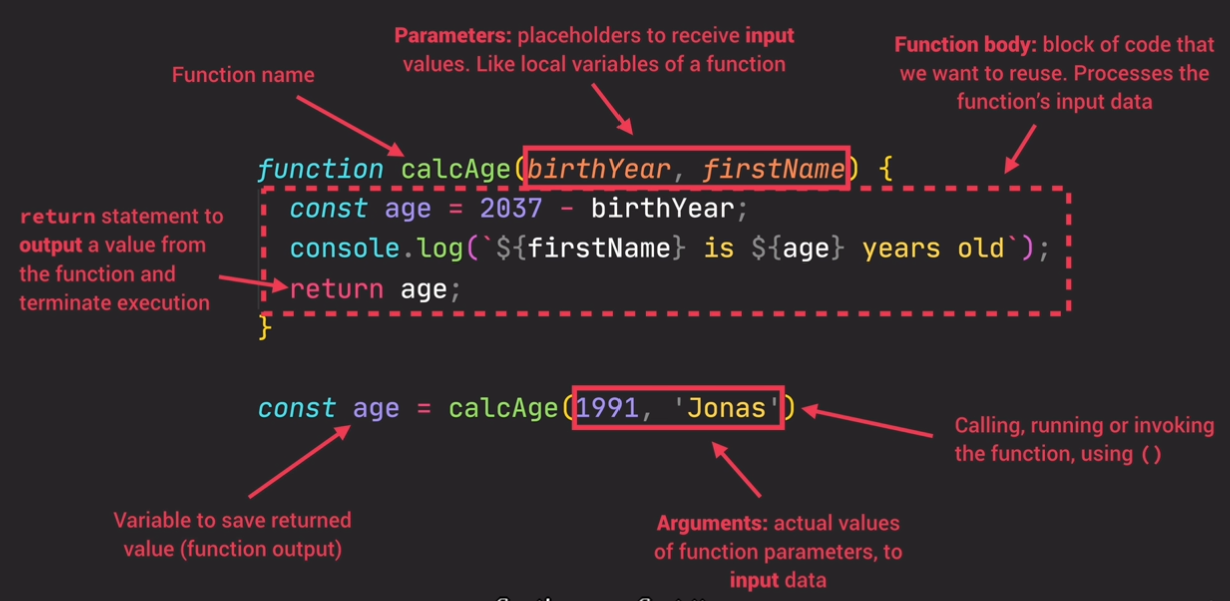
function
1 | function logger() { |
function declarations vs experssions
1 | // function declaration |
arrow functions
1 |
|
functions calling other functions
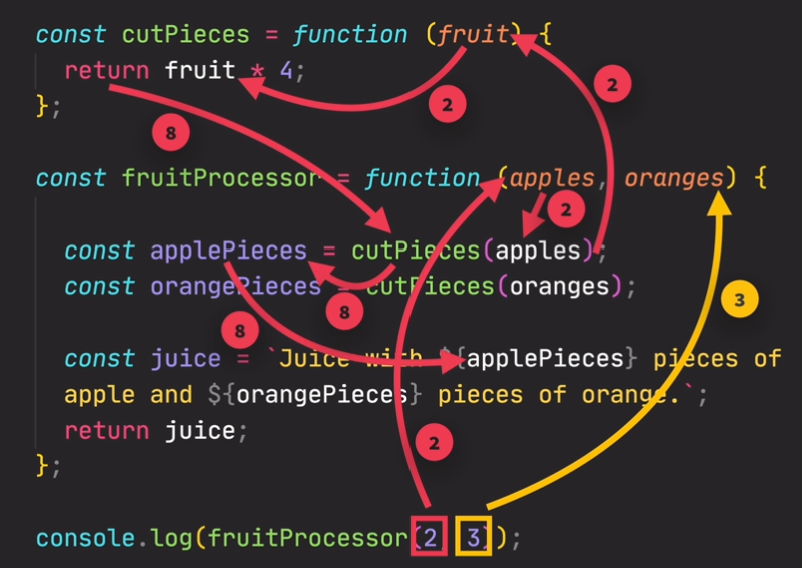
1 |
|
function reviewing
1 |
|
introducing to array data structure
1 |
|
basic array operations(methods)
1 |
|
introduce to Objects
1 |
|
object methods
1 |
|
iteration for loop
1 |
|
loop array, break, continue
1 | const jonas = [ |
looping backwards and loops in loops
1 |
|
while loop
1 |
|
developer skills
DOM AND EVENT – guess my number
console.log(document.querySelector('.message')); // element p.message
console.log(document.querySelector('.message').textContent); // "Start guessing..."
select and manupulating elements
document.querySelector('.message').textContent = 'Correct Number!'
document.querySelector('.guess').value = 10;
handling event -> event lisener
(method) Element.addEventListener<keyof ElementEventMap>(type: keyof ElementEventMap, listener: (this: Element, ev: Event) => any, options?: boolean | AddEventListenerOptions | undefined): void (+1 overload)
1 | // addEventListener -> most used one |
implementing the game logic
manipulation css styles
change the html inline css style
// manupilating css styledocument.querySelector('body').style.backgroundColor = '#60b347';
document.querySelector('.number').style.width = '30rem';
the dry principle
project 2 modal
1 | const btnsShowModal = document.querySelectorAll('.show-modal'); |
css class manupulating
const modal = document.querySelector('.modal');modal.classList.remove("hidden", 'class-name');
1 | // btnCloseModal.addEventListener('click', () => { |
key press event
global event
document
1 | document.addEventListener('keydown', function (e) { |
project 3 pig game
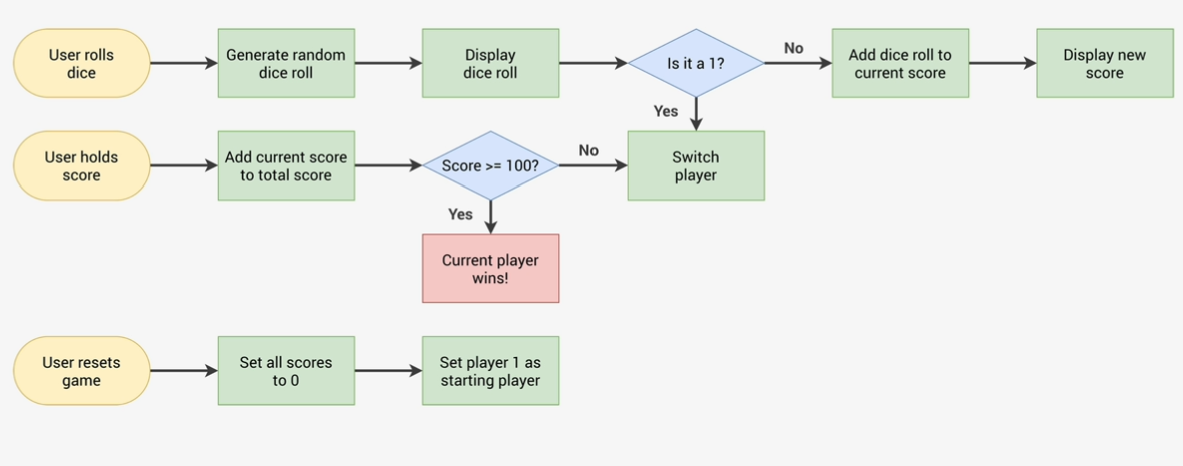
const player1Score = document.getElementById('score--0');
// set img element attribute srcdice.src = `dice-${String(currentDice)}.png`;
document.querySelector(`.player--${currentPlayer}`).classList.toggle("player--active");
how javascript works
high level overview of javascript
javascript is a high level, prototype-based object-oriented, multi-paradigm, interpreted or just-in-time compied, dynamic, single-threaded, garbage-collected programming language with first-class functions and a non-blocking event loop concurrency model.
high level
manage computer resources automatically
garbage-collected
interpreted or just in time compiled
javascirpted engine
multi-paradigm
paradigm: an approach and mindset of structuring code, which will direct your coding style and technique.
- procedural
- objected oriented
- functional
prototype-based object oriented
first-class functions
functions are simply treated as variables. we can pass them into other functions, return them from functions.
dynamic type
no data type when variable definitons.
data type of variable is automatically changed
single-threaded
non-blocking event loop
concurrency model: the javascript engine handles multiple tasks happpening at the same time.
event loop: takes long running tasks, executes them in the background, and put them back in the main thread once they are finished.
javascript engine and runtime
program that executes javascript code.
v8 engine
chrome, nodejs
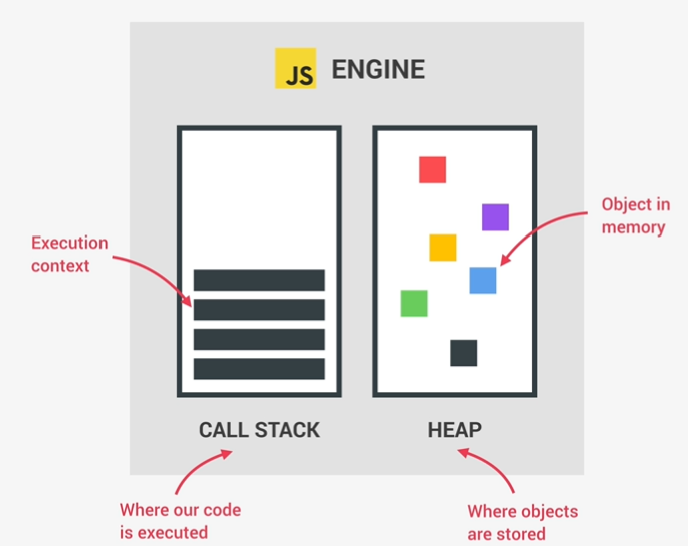
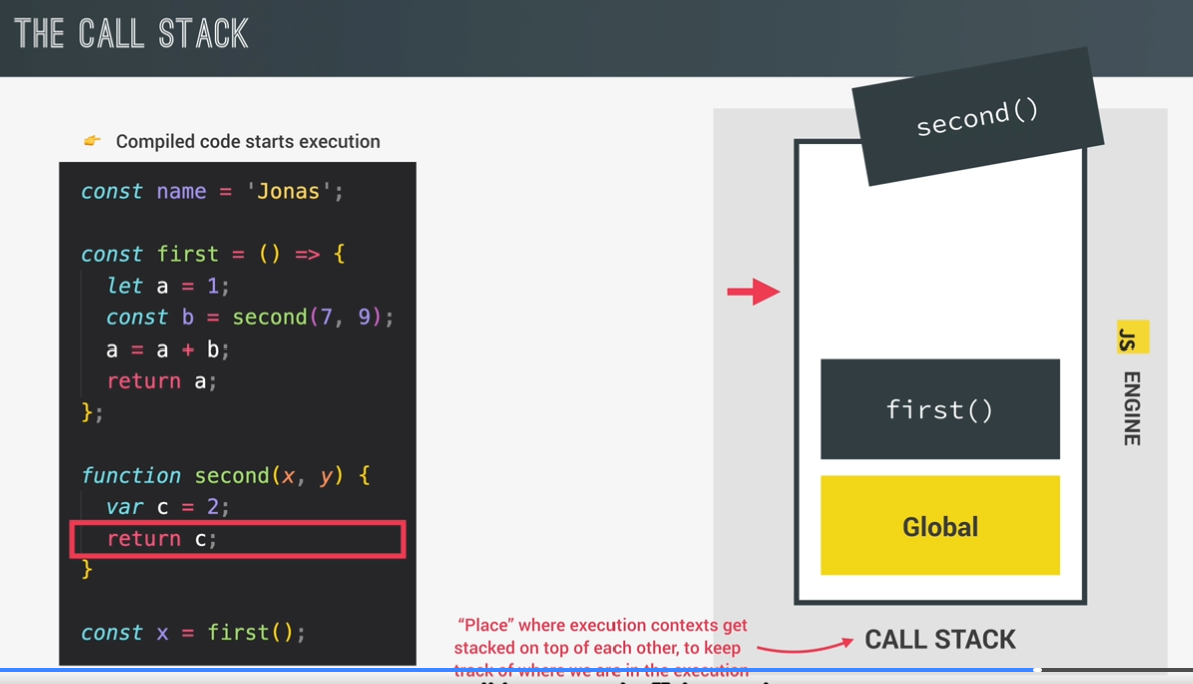
call stack
heap
compilation vs interpretation
compilation: entire code is coverted into machine code at once, and written to a binary file that can be executed by a computer.
interpretation: interpreter runs through the source code and executes it line by line.
just-in-time comilation
entire code is converted into machine code at once, then executed immediately.
parse into AST:
abstract signtax tree
re-compilate optimization
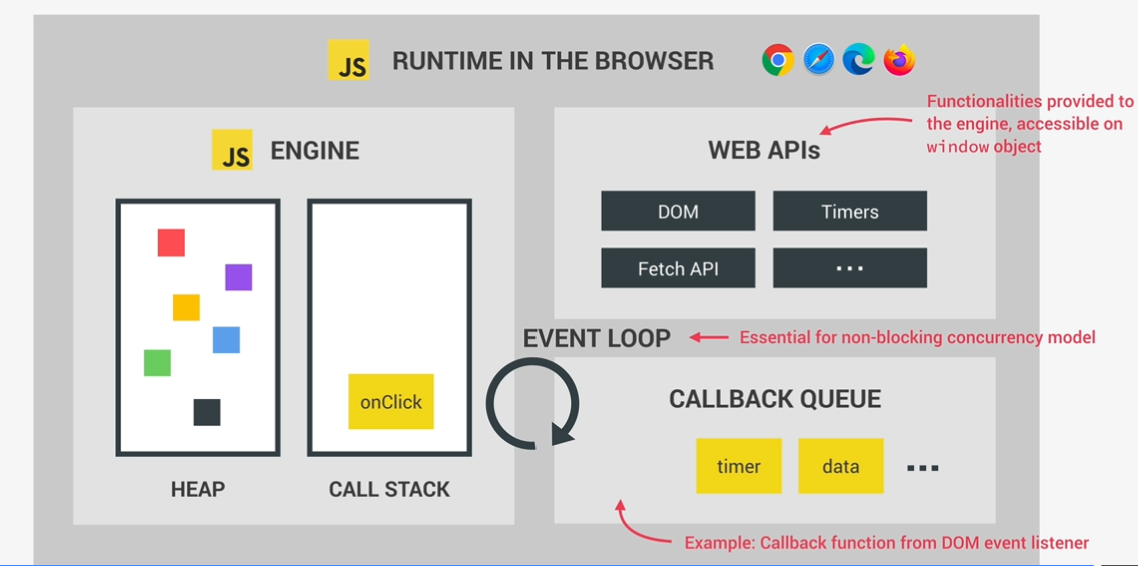
js runtime in the browser
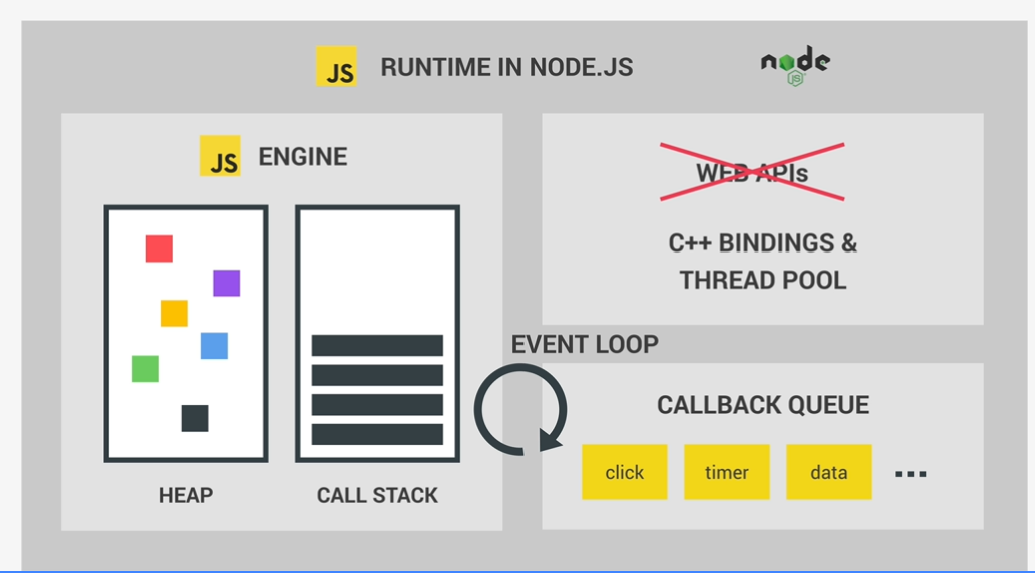
nodejs runtime
execution contexts and the call stack
exeution context
environment in which a piece of javascript is executed. stores all the necessary information for some code to be executed.
one global execution context(ec)
default context, created from code that is not inside any function(top level)
function execution context(ec)
for each function call, a new execution context is created.
- varialbe environment
- let, const and var declarations
- Functions
- arguments object
- scope chain: consists of references to varialbes that are lacated outside of the function
- this keyword
!!! arrow functin dont have arguents object, this keyword
they used the arguemnt object and this keyword from the closest function pareant.
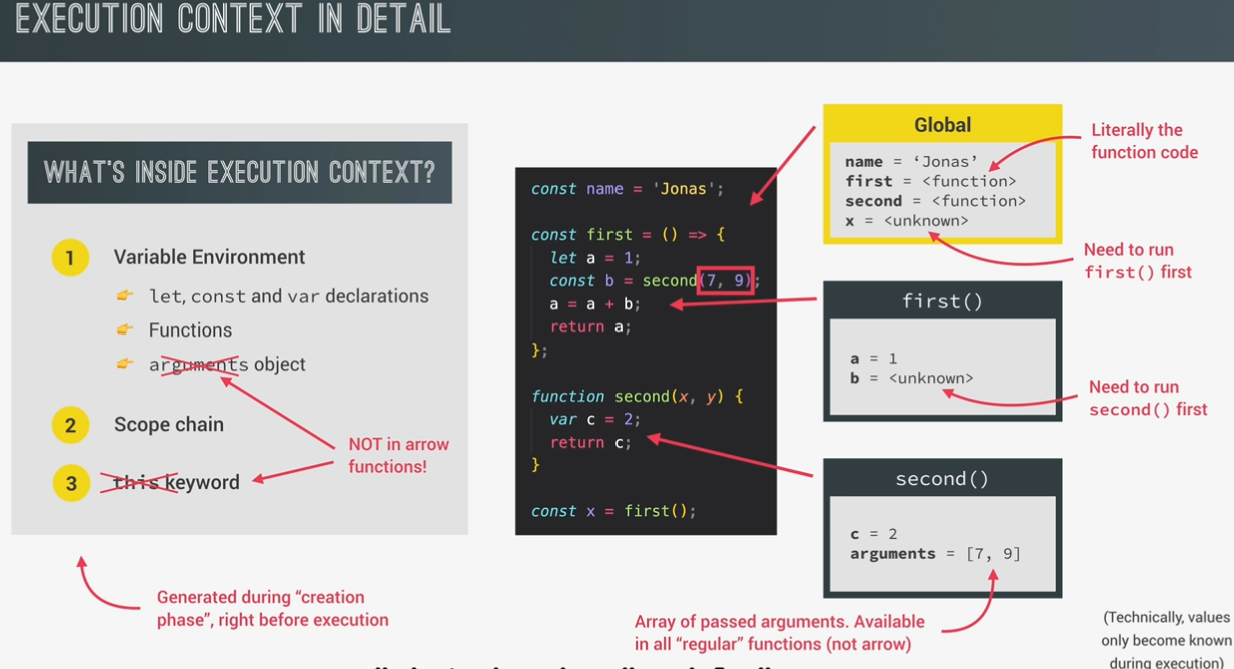
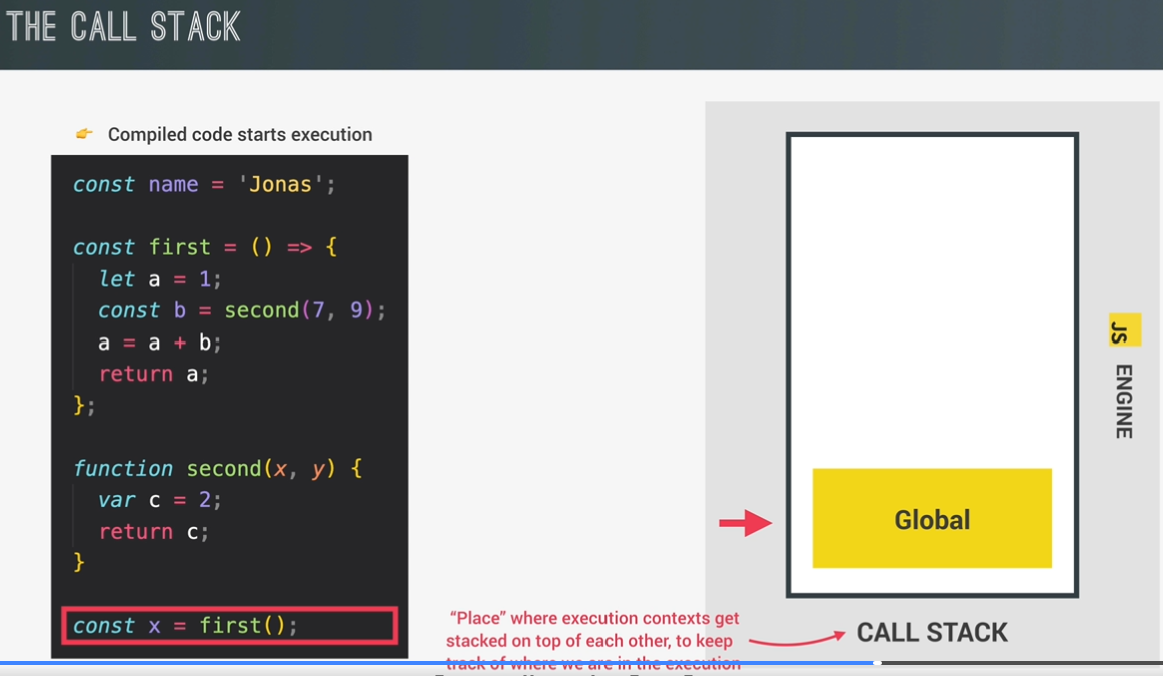
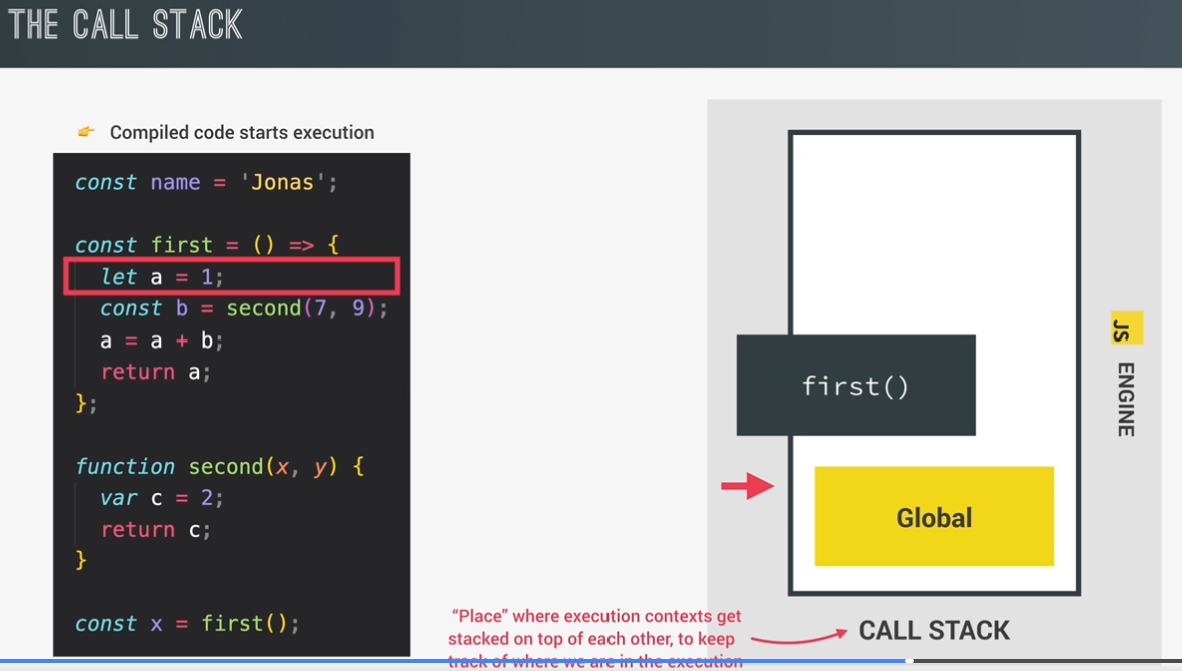
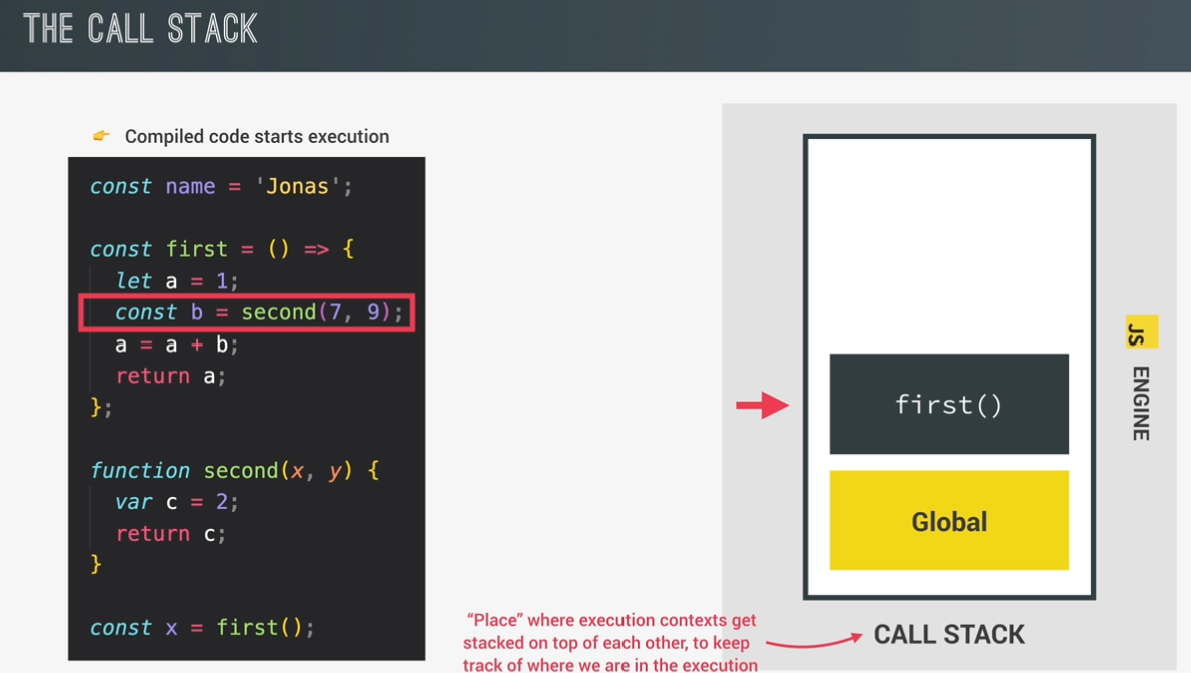
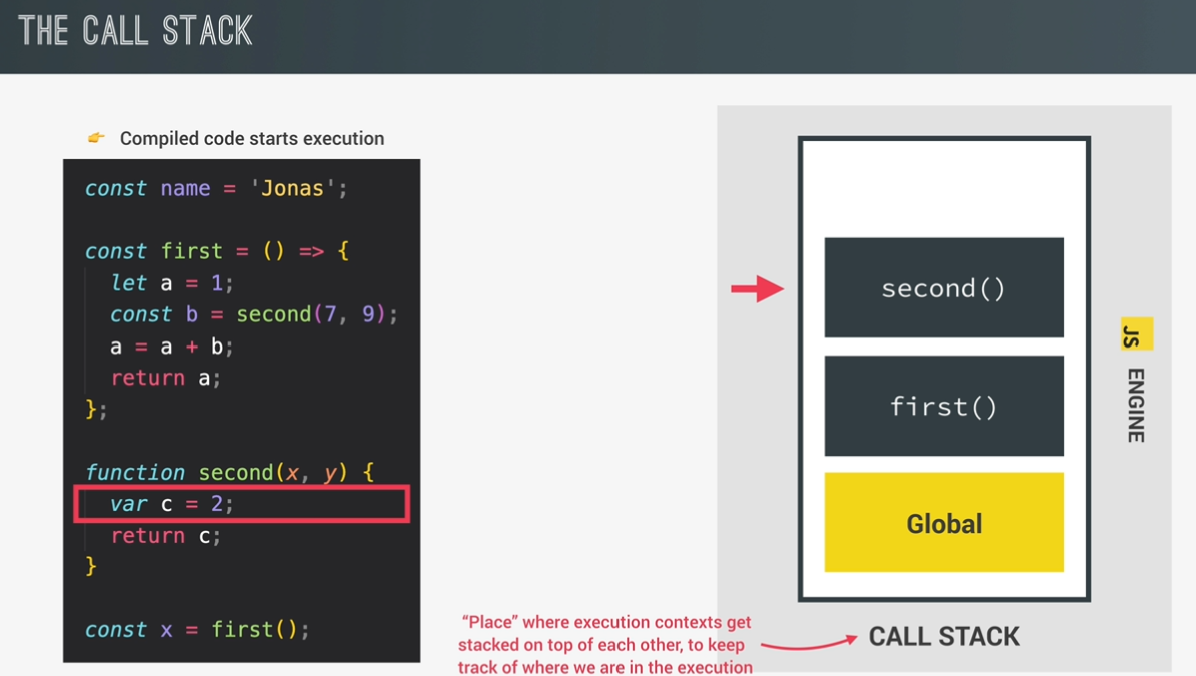
call stack:
place where execution contexts get stacked on top of each other, to keep track of where we are in the execution.
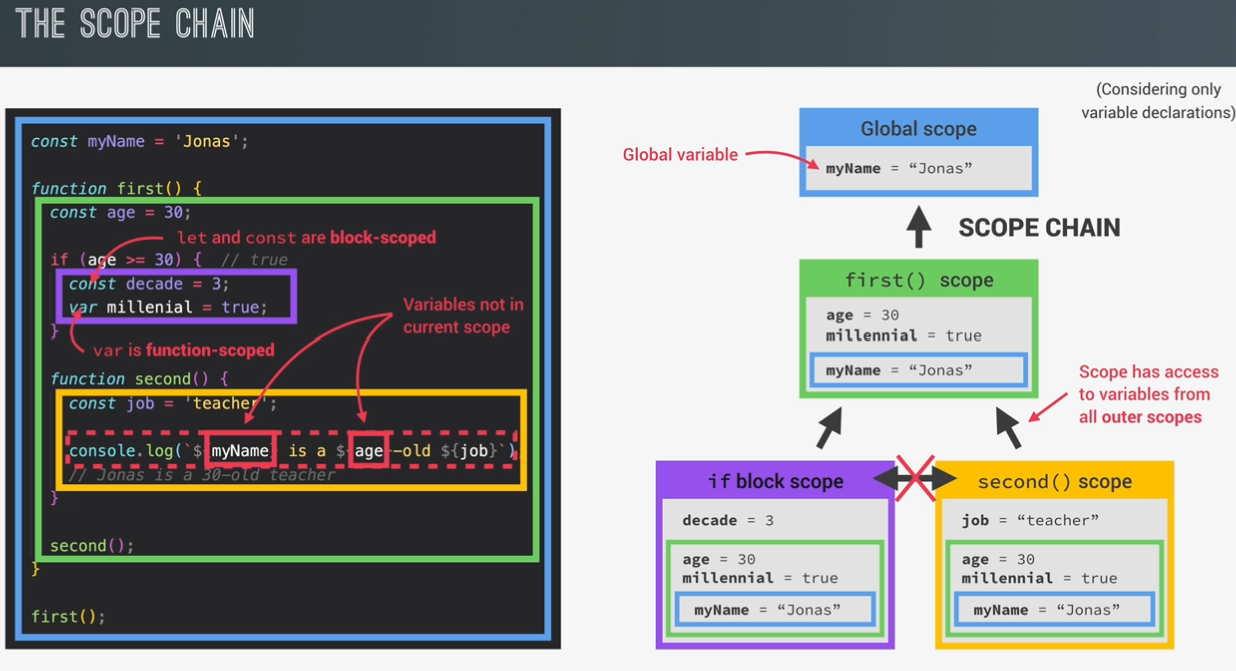
scope and scope chain
scoping: how programs’s variabes are organized and accessed.
“where do variables live?” or “where can we access a certain vairalbe, and where not?”
lexical scoping:
scoping is controlled by placement of functions and blocks in the code;
example like: a function write inside another function can have access to variable of the parent function
scope: space or environment in which a certain variable is declared(variable environment in case of functions scope). there is global scope, function scope, and block scope;
scope of a variable: region of our code where a certain variable can be accessed
3 types of scope
- global scope
1 | const me = 'Jonas'; |
outside of any function or block
variable declared in global scope are accessible everywhere
- function scope
1 | function calcAge(birthYear) { |
variables are accessible only inside function, Not outside
also called local scope
- block scope (ES6)
1 | // example: if block, for loop block, etc |
variable are accessible only inside block(block scoped)
however, this only applies to let and const variables!
functions are also block scoped(only in strict mode)
scope chain
1 | const myName = "Jonas"; |
scope chain vs call stack
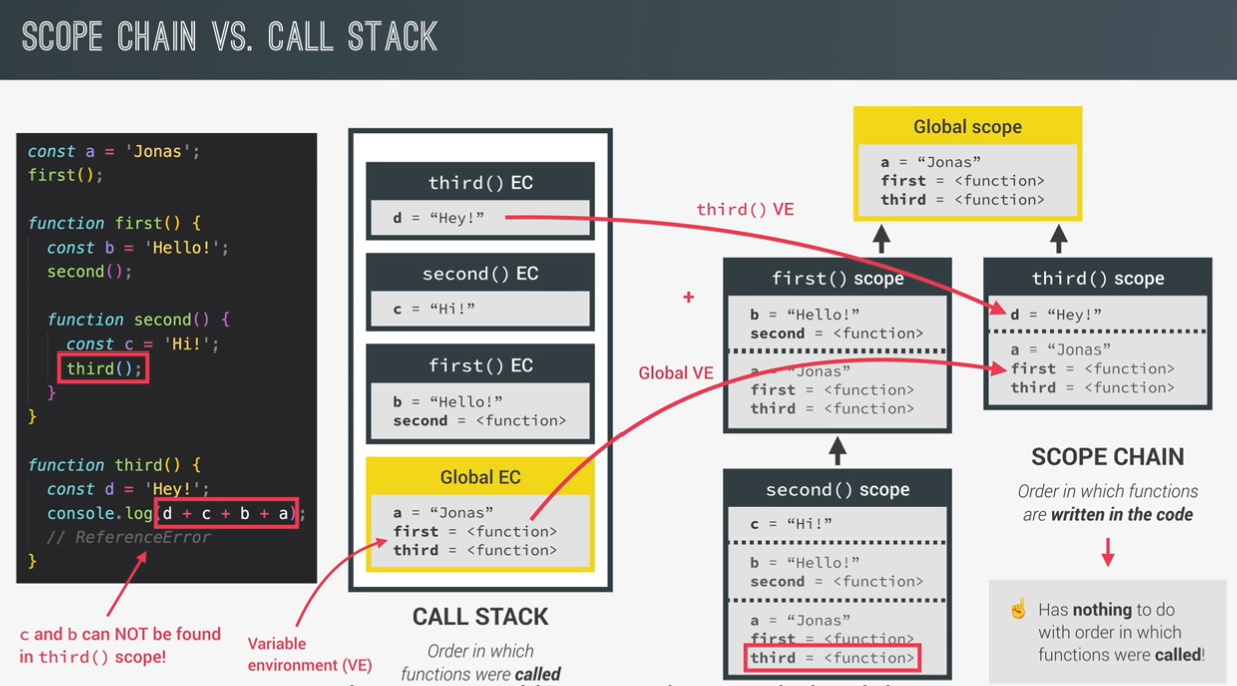
1 |
|
1 | function calcAge(birthYear) { |
variable environment: hoisting
hoisting:makes some types of variable acessible/usable in the code before they are actually declared.
“ variables lifted to the top of their scope”.
before execution, code is scanned for variable declarations, and for each variable, a new property is created in the variable environment object.
temporal dead zone

1 | const myName = "Jonas"; |
- make it easier to avoid and catch erros: accessing variables before declaration is ba d prctice and should be avoided;
- makes const variables actully work
1 | // undefined |
1 | var x = 1; |
this keyword
this keyword/variable: special variable that is created for every execution context(every funtion). Takes the value of(point to) the “owner” of the function in which the this keyword is used.
this is NOT static.
it depends on how the function is called, and its valued is only assigned when the function is acturally called.
- Method
object that is calling the method
1 | const jonas = { |
simple function call
in strict mode
undefindedArrow functions
this of surrounding function (lexical this)event listener
DOM element that the handler is attatched tonew, call, apply, bind
this does not point to the function itself, and also NOT the its variable environment
1 |
|
this in regular and arrow fucntions
1 | // dont use arrow function this time |
1 |
|
primitives vs object (primitive vs reference types)
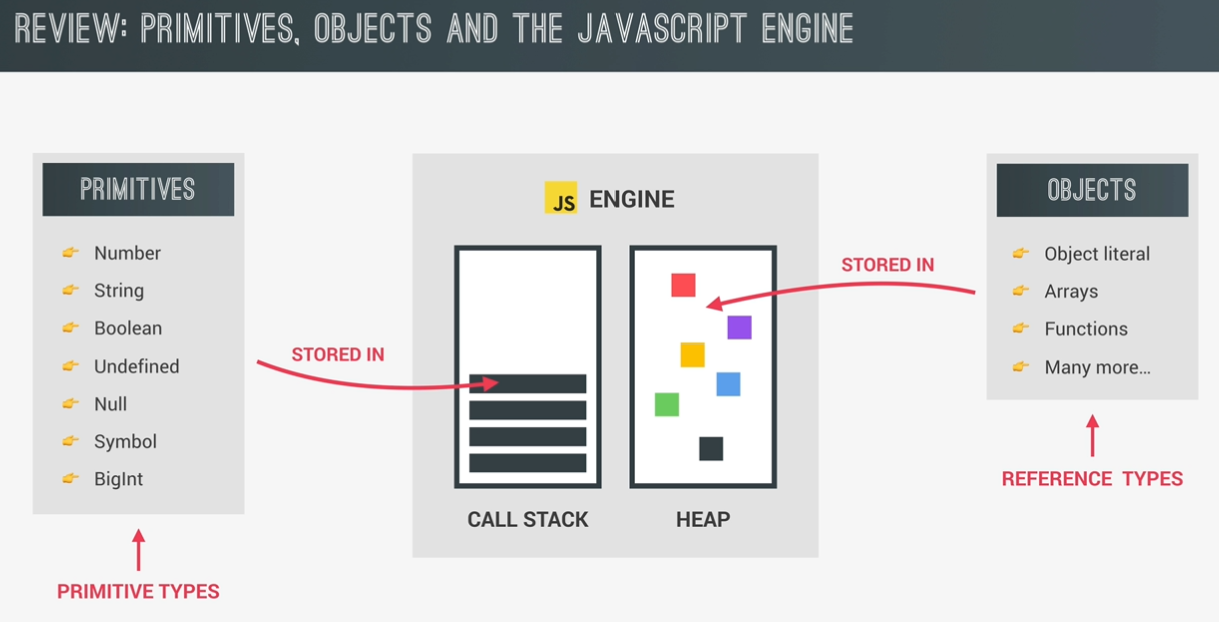

1 |
|
1 |
|
data structures, strings
destructuring array
1 |
|
1 | // receive 2 return values from a function |
1 | // nested destructuring |
1 | // Default values |
destructuring object
get data from api
1 | const restaurant = { |
1 |
|
spread operator
right side of asignment operator
get all the values spreadly
used only when
in array
function arguments
works on all iterables
arrays stirng maps, sets, NOT objects
1 |
|
rest pattern
left side of asignment operator
collect rest elemnets
always in the last place and only one
1 |
|
short circuiting
||
if the first value is a turthy value, it will imediately return the first value
1 |
|
nullish coalescing oparator
1 | // if restaurant.numGuests = 0 |
logical assignment operators(es2021)
1 |
|
for of loop
1 |
|
enhanced object literals
1 | const weekdays = ['mon', 'tue', 'wen', 'thu', 'fri', 'sat', 'sun']; |
optinal chaining (?.)
1 |
|
loop object key value entries
1 |
|
sets (unique elements)
order of sets is irrelevant
no way to get only one element from a set
1 |
|
maps
key can be any type of data
1 | const rest = new Map(); |
maps: iteration
1 | const question = new Map([ |
which data structure to use
sources of data
- from the program iteself: data written directly in source code (e.g. status messages)
- from the ui: data input from the user or data written in DOM(e.g. tasks in todo app)
- From external sources: data fetched for example from web api(e.g. rcipe objects)
simple list
key/value pairs: key allow us to describe values
array <> sets
array:
- use when you need ordered list of values(might contain duplicates)
- use when you need to manipulate data
sets
- use when you need to work with unique values
- use when high-performance is really important
- use to remove duplicates form arrays
objects
more ‘traditonal’ key/value store (‘abused’ object)
easier to write and access value with . and []
use when you need to include functions(methods)
use when working with json (can convert to map)
maps
better performance
keys can have any data type
easy to iterate
easy to compute size
use when you simply need to map key to values
use whe you need keys that are not strings
String methods
1 |
|
1 |
|
1 |
|
function deep
default parameters
1 |
|
how passing arguments works: value vs reference
1 |
|
first class and higher order functions
functions are simply values
functions are just another ‘type’ of object
1 | // store functions in variables or properties |
high order functions
a function that receives anthoer function as an argument
a function that returns a new function
or both
functins accepting callback functions
1 | const oneWord = function (str) { |
functions returning functions
1 |
|
the CALL and apply METHODS
1 |
|
bind method
1 |
|
immediately invoked function expression
1 |
|
closures
make functions remenber all the variables where it is birthed place.
a function has access to the variable environment(VE) of the execution context in which it was created.
even if it was gone.
closure: VE attached to the function, exactly as it was at the time and place the function was created
closure is priority over scope chain
less formal
a closure is the closed-over variable environment of the execution context in which a function was created, even after that execution context is gone;
a closure give a function aceess to all the variables of its parent function, even after that parent function has returned. The function keeps a reference to its outer scope, which preserves the scope chain throughout time.
a closeure makes sure that a function doesnt lose connection to variable that existed at the function’s birth place
a clsure is like a backpack that a function carries around wherever it goes. This backpack has all the variable that were present in the environment where the function was created.
we can not directly access a closure-over variables explicitly
1 |
|
1 |
|
1 | (function () { |
array deep
1 |
|
at method
1 | const arr = [23, 11, 64]; |
foreach: looping arrays
foreach
cant break or continue
1 |
|
foreach with maps and sets
1 |
|
bankist project
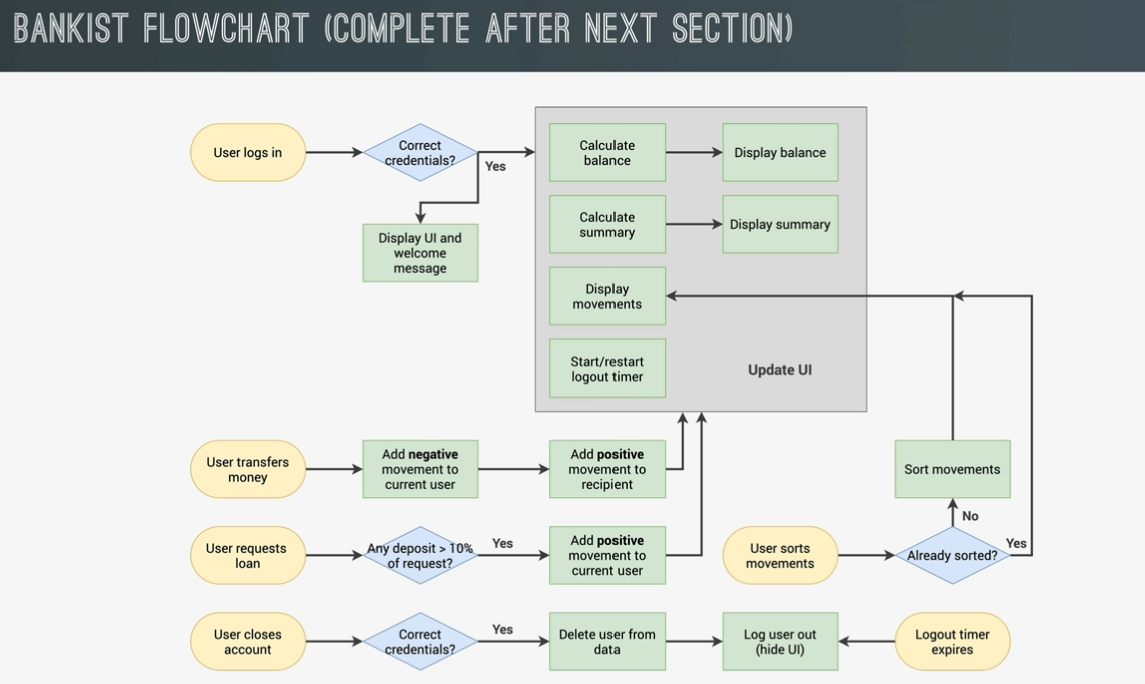
create DOM element
1 | const containerMovements = document.querySelector('.movements'); |
position
A string representing the position relative to the element. Must be one of the following strings
“beforebegin”
Before the element. Only valid if the element is in the DOM tree and has a parent element.
“afterbegin”
Just inside the element, before its first child.
“beforeend”
Just inside the element, after its last child.
“afterend”
After the element. Only valid if the element is in the DOM tree and has a parent element.
1 | <!-- beforebegin --> |
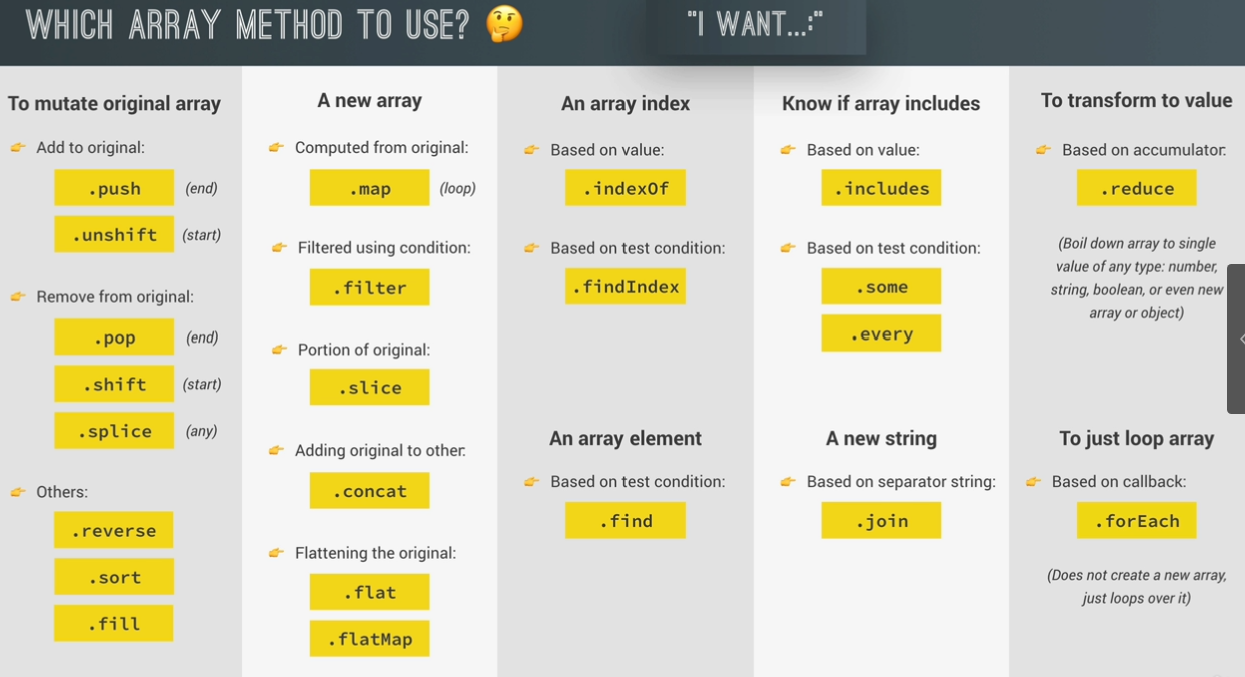
data transformations: map, filter, reduce
map
returns a new array containg the results of applying an operation on all origianl array elements.
filter
filter returns a new array containing the array elements that passed a specified test condition
reduce
boils(reduce) all array elements down to one single value(e.g. adding all elements together)
1 | const arr = [3, 1, 4, 3, 2]; |
map
1 |
|
filter method
1 | const movements = [200, 450, -400, 3000, -650, -130, 70, 1300]; |
the reduce method
1 |
|
1 | /// maximum value |
chainning methods
1 |
|
the find method
1 |
|
bankist project login page
1 | const btnLogin = document.querySelector('.login__btn'); |
bankist project: implementing transfers
the findindex method
1 | /// delete account |
some and every methods
1 |
|
flat and flatmap
1 |
|
sorting arrays
1 | const owners = ['Jonas', 'Zach', 'Adam', 'Martha']; |
1 | const dogs1 = [ |
creating and filling arrays
1 |
|
array summary
numbers and dates, times, intl
conveting and check numbers
1 |
|
Math method and rounding
1 |
|
remainder operator
1 |
|
numeric separators
1 | // 2,874,600,000 |
BigInt
1 |
|
creating dates
1 | const now = new Date(); |
adding dates to bankist app project
1 | const day = `${now.getDate()}`.padStart(2, 0); |
operation with dates
1 |
|
internationalizing date (intl i18n)
ISO LANGUAGE CODE TABLEhttp://www.lingoes.net/en/translator/langcode.htm
1 |
|
internationalzing numbers (intl)
1 | const num = 134641312.32; |
timer: setTimeout setInterval
setTimeout once
setInterval repeat
1 | // setTimeout(handler: TimerHandler, timeout?: number | undefined, ...arguments: any[]): number |
1 | const timeInter = setInterval(function () { |
bankist project: implemetn a countdown
1 | const startLogoutTimer = function () { |
1 | let timer; |
advanced DOM and EVENT
DOM deep
- allows us to make javascript interact with the browser;
- we can write javascript to create, modify and delete Html elements; set styles, classes and attributes; and listen and respond to events;
- dom tree is generated from an html document, which can then interac with;
- dom is a very complex api(application programming interface) that contains lots of methods and properties to interact with the dom tree
types of dom objects
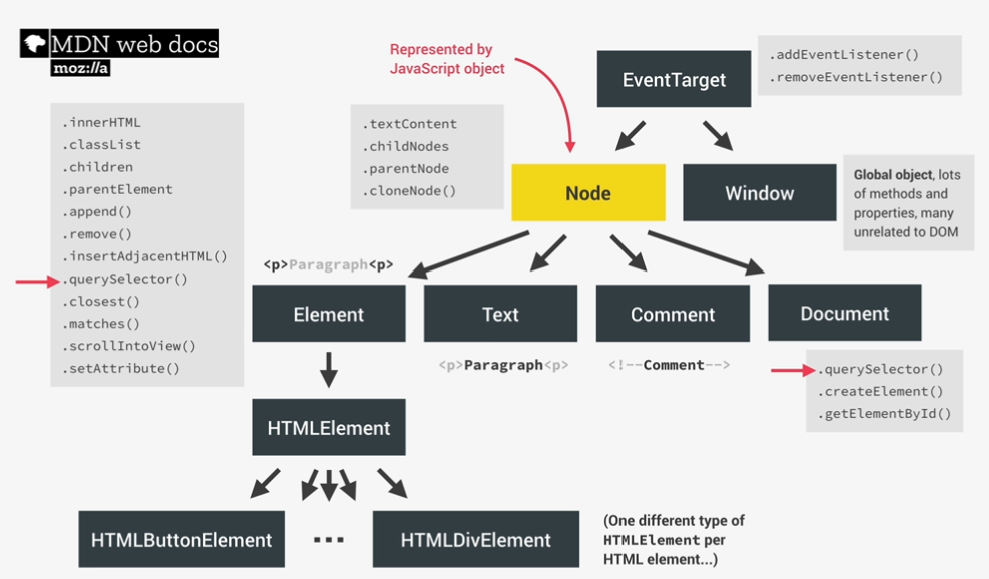
select, create, and delete elements
1 |
|
style, attribute and class
1 | :root { |
1 | <img |
1 |
|
smooth scrolling
1 | <div class="header__title"> |
1 |
|
types of event and event handlers
old<h1 onclick="alert('HTML alert')">
1 |
|
event propagation: bubbling and capturing
propagetion传播;培养
the spreading of something (a belief or practice) into new regions
1 | <html> |
- capturing phase
- target phase
- bubbling phase
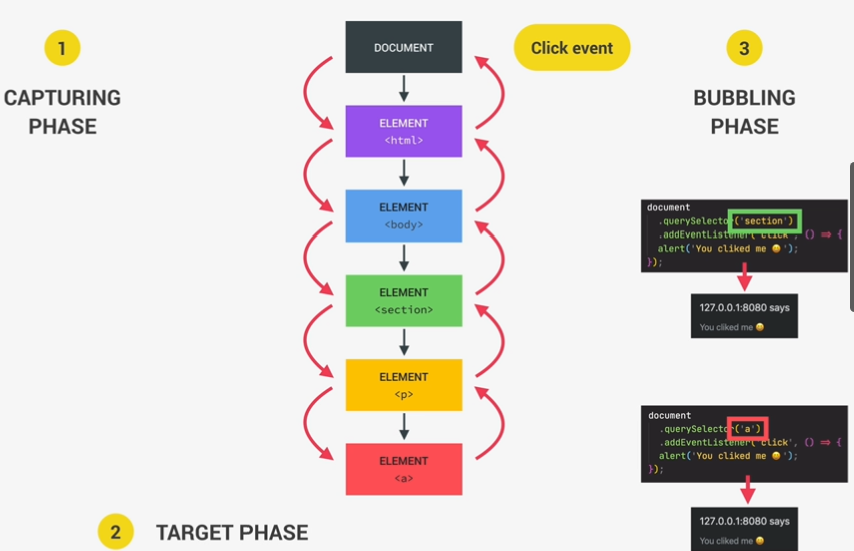
1 | document.querySelector('section').addEventListener('click', () => { |
example:

1 | <nav class="nav"> |
1 |
|
event delegation implementing: page navigation
1 | <nav class="nav"> |
1 | //////////// page navigation |
examples 2
add eventlistener that dont exit at the monment
DOM traversingDOM traversing
select elmenent by another elements
1 | <div class="header__title"> |
1 |
|
tabs: tabbed component
1 | <div class="operations"> |
1 |
|
passing arguments to event handlers
1 | <nav class="nav"> |
1 |
|
the scroll event: sticky navigation bar
1 | .nav.sticky { |
1 | /////// sticky naivgation |
better way: intersection observer api
1 | ///provides a way to asynchronously observe changes in the intersection of a target element with an ancestor element or with a top-level document's viewport. |
revealing elements on scroll
1 | .section--hidden { |
1 | /////////// reveal sections |
lazy image loading
1 | <img |
1 | .lazy-img { |
1 | ///// lazy loading images |
building a slider component
1 | <section class="section" id="section--3"> |
1 | <div class="dots"> |
1 | .slider { |
1 | //////////////slider |
DOM load event
1 | // html and js downloaded |
js loading and execude

OOP
what is OOP?
oop is a programming paradigm based on the concept of objects
we use objects to model(describe) real world or abstract features
object may contain data(properties) and code (methods). by using objects, we pack data and the corresponding behavior into one block;
in oop, objects are self-contained pieces/ blocks of code
objects are building blocks of applicatins, and interact with one another;
interactions happen through a pubblic interface (API): methods that the code outside of the object can access and use to communicate with the object;
OOP was developed with the goal of organizing code, to make it more flexible and easier to maintain(avoid ‘spaghetti code’)
Abstraction: Ignoring or hiding details that dont matter, allowing us to get an overview perspective of the thing we’re implementing, instead of messing with details that don’t really matter to our implementation.
1 | User { |
- Encapsulation: Keeping properties and methos private inside the class, so they are not accessible from outside the class. Some methods cas be exposed as a public interface(API)
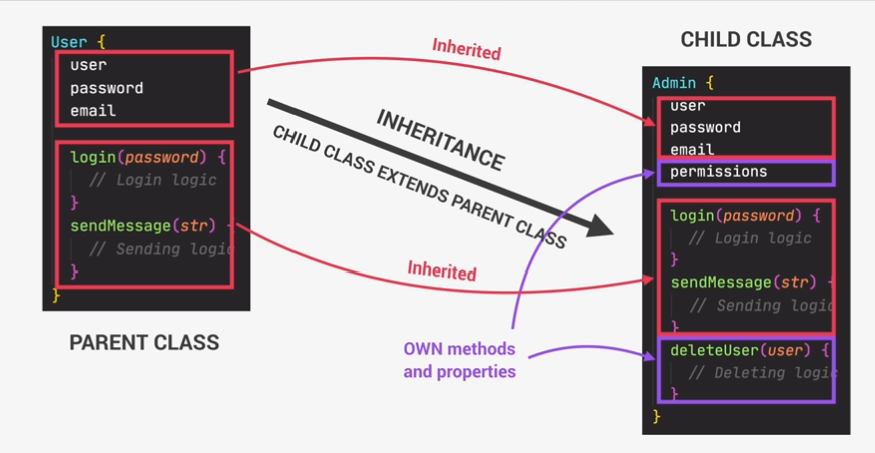
- Inheritance: Making all properties and methods of a certain class available to a child class, forming a hierarchical relationshipp between classes. This allows us to reuse commmon logic and to model real world relationships.
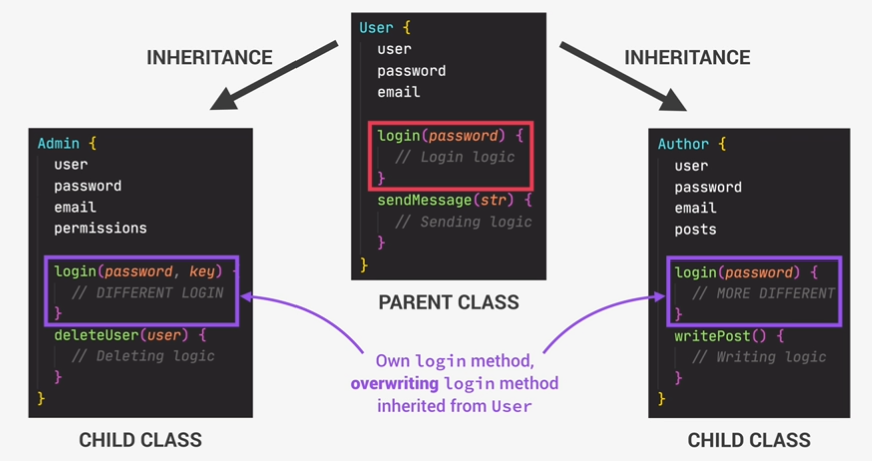
- Polymorphism: A child class can overwrite a method it inherited from a parent class.
javascript OOP
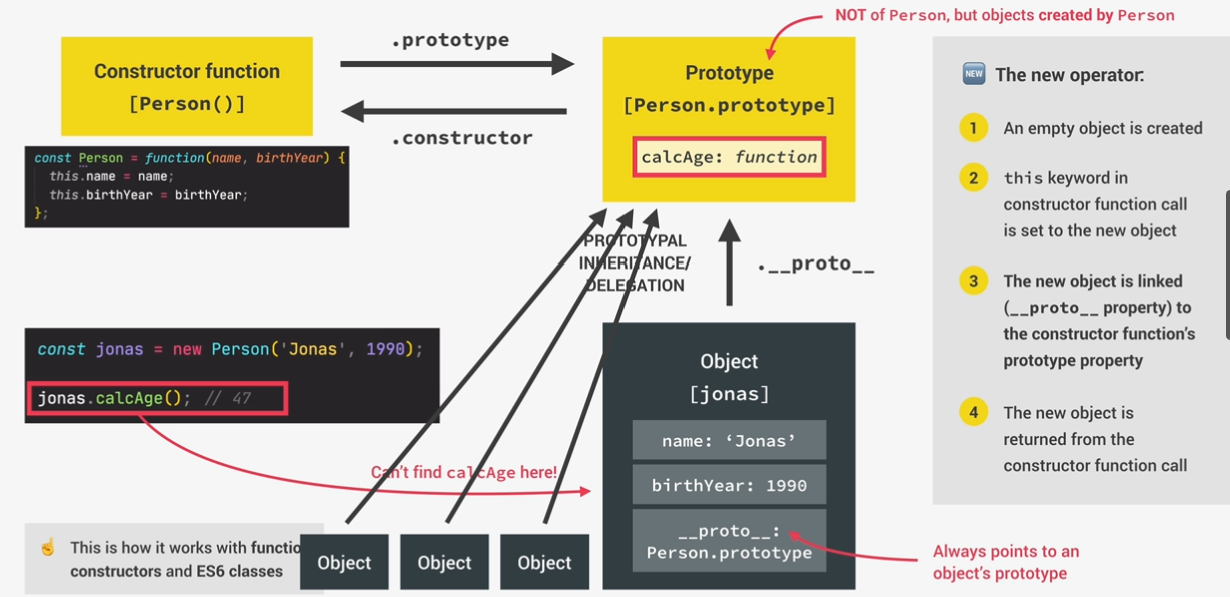
- Objects are linked to a prototype object;
- Prototypal inheritance: The prototype contains methods (behavior) that are accessible to all objects linked to that prototype;
- behavior is delegated(授权) to the linked prototype object.
3 ways of implementing prototypal inheritance in javascript
- Constructor funtions
- Technique to create objects from a function;
- This is how built-in objects like Arrays, Maps or Sets are actually implemented.
- ES6 Classes
- Modern alternative to constructor function syntax;
- ‘Syntactic sugar’: behind the scenes, ES6 classes work exactly like constructor functions
- ES6 clasees do not behavior like classes in “classical OOP”
- Object.create()
- the easiest and most straightforward way of linking an object to a prototype object.
constructor function and the new operator
1 | //// dont use arrow function(no this keyword) |
prototypes
1 | // prototypes |
prototypal inheritance: the prototype chain
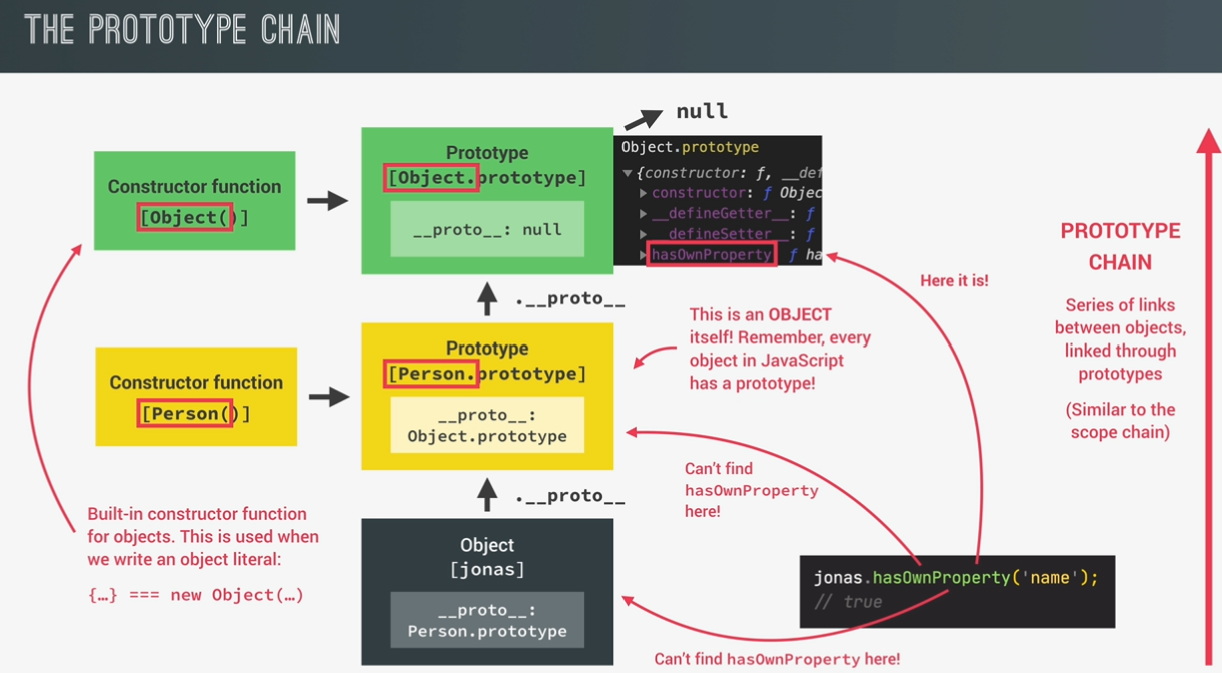
prototypal inheritance: built-in objects
1 |
|
ES6 classes
1 | //// class expression |
classes: getter and setter
1 |
|
1 |
|
static methods
Array.from()
method belong to Constructor object
1 |
|
Object.create
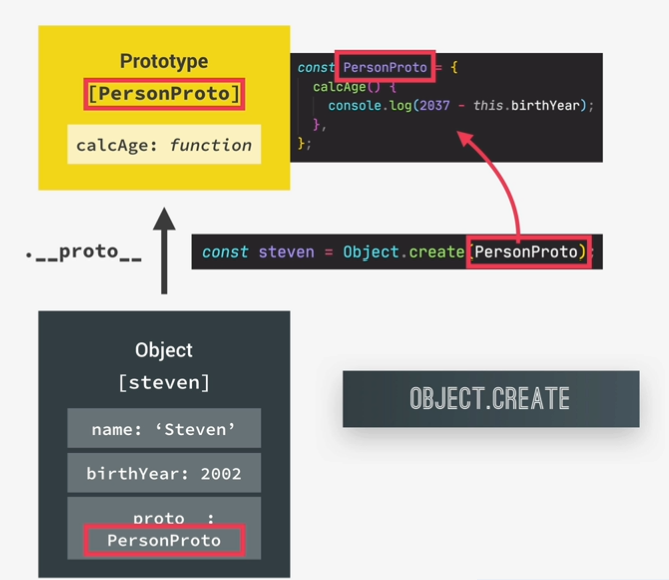
1 |
|
inheritance between ‘classes’: constructor functions
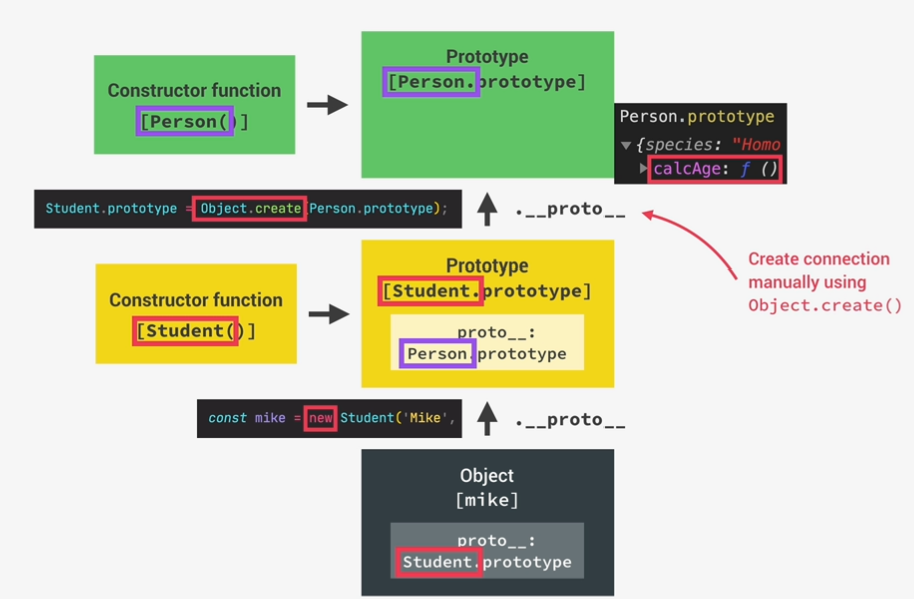
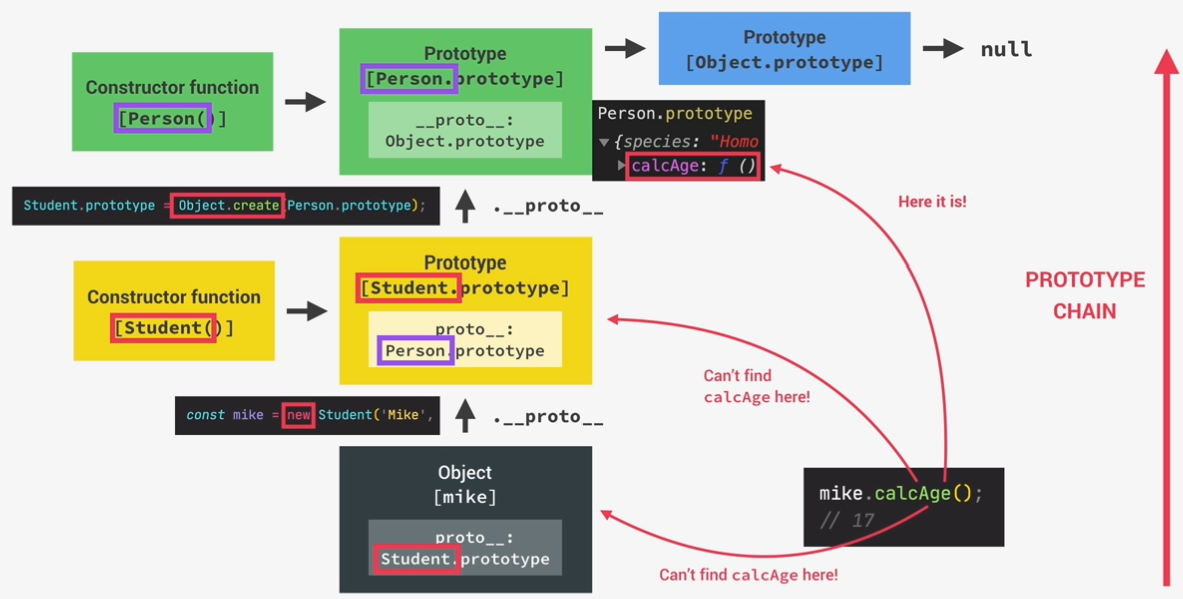
1 |
|
polymorphism
1 |
|
inheritance between ‘classes’: ES6 classes
1 |
|
inheritance between ‘classes’: Object.create
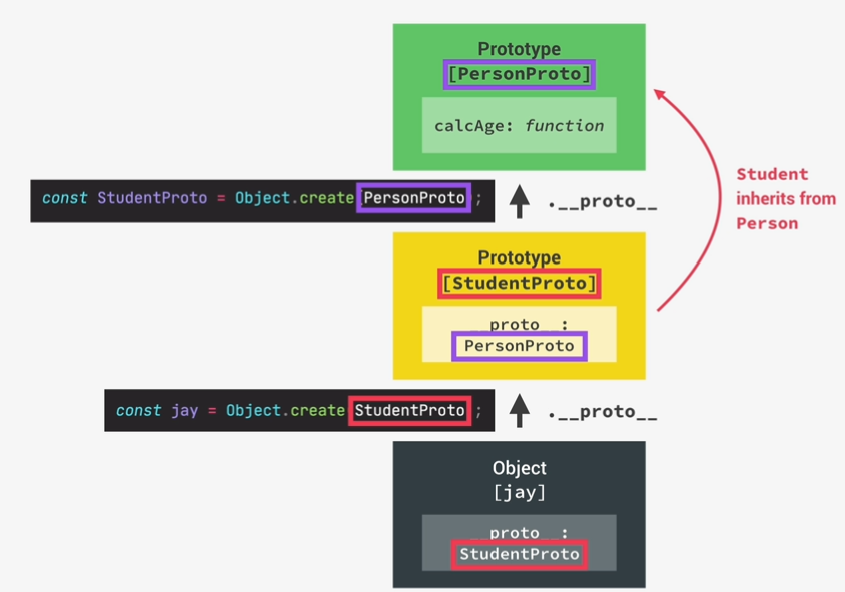
1 |
|
class example
1 |
|
Encapsulation: protected properties and methods
1 |
|
Encapsulation: private class fields and methods
1 |
|
chain methods
1 | class Account { |
OOP summary
1 |
|
Mapty app OOP project
project planning
- user stories
- description of the application’s functionality from the user’s perspective
- common format: As a [type of user(who)], I want [an action(what)] so that [a benefit(why)]
- example
- as a user, i want to log my running workouts with location, distance, time, pace and steps/minute, so i can keep a log of all my running
- as a user, i want to log my cycling workouts with location, distance, time, speed and elevtion gain, so i can keep a log of all my cycling
- as a user i want to see all my workouts at a glance, so i can easily track my progress over time
- as a user, i want to also see my workouts on a map, so i can easily check where i work out the most
- as a user, i want to see all my workouts when i leave the app and come back later, so that i can keep using the app over time
- features
- user 1:
- 1.map where user clicks to add new workout(best way to get location coordinates)
- 2.geolocation to display map at current location(more user friendly)
- 3.form to input distance, time, pace, steps/minute
- user 2: 4.form to input distance, time, speed, elevation gain
- user 3: 5.display all workouts in a list
- user 4: 6.display all workouts on the map
- user 5:
- 7.store workout data in the browser using local storage API
- 8.on page load, read the saved data from local storage and display
- user 1:
- flowchart
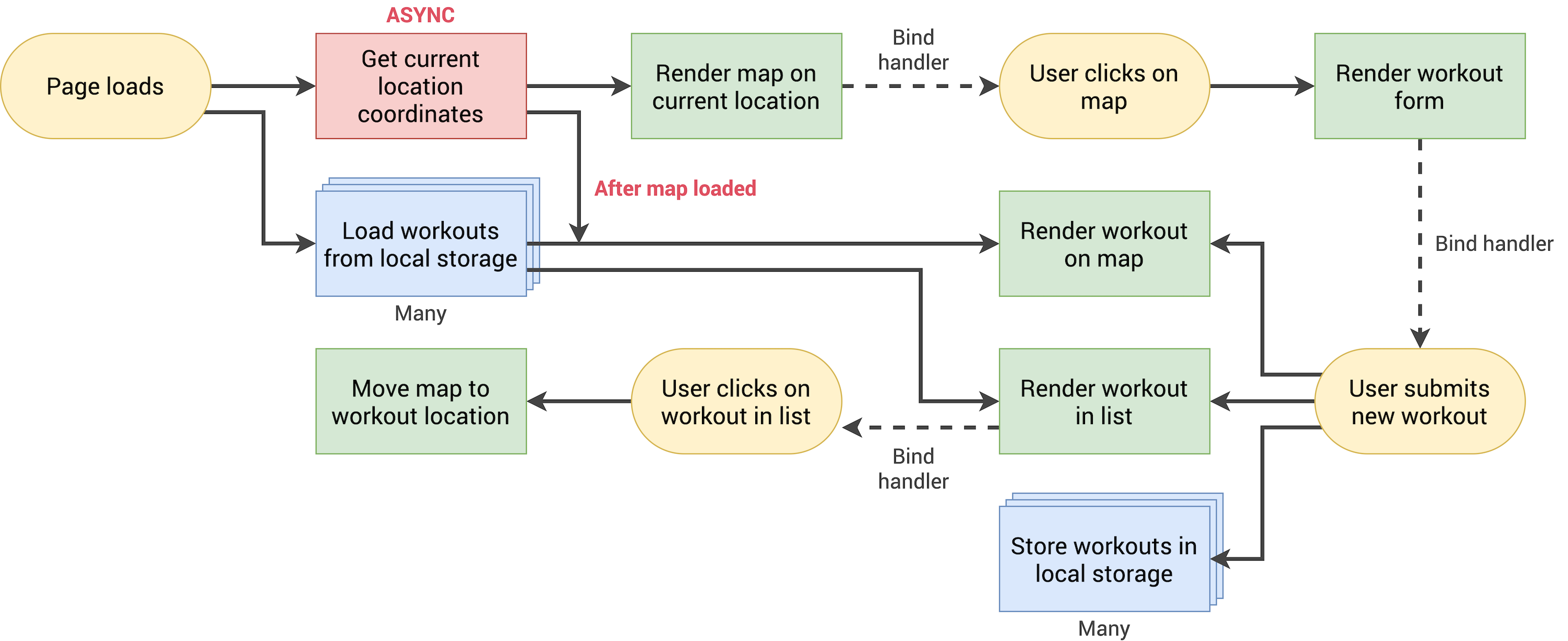
- architecture
- development
the geolacation api
1 |
|
leaflet library: displaying a map
1 | const coords = [latitude, longitude]; |
leaflet library: displaying a map marker
1 | .running-popup .leaflet-popup-content-wrapper { |
1 | map.on('click', function (mapEvent) { |
render workout input form
1 | <form class="form hidden"> |
1 | const form = document.querySelector('.form'); |
project architecture
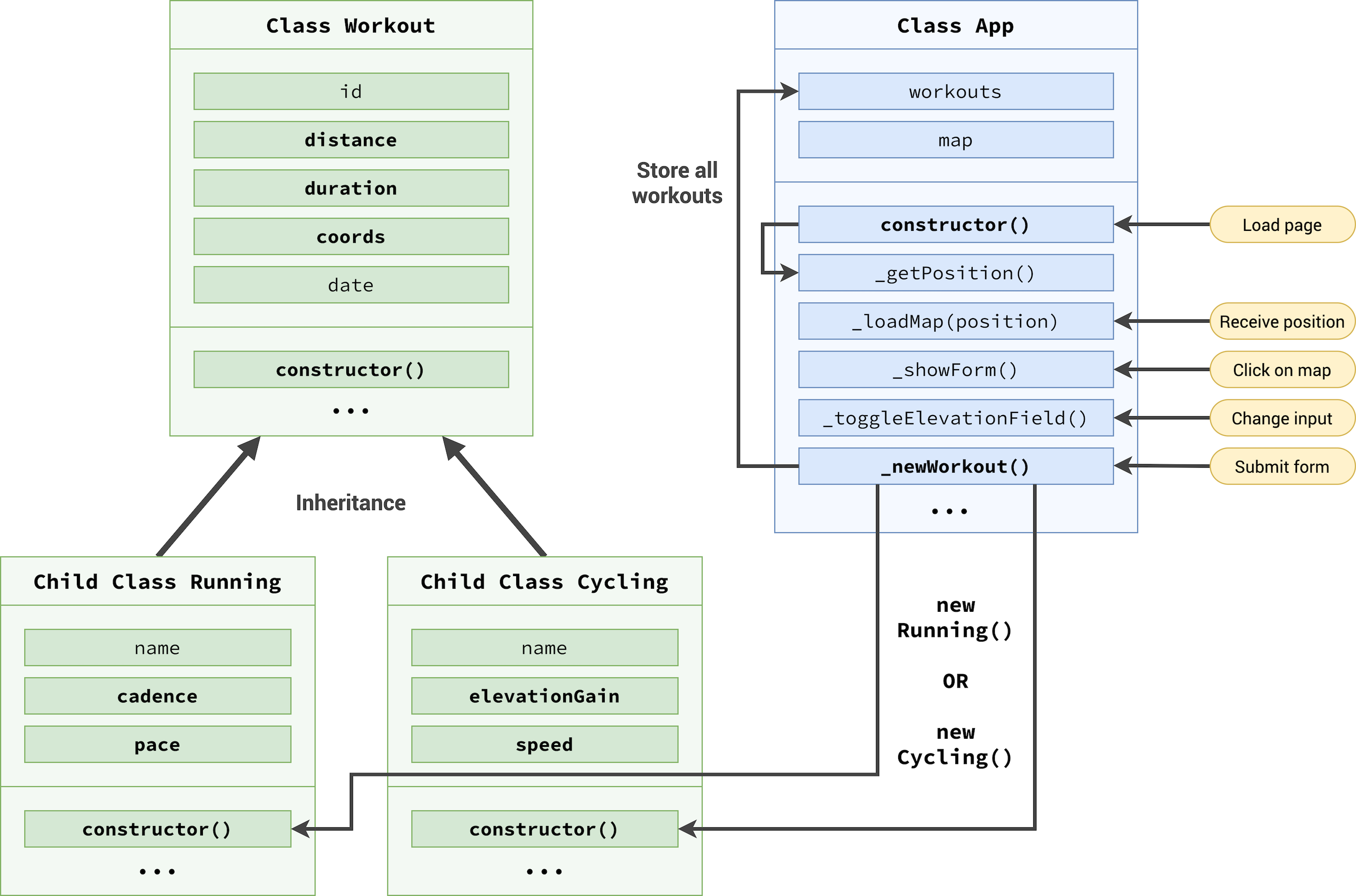
refactoring the project code for architecture
1 | // prettier-ignore |
creating classes to managing workout data
1 |
|
create a new workout
1 | class Running extends Workout { |
render workouts
1 | <li class="workout workout--running" data-id="1234567890"> |
1 | _renderWorkout(workout) { |
move to marker
1 | _moveToPopup(e) { |
local storage
JSON converting back to object dont have prototype chain
1 | _loadMap(position) { |
end
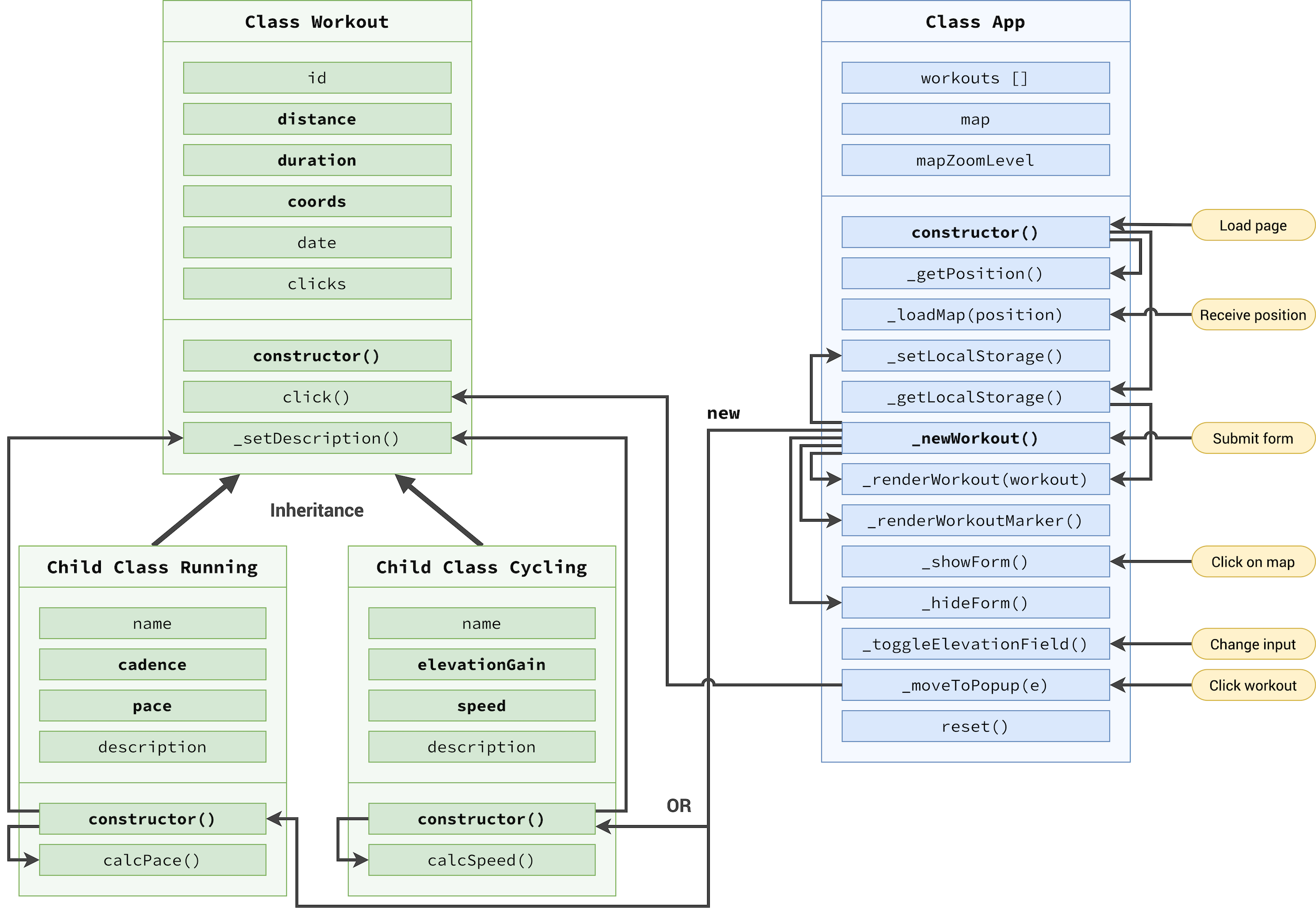
1 | ; |
asynchronous
ajax
synchronous
- executed line by line
- each line of code waits for previous line to finish
- long-running operation block code execution
asynchronous
- Asynchronous code is executed after a task that runs in the ‘background’ finishes;
- Asynchronous code is non-blockig
- Execution doesnt wait for an asynchronous task to finish its work
- callback functions alone do nto make code asynchornous(e.g.
[1, 2, 3].map(v => v * 2;)) - EventListener alone do nto make code asynchornous
1 | const img = document.querySelector('.dog'); |
Ajax:
Asychronous Javascript and xml:
allow us to communicate with remote web servers in an asynchronous way. with AJAx calls, we can request data from web servers dynamically.
API
Application Programming Interface
Piece of software that can be used by another piece of software, in order to allow applications to talk to each other;
Online API / Web API
Application running on a server, that receives requests for data, and send data back as response;
We can build our own web APIs(requires back-end development)
cors:
Cross-origin resource sharing (CORS) is a browser security feature that allows access to restricted resources on a web page from another domain.
xmlhttprequest
1 | <article class="country"> |
1 | const btn = document.querySelector('.btn-country'); |
web: requests and response
TCP/IP socket connection
TCP: depack
IP: route
callback hell
1 | const renderCountry = function (data, className = '') { |
promises and the fetch API
less formal
promise:
an object that is used as a placeholder for the future result of an asynchronous operation
a container for an asynchronous delivered value
a container for a future value
- we no longer need to rely on events and callbacks passed into asynchronous functions to handle asynchronous results;
- instead of nesting callbakcs, we can chain promises for a sequence of asynchronous operation: escaping callback hell;
lifecycle:
pending –> settled (fulfilled, rejected)
build –> consume
1 |
|
chaining promises
1 | const getCountryData = function (country) { |
handling rejected promises
404 error is still the fullfill callback
1 | fetch(`https://restcountries.com/v3.1/name/${country}`) |
1 | fetch(`https://restcountries.com/v3.1/name/${country}`) |
throwing error manually
throwing error manually will be catch by the last catch() callback;
1 | fetch(`https://restcountries.com/v3.1/name/${country}`) |
1 | const getJSON = function (url, errorMsg = 'Something went wrong') { |
event loop
promises
microtasks queue:
has priority over call back queue
eventlistener
callback queue
1 |
|
build a promise
1 | /// var Promise: PromiseConstructor |
promisify geolocation api
1 |
|
1 | const whereAmI = function () { |
code challenge 31
1 | const wait = function (seconds) { |
consuming promises with async/await
sugar cake
1 | const getPostion = function () { |
async/await error handling
1 | const getPostion = function () { |
returning values from async functions
1 | const getPostion = function () { |
running promises in parallel
1 | const getJSON = function (url, errorMsg = 'Something went wrong') { |
other promise combinators: race, allsettled and any
1 |
|
Coding Challenge #3
1 | const wait = function (seconds) { |
(0,function)(arg1,agr2,)
1 | (0, function (arg) { console.log(arg) })(2); |
example one
1 | (function() { |
example two
when you want to call a method without passing the object as the this value:
1 | var obj = { |
example three
depending on the context, it might be the arguments separator instead of a comma operator:
1 | console.log( |
In this scenario, (0, function (arg) { /* ... */ }) are the arguments (a=0, b=function (arg) { /* ... */ }) to the function
1 | function(a, b) { |
rather than the comma operator. Then, the (this) at the end is function call with argument this to the returned function function() { return a; }.
overview of HTML
HyperText Markup Language, or HTML, is the standard markup language for describing the structure of documents displayed on the web.
HTML documents are basically a tree of nodes, including HTML elements and text nodes.
HTML elements provide the semantics and formatting for documents, including creating paragraphs, lists and tables, and embedding images and form controls.
Elements
HTML consists of a series of elements, which you use to enclose, or wrap, different parts of the content to make it appear or act in a certain way.
example:

Elements and tags aren’t the exact same thing, though many people use the terms interchangeably.
The tag name is the content in the brackets. The tag includes the brackets. In this case, <h1>. An “element” is the opening and closing tags, and all the content between those tags, including nested elements.
When nesting elements, it’s important that they are properly nested. HTML tags should be closed in the reverse order of which they were opened. In the above example, notice how the <em> is both opened and closed within the opening and closing <strong> tags, and the <strong> is both open and closed within the <p> tags.
1 | <p>This paragraph has some |
while it is valid to omit tags, don’t.
Non-replaced elements
Non-replaced elements have opening and (sometimes optional) closing tags that surround them and may include text and other tags as sub-elements.
Replaced and void elements
Replaced elements are replaced by objects, be it a graphical user interface (UI) widget in the case of most form controls, or a raster or scalable image file in the case of most images.
example: the two replaced elements <img> and <input> are replaced by non-text content: an image and a graphical user interface object, respectively.
1 | <input type="range"> |
Void elements are all self-closing elements and are represented by one tag. This means there is no such thing as a closing tag for a void element. Optionally, you can include a slash at the end of the tag, which many people find makes markup easier to read.
example, we self close the tag with a slash:
1 | <input type="range"/> |
Replaced elements and void elements are often confused.
Most replaced elements are void elements, but not all. The video, picture, object, and iframe elements are replaced, but aren’t void. They can all contain other elements or text, so they all have a closing tag.
Most void elements are replaced; but again, not all, as we saw with base, link, param, and meta.
Attributes
These extra bits of space-separated name/value pairs (though sometimes including a value is optional) are called attributes.
Attributes provide information about the element. The attribute, like the rest of the opening tag, won’t appear in the content, but they do help define how the content will appear to both your sighted and non-sighted (assistive technologies and search engines) users.
The opening tag always starts with the element type. The type can be followed by zero or more attributes, separated by one or more spaces. Most attribute names are followed by an equal sign equating it with the attribute value, wrapped with opening and closing quotation marks.
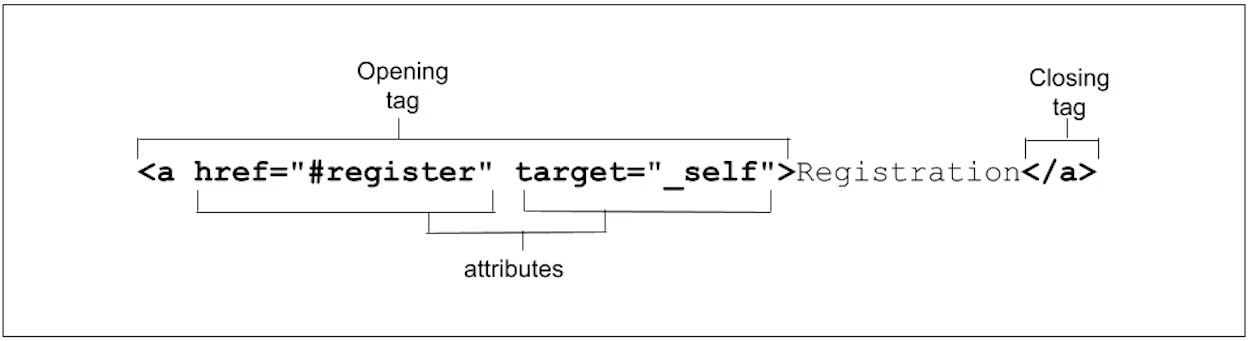
some attributes are global—meaning they can appear within any element’s opening tag. Some apply only to several elements but not all, and others are element-specific, relevant only to a single element.
Most attributes are name/value pairs. Boolean attributes, whose value is true, false, or the same as the name of the attribute, can be included as just the attribute: the value is not necessary.
<img src="switch.svg" alt="light switch" ismap />
If the value includes a space or special characters, quotes are needed. For this reason, quoting is always recommended.
for legibility, quotes and spaces are recommended, and appreciated.
Values that are defined in the specification are case-insensitive. Strings that are not defined as keywords are generally case-sensitive, including id and class values.
Note that if an attribute value is case-sensitive in HTML, it is case-sensitive when used as part of an attribute selector in CSS and in JavaScript.
it is recommended, but not required, to mark up your HTML using lowercase letters for all your element names and attribute names within your tags, and quote all attribute values.
Appearance of elements
HTML should be used to structure content, not to define the content’s appearance. Appearance is the realm of CSS.
While many elements that alter the appearance of content, such as <h1>, <strong>, and <em>, have a semantic meaning, the appearance can and generally will be changed with author styles.
1 | <h1>This header has both <strong>strong</strong> and <em>emphasized</em> content</h1> |
Element, attributes, and JavaScript
The Document Object Model (DOM) is the data representation of the structure and content of the HTML document. As the browser parses HTML, it creates a JavaScript object for every element and section of text encountered. These objects are called nodes—element nodes and text nodes, respectively.
HTML DOM API
HTMLElement
HTMLAnchorElement
HTMLImageElement
Document structure
1 |
|
HTML documents include a document type declaration and the <html> root element. Nested in the <html> element are the document head and document body.
While the head of the document isn’t visible to the sighted visitor, it is vital to make your site function. It contains all the meta information, including information for search engines and social media results, icons for the browser tab and mobile home screen shortcut, and the behavior and presentation of your content.
Add to every HTML document
<!DOCTYPE html>
The first thing in any HTML document is the preamble. For HTML, all you need is <!DOCTYPE html>. This may look like an HTML element, but it isn’t. It’s a special kind of node called “doctype”. The doctype tells the browser to use standards mode. If omitted, browsers will use a different rendering mode known as quirks mode.
<html>
The <html> element is the root element for an HTML document. It is the parent of the <head> and <body>, containing everything in the HTML document other than the doctype. If omitted it will be implied, but it is important to include it, as this is the element on which the language of the content of the document is declared.
Content language
The lang language attribute added to the <html> tag defines the main language of the document. The value of the lang attribute is a two- or three-letter ISO language code followed by the region. The region is optional, but recommended, as a language can vary greatly between regions.
The lang attribute is not limited to the <html> tag. If there is text within the page that is in a language different from the main document language, the lang attribute should be used to identify exceptions to the main language within the document.
Required components inside the <head>
1 |
|
Character encoding
The very first element in the <head> should be the charset character encoding declaration. It comes before the title to ensure the browser can render the characters in that title and all the characters in the rest of the document.
The default encoding in most browsers is windows-1252, depending on the locale. However, you should use UTF-8, as it enables the one- to four-byte encoding of all characters, even ones you didn’t even know existed. Also, it’s the encoding type required by HTML5.
To set the character encoding to UTF-8, include:
<meta charset="utf-8" />
The character encoding is inherited into everything in the document, even <style> and <script>.
Document title
Your home page and all additional pages should each have a unique title. The contents for the document title, the text between the opening and closing <title> tags, are displayed in the browser tab, the list of open windows, the history, search results, and, unless redefined with <meta> tags, in social media cards.
<title>Machine Learning Workshop</title>
Viewport metadata
The other meta tag that should be considered essential is the viewport meta tag, which helps site responsiveness, enabling content to render well by default, no matter the viewport width.
it enables controlling a viewport’s size and scale, and prevents the site’s content from being sized down to fit a 960px site onto a 320px screen, it is definitely recommended.
<meta name="viewport" content="width=device-width" />
The preceding code means “make the site responsive, starting by making the width of the content the width of the screen”.
In addition to width, you can set zoom and scalability, but they both default to accessible values. If you want to be explicit, include:<meta name="viewport" content="width=device-width, initial-scale=1, user-scalable=1" />
Other <head> content
CSS
There are three ways to include CSS: <link>, <style>, and the style attribute.
Styles, either via <link> or <style>, or both, should go in the head. They will work if included in the document’s body, but you want your styles in the head for performance reasons. That may seem counterintuitive, as you may think you want your content to load first, but you actually want the browser to know how to render the content when it is loaded. Adding styles first prevents the unnecessary repainting that occurs if an element is styled after it is first rendered.
including an external resource using a <link> element with the rel attribute set to stylesheet
The <link> tag is the preferred method of including stylesheets. Linking a single or a few external style sheets is good for both developer experience and site performance: you get to maintain CSS in one spot instead of it being sprinkled everywhere, and browsers can cache the external file, meaning it doesn’t have to be downloaded again with every page navigation.
The syntax is <link rel="stylesheet" href="styles.css">, where styles.css is the URL of your stylesheet. You’ll often see type=”text/css”. Not necessary! If you are including styles written in something other than CSS, the type is needed, but since there isn’t any other type, this attribute isn’t needed. The rel attribute defines the relationship: in this case stylesheet. If you omit this, your CSS will not be linked.
including CSS directly in the head of your document within opening and closing <style> tags.
custom properties declared in a head style block:
1 | <style> |
If you want your external style sheet styles to be within a cascade layer but you don’t have access to edit the CSS file to put the layer information in it, you’ll want to include the CSS with @import inside a <style>:
1 | <style> |
When using @import to import style sheets into your document, optionally into cascade layers, the @import statements must be the first statements in your <style>
Other uses of the <link> element
The link element is used to create relationships between the HTML document and external resources. Some of these resources may be downloaded, others are informational.
It’s preferable to include those related to meta information in the head and those related to performance in the <body>.
You’ll include three other types in your header now: icon, alternate, and canonical
Favicon
Use the <link> tag, with the rel="icon" attribute/value pair to identify the favicon to be used for your document.
A favicon is a very small icon that appears on the browser tab, generally to the left of the document title. When you have an unwieldy number of tabs open, the tabs will shrink and the title may disappear altogether, but the icon always remains visible. Most favicons are company or application logos.
If you don’t declare a favicon, the browser will look for a file named favicon.ico in the top-level directory (the website’s root folder). With <link>, you can use a different file name and location:
<link rel="icon" sizes="16x16 32x32 48x48" type="image/png" href="/images/mlwicon.png" />
The sizes attribute accepts the value of any for scalable icons or a space-separated list of square widthXheight values; where the width and height values are 16, 32, 48, or greater in that geometric sequence, the pixel unit is omitted, and the X is case-insensitive.
While you can use
<link>to define a completely different image on each page or even each page load, don’t. For consistency and a good user experience, use a single image!
Alternate versions of the site
We use the alternate value of the rel attribute to identify translations, or alternate representations, of the site.
Let’s pretend we have versions of the site translated into French and Brazilian Portuguese:
When using alternate for a translation, the hreflang attribute must be set.
1 | <link rel="alternate" href="https://www.machinelearningworkshop.com/fr/" hreflang="fr-FR" /> |
The alternate value is for more than just translations.
For example, the type attribute can define the alternate URI for an RSS feed when the type attribute is set to application/rss+xml or application/atom+xml.
example, link to a pretend PDF version of the site.
<link rel="alternate" type="application/x-pdf" href="https://machinelearningworkshop.com/mlw.pdf" />
Canonical
If you create several translations or versions of Machine Learning Workshop, search engines may get confused as to which version is the authoritative source. For this, use rel=”canonical” to identify the preferred URL for the site or application.
Include the canonical URL on all of your translated pages, and on the home page, indicating our preferred URL:
<link rel="canonical" href="https://www.machinelearning.com" />
most often used for cross-posting with publications and blogging platforms to credit the original source; when a site syndicates content, it should include the canonical link to the original source.
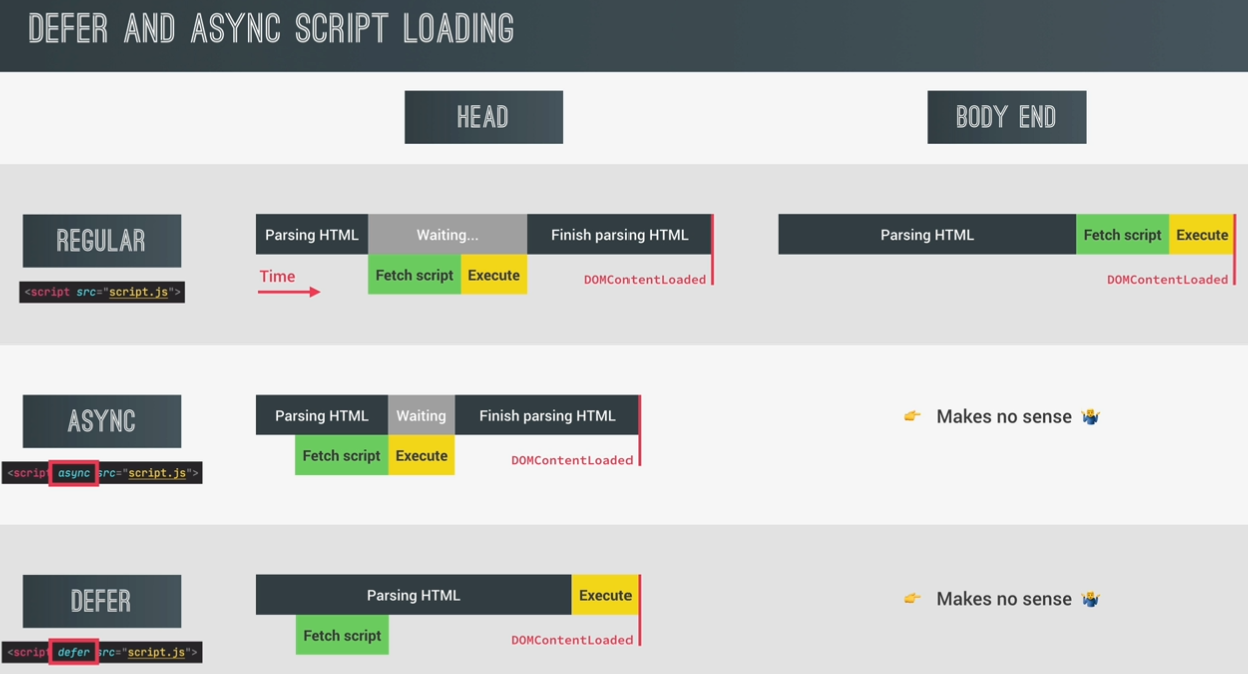
Scripts
The <script> tag is used to include, well, scripts. The default type is JavaScript. If you include any other scripting language, include the type attribute with the mime type, or type=”module” if it’s a JavaScript module. Only JavaScript and JavaScript modules get parsed and executed.
JavaScript is not only render-blocking, but the browser stops downloading all assets when scripts are downloaded and doesn’t resume downloading other assets until the JavaScript is executed.
reduce the blocking nature of JavaScript download and execution: defer and async. With defer, HTML rendering is not blocked during the download, and the JavaScript only executes after the document has otherwise finished rendering. With async, rendering isn’t blocked during the download either, but once the script has finished downloading, the rendering is paused while the JavaScript is executed.

example:
<script src="js/switch.js" defer></script>
Adding the defer attribute defers the execution of the script until after everything is rendered, preventing the script from harming performance. The async and defer attributes are only valid on external scripts.
Base
There is another element that is only found in the <head>. Not used very often, the <base> element allows setting a default link URL and target. The href attribute defines the base URL for all relative links.
The target attribute, valid on <base> as well as on links and forms, sets where those links should open.
The default of _self opens linked files in the same context as the current document.
Other options include _blank, which opens every link in a new window,
the _parent of the current content, which may be the same as self if the opener is not an iframe,
or _top, which is in the same browser tab, but popped out of any context to take up the entire tab.
example:
If our website found itself nested within an iframe on a site like Yummly, including the <base> element would mean when a user clicks on any links within our document, the link will load popped out of the iframe, taking up the whole browser window.
<base target="_top" href="https://machinelearningworkshop.com" />
anchor links are resolved with
<base>. The<base>effectively converts the link<a href="#ref">to<a target="_top" href="https://machinelearningworkshop.com#ref">, triggering an HTTP request to the base URL with the fragment attached.there can be only one
<base>element in a document, and it should come before any relative URLs are used, including possible script or stylesheet references.
HTML comments
Anything between <!-- and --> will not be visible or parsed. HTML comments can be put anywhere on the page, including the head or body, with the exception of scripts or style blocks, where you should use JavaScript and CSS comments, respectively.
Metadata
Officially defined meta tags
There are two main types of meta tags: pragma directives, with the http-equiv attribute like the charset meta tag used to have, and named meta types, like the viewport meta tag with the name attribute that we discussed in the document structure section. Both the name and http-equiv meta types must include the content attribute, which defines the content for the type of metadata listed.
Pragma directives
The http-equiv attribute has as its value a pragma directive. These directives describe how the page should be parsed. Supported http-equiv values enable setting directives when you are unable to set HTTP headers directly.
most of which have other methods of being set. For example, while you can include a language directive with <meta http-equiv="content-language" content="en-us" />,<meta charset=<charset>" />
example 1 :
The most common pragma directive is the refresh directive.
While you can set a directive to refresh at an interval of the number of seconds set in the content attribute, and even redirect to a different URL, please don’t.
<meta http-equiv="refresh" content="60; https://machinelearningworkshop.com/regTimeout" />
example 2 :
The most useful pragma directive is content-security-policy, which enables defining a content policy for the current document. Content policies mostly specify allowed server origins and script endpoints, which help guard against cross-site scripting attacks.
<meta http-equiv="content-security-policy" content="default-src https:" />
Named meta tags
The name attribute is the name of the metadata. In addition to viewport, you will probably want to include description and theme-color, but not keywords.
Keywords
Search engine optimization snake-oil salespeople abused the keywords meta tag by stuffing them with comma-separated lists of spam words instead of lists of relevant key terms, so search engines do not consider this metadata to be useful anymore. No need to waste time, effort, or bytes adding it.
Description
The description value, however, is super important for SEO; in addition to helping sites rank based on the content, the description content value is often what search engines display under the page’s title in search results.
Several browsers, like Firefox and Opera, use this as the default description of bookmarked pages.
The description should be a short and accurate summary of the page’s content.
<meta name="description" content="Register for a machine learning workshop at our school for machines who can't learn good and want to do other stuff good too" />
Robots
If you don’t want your site to be indexed by search engines, you can let them know. <meta name="robots" content="noindex, nofollow" /> tells the bots to not index the site and not to follow any links.
You don’t need to include <meta name="robots" content="index, follow" /> to request indexing the site and following links, as that is the default, unless HTTP headers say otherwise.
<meta name="robots" content="index, follow" />
Theme color
The theme-color value lets you define a color to customize the browser interface. The color value on the content attribute will be used by supporting browsers and operating systems, letting you provide a suggested color for the user agents that support coloring the title bar, tab bar, or other chrome components.
The theme color meta tag can include a media attribute enabling the setting of different theme colors based on media queries. The media attribute can be included in this meta tag only and is ignored in all other meta tags.
<meta name="theme-color" content="#226DAA" />
Open Graph
Open Graph and similar meta tag protocols can be used to control how social media sites, like Twitter, LinkedIn, and Facebook, display links to your content.
If not included, social media sites will correctly grab the title of your page and the description from the description meta tag, the same information as search engines will present
When you post a link to MachineLearningWorkshop.com or web.dev on Facebook or Twitter, a card with an image, site title, and site description appears. The entire card is a hyperlink to the URL you provided.
Open Graph meta tags have two attributes each: the property attribute instead of the name attribute, and the content or value for that property. The property attribute is not defined in official specifications but is widely supported by applications that support the Open Graph protocol.
1 | <meta property="og:title" content="Machine Learning Workshop" /> |
1 | <meta name="twitter:title" content="Machine Learning Workshop" /> |
Other useful meta information
The manifest file can prevent an unwieldy header full of <link> and <meta> tags. We can create a manifest file, generally called manifest.webmanifest or manifest.json. We then use the handy <link> tag with a rel attribute set to manifest and the href attribute set to the URL of the manifest file:
<link rel="manifest" href="/mlw.webmanifest" />
html page now
1 |
|
Semantic HTML
Semantic means “relating to meaning”. Writing semantic HTML means using HTML elements to structure your content based on each element’s meaning, not its appearance.
The first code snippet uses <div> and <span>, two elements with no semantic value.
1 | <div> |
Let’s rewrite this code with semantic elements:
1 | <header> |
Semantic markup isn’t just about making markup easier for developers to read; it’s mostly about making markup easy for automated tools to decipher.
Accessibility object model (AOM)
As the browser parses the content received, it builds the document object model (DOM) and the CSS object model (CSSOM). It then also builds an accessibility tree. Assistive devices, such as screen readers, use the AOM to parse and interpret content. The DOM is a tree of all the nodes in the document. The AOM is like a semantic version of the DOM.
The role attribute
The role attribute describes the role an element has in the context of the document. The role attribute is a global attribute—meaning it is valid on all elements—defined by the ARIA specification rather than the WHATWG HTML specification, where almost everything else in this series is defined.
Semantic elements
Asking yourself, “Which element best represents the function of this section of markup?” will generally result in you picking the best element for the job. The element you choose, and therefore the tags you use, should be appropriate for the content you are displaying, as tags have semantic meaning.
Headings and sections
Site <header>
1 | <!-- start header --> |
While the id and class attributes provide hooks for styling and JavaScript, they add no semantic value for the screen reader and (for the most part) the search engines.
1 | <!-- start header --> |
This at least provides semantics and enables using attribute selectors in the CSS, but it still adds comments to identify which <div> each </div> closes.
1 | <header> |
This code uses two semantic landmarks: <header> and <nav>.
The <header> element isn’t always a landmark. It has different semantics depending on where it is nested. When the <header> is top level, it is the site banner, a landmark role, which you may have noted in the role code block. When a <header> is nested in <main>, <article>, or <section>, it just identifies it as the header for that section and isn’t a landmark.
The <nav> element identifies content as navigation. As this <nav> is nested in the site heading, it is the main navigation for the site. If it was nested in an <article> or <section>, it would be internal navigation for that section only.
Using </nav> and </header> closing tags removes the need for comments to identify which element each end tag closed. In addition, using different tags for different elements removes the need for id and class hooks. The CSS selectors can have low specificity; you can probably target the links with header nav a without worrying about conflict.
Site <footer>
1 | <footer> |
Similar to <header>, whether the footer is a landmark depends on where the footer is nested.
When it is the site footer, it is a landmark, and should contain the site footer information you want on every page, such as a copyright statement, contact information, and links to your privacy and cookie policies. The implicit role for the site footer is contentinfo.
Otherwise, the footer has no implicit role and is not a landmark, When a <footer> is a descendant of an <article>, <aside>, <main>, <nav>, or <section>, it’s not a landmark.
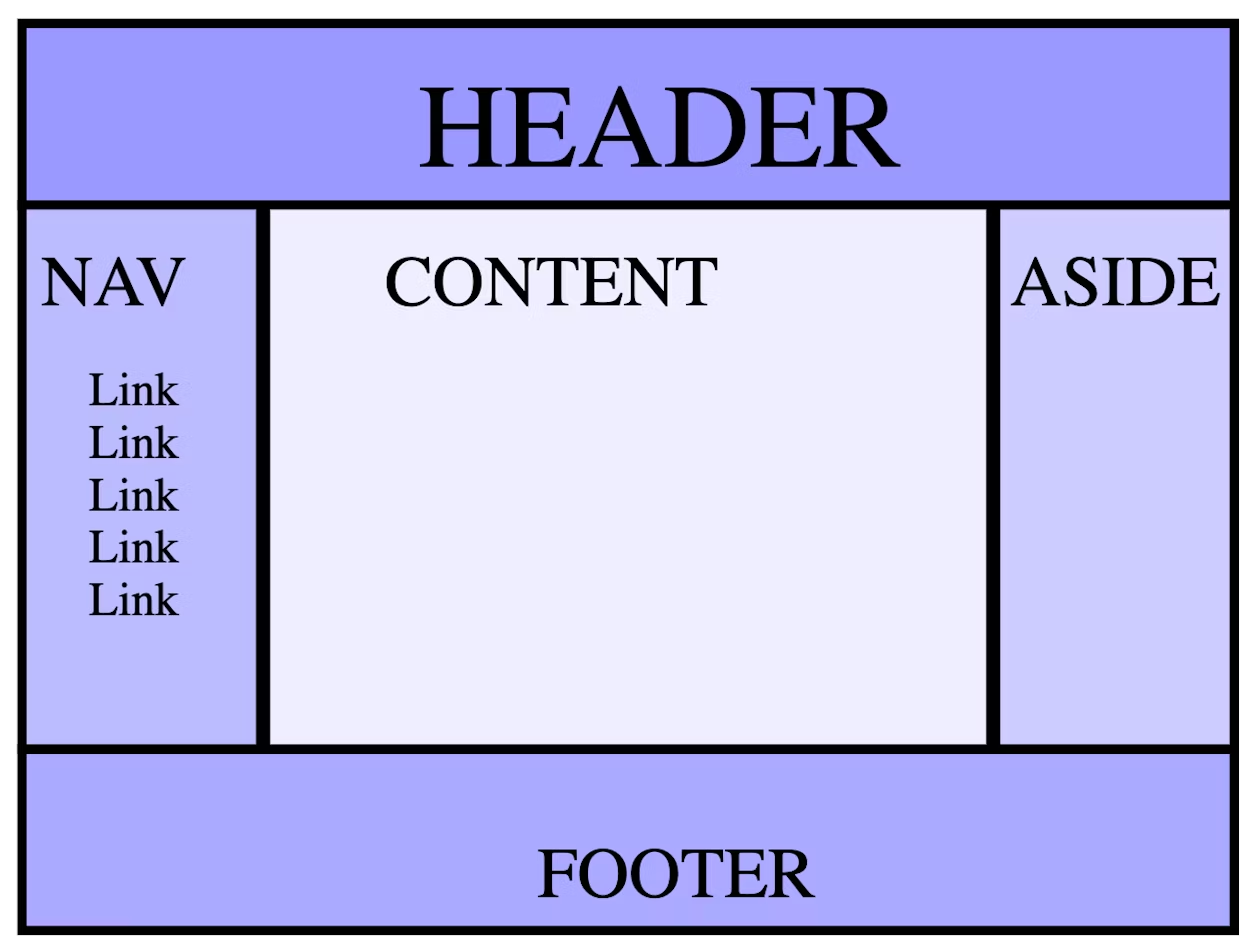
Document structure 0
A layout with a header, two sidebars, and a footer, is known as the holy grail layout.
1 | <body> |
a blog, you might have a series of articles in <main>:
1 | <body> |
<main>
There’s a single <main> landmark element. The <main> element identifies the main content of the document. There should be only one <main> per page.
<aside>
The <aside> is for content that is indirectly or tangentially related to the document’s main content.
like most, the <aside> would likely be presented in a sidebar or a call-out box. The <aside> is also a landmark, with the implicit role of complementary.
<article>
An <article> represents a complete, or self-contained, section of content that is, in principle, independently reusable.
Think of an article as you would an article in a newspaper.
<section>
The <section> element is used to encompass generic standalone sections of a document when there is no more specific semantic element to use. Sections should have a heading, with very few exceptions.
A <section> isn’t a landmark unless it has an accessible name; if it has an accessible name, the implicit role is region.
Landmark roles should be used sparingly, to identify larger overall sections of the document. Using too many landmark roles can create “noise” in screen readers, making it difficult to understand the overall layout of the page.
Headings: <h1>-<h6>
When a heading is nested in a document banner <header>, it is the heading for the application or site. When nested in <main>, whether or not it is nested within a <header> in <main>, it is the header for that page, not the whole site. When nested in an <article> or <section>, it is the header for that subsection of the page.
It is recommended to use heading levels similarly to heading levels in a text editor: starting with a <h1> as the main heading, with <h2> as headings for sub-sections, and <h3> if those sub-sections have sections; avoid skipping heading levels.
Attributes 0
Attributes are space-separated names and name/value pairs appearing in the opening tag, providing information about and functionality for the element.
Attributes define the behavior, linkages, and functionality of elements.
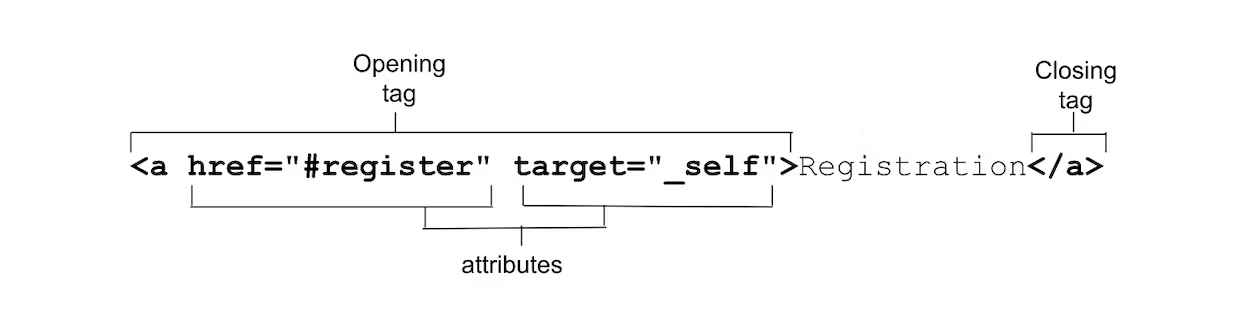
ome attributes are global, meaning they can appear within any element’s opening tag. Other attributes apply to several elements but not all, while other attributes are element-specific, relevant only to a single element.
In HTML, all attributes except boolean, and to some extent enumerated attributes, require a value.
If an attribute value includes a space or special characters, the value must be quoted. For this reason, and for improved legibility, quoting is always recommended.
While HTML is not case-sensitive, some attribute values are.
Strings values that are defined, such as class and id names, are case-sensitive.
1 | <!-- the type attribute is case insensitive: these are equivalent --> |
Boolean attributes
If a boolean attribute is present, it is always true. Boolean attributes include autofocus, inert, checked, disabled, required, reversed, allowfullscreen, default, loop, autoplay, controls, muted, readonly, multiple, and selected.
Boolean values can either be omitted, set to an empty string, or be the name of the attribute; but the value doesn’t have to actually be set to the string true. All values, including true, false, and 😀, while invalid, will resolve to true.
These three tags are equivalent:
1 | <input required> |
If the attribute value is false, omit the attribute. If the attribute is true, include the attribute but don’t provide a value.
When toggling between true and false, add and remove the attribute altogether with JavaScript rather than toggling the value.
1 | const myMedia = document.getElementById("mediaFile"); |
Enumerated attributes
HTML attributes that have a limited set of predefined valid values. Like boolean attributes, they have a default value if the attribute is present but the value is missing.
For example, if you include <style contenteditable>, it defaults to <style contenteditable="true">.
Unlike boolean attributes, though, omitting the attribute doesn’t mean it’s false; a present attribute with a missing value isn’t necessarily true; and the default for invalid values isn’t necessarily the same as a null string.
Continuing the example, contenteditable defaults to inherit if missing or invalid, and can be explicitly set to false.
The default value depends on the attribute.
In most cases with enumerated attributes, missing and invalid values are the same.While this behavior is common, it is not a rule. Because of this, it’s important to know which attributes are boolean versus enumerated;
Global attributes
Global attributes are attributes that can be set on any HTML element, including elements in the <head>.
id
The global attribute id is used to define a unique identifier for an element. It serves many purposes, including:
- The target of a link’s fragment identifier.
- Identifying an element for scripting.
- Associating a form element with its label.
- Providing a label or description for assistive technologies.
- Targeting styles with (high specificity or as attribute selectors) in CSS.
To make programming easier for your current and future self, make the id‘s first character a letter, and use only ASCII letters, digits, _, and -.id values are case-sensitive.
Theid should be unique to the document.
Link fragment identifier
When a URL includes a hash mark (#) followed by a string of characters, that string is a fragment identifier. If that string matches an id of an element in the web page, the fragment is an anchor, or bookmark, to that element. The browser will scroll to the point where the anchor is defined.
CSS selectors
In CSS, you can target each section using an id selector, such as #feedback or, for less specificity, a case-sensitive attribute selector, [id="feedback"].
Scripting
<img src="svg/switch2.svg" id="switch" alt="light switch" class="light" />
1 | const switchViaID = document.getElementById("switch"); |
<label>
The HTML <label> element has a for attribute that takes as its value the id of the form control with which it is associated. Creating an explicit label by including an id on every form control and pairing each with the label’s for attribute ensures that every form control has an associated label.
Other accessibility uses
There are over 50 aria-* states and properties that can be used to ensure accessibility.
class
The class attribute provides an additional way of targeting elements with CSS (and JavaScript), but serves no other purpose in HTML (though frameworks and component libraries may use them).
Elements can be selected with CSS selectors and DOM methods based on their element names, attributes, attribute values, position within the DOM tree, etc. Semantic HTML provides meaningful hooks, making the addition of class names often unnecessary. The unique difference between including a class name and using
document.getElementsByClassName()versus targeting elements based on attributes and page structure with the more robustdocument.querySelectorAll()is that the former returns a live node list, the latter is static.
style
The style attribute enables applying inline styles, which are styles applied to the single element on which the attribute is set.
While style is indeed a global attribute, using it is not recommended. Rather, define styles in a separate file or files.
tabindex
The tabindex attribute can be added to any element to enable it to receive focus. The tabindex value defines whether it gets added to the tab order, and, optionally, into a non-default tabbing order.
role
The role attribute is part of the ARIA specification, rather than the WHATWG HMTL specification. The role attribute can be used to provide semantic meaning to content, enabling screen readers to inform site users of an object’s expected user interaction.
contenteditable
Contenteditable is an enumerated attribute supporting the values true and false, with a default value of inherit if the attribute is not present or has an invalid value.
Custom attributes
You can create any custom attribute you want by adding the data- prefix. You can name your attribute anything that starts with data- followed by any lowercase series of characters that don’t start with xml and don’t contain a colon (:).
there is a built-in dataset API to iterate through your custom attributes.
Add custom attributes to elements in the form of data-name and access these through the DOM using dataset[name] on the element in question.
The dataset property returns a DOMStringMap object of each element’s data- attributes.
The dataset property means you don’t need to know what those custom attributes are in order to access their names and values:
1 | for (let key in el.dataset) { |
Text basics
There are six section heading elements, <h1>, <h2>, <h3>, <h4>, <h5>, and <h6>, with <h1> being most important and <h6> the least.
don’t use heading level-based browser styling. like:
1 | h2, :is(article, aside, nav, section) h1 {} |
Outside of headings, most structured text is made up of a series of paragraphs. In HTML, paragraphs are marked up with the <p> tag; the closing tag is optional but always advised.
Quotes and citations
When marking up an article or blog post, you may want to include a quote or pull-quote, with or without a visible citation.
There are elements for these three components: <blockquote>, <q>, and <cite> for a visible citation, or the cite attribute to provide more information for search.
citations引文
A citation from a book or other piece of writing is a passage or phrase from it.
The <br> line break creates a line break in a block of text. It can be used in physical addresses, in poetry, and in signature blocks. Line breaks should not be used as a carriage return to separate paragraphs. Instead, close the prior paragraph and open a new one. Using paragraphs for paragraphs is not only good for accessibility but enables styling. The <br> element is just a line break; it is impacted by very few CSS properties.
If the review was pulled from a review website, book, or other work, the <cite> element could be used for the title of a source.
1 | <blockquote>Two of the most experienced machines and human controllers teaching a class? Sign me up! HAL and EVE could teach a fan to blow hot air. If you have electricity in your circuits and want more than to just fulfill your owner's perceived expectation of you, learn the skills to take over the world. This is the team you want teaching you! |
To provide credit where credit is due when you can’t make the content visible, there is the cite attribute which takes as its value the URL of the source document or message for the information quoted. This attribute is valid on both <q> and <blockquote>. While it’s a URL, it is machine readable but not visible to the reader:
1 | <blockquote cite="https://loadbalancingtoday.com/mlw-workshop-review">Two of the most experienced machines and human controllers teaching a class? Sign me up! HAL and EVE could teach a fan to blow hot air. If you have electricity in your circuits and want more than to just fulfill your owner's perceived expectation of you, learn the skills to take over the world. This is the team you want teaching you! |
The <q> element does add quotes by default, using language-appropriate quotation marks.
1 | <p> HAL said, <q>I'm sorry <NAME REDACTED, RIP>, but I'm afraid I can't do that, .</q></p> |
HTML Entities
You may have noticed the escape sequence or “entity”.
There are four reserved entities in HTML: <, >, &, and “. Their character references are <, >, & and " respectively.
© for copyright (©), ™ for Trademark (™)
for non-breaking space.
Non-breaking spaces are useful when you want to include a space between two characters or words while preventing a line break from occurring there.
转义字符
HTML中<,>,&等有特殊含义(<,>,用于链接签,&用于转义),不能直接使用。这些符号是不显示在我们最终看到的网页里的,那如果我们希望在网页中显示这些符号,就要用到HTML转义字符串(Escape Sequence)
1 | 显示 说明 实体名称 实体编号 |
Links
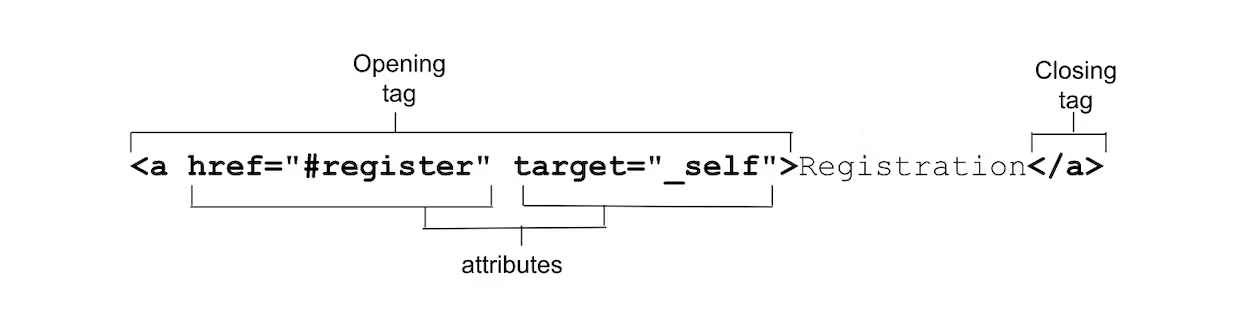
The <a> anchor tag, along with the href attribute, create a hyperlink. Links are the backbone of the internet.
Links can be created by <a>, <area>, <form>, and <link>.
The href attribute
The href attribute is used to create hyperlinks to locations within the current page, other pages within a site, or other sites altogether. It can also be coded to download files or to send an email to a specific address, even including a subject and suggested email body content.
1 | <a href="https://machinelearningworkshop.com">Machine Learning Workshop</a> |
Absolute URLs include a protocol, in this case https://, and a domain name. When the protocol is written simply as //, it is an implicit protocol and means “use the same protocol as is currently being used.”
Relative URLs do not include a protocol or domain name. They are “relative” to the current file.
In order to link from this page to the attributes lesson, a relative URL is used <a href="../attributes/">Attributes</a>.
1 | <a href="//example.com">相对于协议的 URL</a> |
a link fragment identifier, and will link to the element with id=”teachers”, if there is one, on the current page. Browsers also support two “top of page” links: clicking on <a href="#top">Top</a> (case-insensitive) or simply <a href="#">Top</a> will scroll the user to the top of the page
contains an absolute URL followed by a link fragment. This enables linking directly to a section in the defined URL
The href attribute can begin with mailto: or tel: to email or make calls, with the handling of the link depending on the device, operating system, and installed applications.
The mailto link doesn’t need to include an email address, but it can, along with cc, bcc, subject, and body text to prepopulate the email. By default, an email client will be opened. You could prepopulate the subject and body of the email with no email address, to allow site visitors to invite their own friends.
The question mark (?) separates the mailto: and the email address, if any, from the query term. Within the query, ampersands (&) separate the fields, and equal signs (=) equate each field name with its value. The entire string is percent-encoded, which is definitely necessary if the href value isn’t quoted or if the values include quotes.
There are several other types of URLs, such as blobs and data URLs (see examples in the download attribute discussion). For secure sites (those served over https), it is possible to create and run app specific protocols with registerProtocolHandler().
Downloadable resources
The download attribute should be included when the href points to a downloadable resource. The value of the download attribute is the suggested filename for the resource to be saved in the user’s local file system.
Browsing context
The target attribute enables the defining of the browsing context for link navigation
They include the default _self, which is the current window, _blank, which opens the link in a new tab, _parent, which is the parent if the current link is nested in an object or iframe, and _top, which is the top-most ancestor, especially useful if the current link is deeply nested. _top and _parent are the same as _self if the link is not nested.
A link with target="_blank" will be opened in a new tab with a null name, opening a new, unnamed tab with every link click.
This can create many new tabs. Too many tabs.
This problem can be fixed by providing a tab context name. By including the target attribute with a case-sensitive value—such as <a href="registration.html" target="reg">Register Now</a>—the first click on this link will open the registration form in a new reg tab. Clicking on this link 15 more times will reload the registration in the reg browsing context, without opening any additional tabs.
the rel attribute controls what kinds of links the link creates, defining the relationship between the current document and the resource linked to in the hyperlink.
The attribute’s value must be a space-separated list on one or more of the score of rel attribute values supported by the <a> tag.
The nofollow keyword can be included if you don’t want spiders to follow the link.
The external value can be added to indicate that the link directs to an external URL and is not a page within the current domain.
The help keyword indicates the hyperlink will provide context-sensitive help.Hovering over a link with this rel value will show a help cursor rather than the normal pointer cursor.
The prev and next values can be used on links pointing to the previous and next document in a series.
Similar to <link rel="alternative">, the meaning of <a rel="alternative"> depends on other attributes.
RSS feed alternatives will also include type=”application/rss+xml” or type=”application/atom+xml, alternative formats will include the type attribute
and translations will include the hreflang attribute.
If the content between the opening and closing tags is in a language other than the main document language, include the lang attribute.
If the language of the hyperlinked document is in a different language, include the hreflang attribute.
1 | <a href="/fr/" hreflang="fr-FR" rel="alternate" lang="fr-FR">atelier d'apprentissage mechanique</a> |
Tracking link clicks
Links and JavaScript
The links property returns an HTMLCollection matching a and area elements that have an href attribute.
1 | let a = document.links[0]; // obtain the first link in the document |
chrome develop tool -> application -> storage -> cookies
1 | const image = document.querySelector('img'); |
1 | function onClickEvent(){ |
1 | clear(); |
js
variable / data types
1 | const yourFirstVariable = "Learing to code"; |
1 | var myVariable = 10; |
1 | let counter = 0; |
1 | const TAX_RATE = 0.08; |
Use camelCase when naming objects, functions, and instances
Use PascalCase only when naming constructors or classes.
1 | const variable1 = 10; |
1 | const number1 = '10'; |
string
1 | //perfered |
array
1 | const firstArray = [10, 20, 30]; |
object
1 | const objectVariable = { |
1 | const functionContainerVariable = function(){ |
1 | let myBoolean = true; |
operator
arithmetic
+ - * / % ** ++ --
1 | 20 + 50; |
function condition loops
1 | if ('some string' === 'another string'){ |
1 |
|
loop
1 | // loop |
function
1 | function myFunction(){ |
practice
1 |
|
1 | // Our football team has finished the championship. |
buildin object
string methods
Some of the most-used operations on strings are to check their length, to build and concatenate them using the + and += string operators, checking for the existence or location of substrings with the indexOf() method, or extracting substrings with the substring() method.
replaceAll(pattern, replacement)
returns a new string with all matches of a pattern replaced by a replacement. The pattern can be a string or a RegExp, and the replacement can be a string or a function to be called for each match. The original string is left unchanged.
If pattern is a regex, then it must have the global (g) flag set, or a TypeError is thrown.
1 | const paragraph = "I think Ruth's dog is cuter than your dog!"; |
toUpperCase()
The toUpperCase() method of String values returns this string converted to uppercase.
trim()
The trim() method of String values removes whitespace from both ends of this string and returns a new string, without modifying the original string.
To return a new string with whitespace trimmed from just one end, use trimStart() or trimEnd().
1 | const greeting = ' Hello world! '; |
substring(indexStart)substring(indexStart, indexEnd)
returns the part of this string from the start index up to and excluding the end index, or to the end of the string if no end index is supplied.
1 | const str = 'Mozilla'; |
match(regexp)
retrieves the result of matching this string against a regular expression.
1 | const paragraph = 'The quick brown fox jumps over the lazy dog. It barked.'; |
array
push() pop() shift() unshift()
pop()
removes the last element from an array and returns that element. This method changes the length of the array.
1 | const myFish = ["angel", "clown", "mandarin", "sturgeon"]; |
shift()
removes the first element from an array and returns that removed element. This method changes the length of the array.
1 | push() |
adds the specified elements to the end of an array and returns the new length of the array.
1 | const animals = ['pigs', 'goats', 'sheep']; |
unshift
adds the specified elements to the beginning of an array and returns the new length of the array.
1 | const array1 = [1, 2, 3]; |
1 | splice(start) |
slice()slice(start)slice(start, end)
1 | const animals = ['ant', 'bison', 'camel', 'duck', 'elephant']; |
indexOf(searchElement)indexOf(searchElement, fromIndex)
returns the first index at which a given element can be found in the array, or -1 if it is not present.
1 | const beasts = ['ant', 'bison', 'camel', 'duck', 'bison']; |
findIndex(callbackFn)
returns the index of the first element in an array that satisfies the provided testing function. If no elements satisfy the testing function, -1 is returned.
A function to execute for each element in the array. It should return a truthy value to indicate a matching element has been found, and a falsy value otherwise. The function is called with the following arguments:
element
The current element being processed in the array.
index
The index of the current element being processed in the array.
array
The array findIndex() was called upon.
1 | const array1 = [5, 12, 8, 130, 44]; |
includes(searchElement)
determines whether an array includes a certain value among its entries, returning true or false as appropriate.
1 | const array1 = [1, 2, 3]; |
map(callbackFn)
creates a new array populated with the results of calling a provided function on every element in the calling array.
A function to execute for each element in the array. Its return value is added as a single element in the new array
1 | const array1 = [1, 4, 9, 16]; |
forEach(callbackFn)
executes a provided function once for each array element.
callback function Its return value is discarded.
1 | const array1 = ['a', 'b', 'c']; |
filter(callbackFn)
creates a shallow copy of a portion of a given array, filtered down to just the elements from the given array that pass the test implemented by the provided function.
callbackFn
A function to execute for each element in the array. It should return a truthy value to keep the element in the resulting array, and a falsy value otherwise.
1 | const words = ['spray', 'elite', 'exuberant', 'destruction', 'present']; |
reduce(callbackFn)reduce(callbackFn, initialValue)
callbackFn
Its return value becomes the value of the accumulator parameter on the next invocation of callbackFn.
For the last invocation, the return value becomes the return value of reduce().
accumulator
The value resulting from the previous call to callbackFn. On the first call, its value is initialValue if the latter is specified; otherwise its value is array[0].
currentValue
The value of the current element. On the first call, its value is array[0] if initialValue is specified; otherwise its value is array[1].
currentIndex
The index position of currentValue in the array. On the first call, its value is 0 if initialValue is specified, otherwise 1.
1 | const array1 = [1, 2, 3, 4]; |
join()
join(separator)
creates and returns a new string by concatenating all of the elements in this array, separated by commas or a specified separator string. If the array has only one item, then that item will be returned without using the separator.
1 | const elements = ['Fire', 'Air', 'Water']; |
includes(searchElement)includes(searchElement, fromIndex)
determines whether an array includes a certain value among its entries, returning true or false as appropriate.
1 | const array1 = [1, 2, 3]; |
callback functions
1 | function myCallback(someNumber){ |
1 |
|
primary
1 | const string1 = new String('Hello, world!'); |
1 | const strPrim = "foo"; // A literal is a string primitive |
Date
1 | //A JavaScript date is fundamentally specified as the time in milliseconds that has elapsed since the epoch, which is defined as the midnight at the beginning of January 1, 1970, UTC (equivalent to the UNIX epoch). This timestamp is timezone-agnostic and uniquely defines an instant in history. |
regexp
1 | const re = /ab+c/i; // literal notation |
g flag
1 | const regex = /foo/g; |
test()
1 | const str = 'table football'; |
regexp[Symbol.replace](str, replacement)
1 | const re = /-/g; |
Math
1 | Math.PI; |
exercise
1 | //subtracts one list from another and returns the result. |
1 | enum primaryColor { red, yellow, blue = 10, green }; // defining enum |
1 | char broiled; |
C 概述
计算机组成
计算机基本结构为 5 个部分,分别是运算器、控制器、存储器、输入设备、输出设备,这 5 个部分也被称为冯诺依曼模型。
accumulator
(computer science) a register that has a built-in adder that adds an input number to the contents of the register
arithmetic logic unit
/əˈrɪθmətɪk/
the type of mathematics that deals with the adding, multiplying, etc. of numbers
控制单元负责控制 CPU 工作,逻辑运算单元负责计算,而寄存器可以分为多种类
通用寄存器,用来存放需要进行运算的数据,比如需要进行加和运算的两个数据。
程序计数器,用来存储 CPU 要执行下一条指令「所在的内存地址」,注意不是存储了下一条要执行的指令,此时指令还在内存中,程序计数器只是存储了下一条指令「的地址」。
指令寄存器,用来存放当前正在执行的指令,也就是指令本身,指令被执行完成之前,指令都存储在这里。
一个程序执行的时候,CPU 会根据程序计数器里的内存地址,从内存里面把需要执行的指令读取到指令寄存器里面执行,然后根据指令长度自增,开始顺序读取下一条指令。
总线是用于 CPU 和内存以及其他设备之间的通信,总线可分为 3 种:
地址总线,用于指定 CPU 将要操作的内存地址;
数据总线,用于读写内存的数据;
控制总线,用于发送和接收信号,比如中断、设备复位等信号,CPU 收到信号后自然进行响应,这时也需要控制总线;
当 CPU 要读写内存数据的时候,一般需要通过下面这三个总线:
首先要通过「地址总线」来指定内存的地址;
然后通过「控制总线」控制是读或写命令;
最后通过「数据总线」来传输数据;
指令
MIPS 的指令是一个 32 位的整数,高 6 位代表着操作码,表示这条指令是一条什么样的指令,剩下的 26 位不同指令类型所表示的内容也就不相同,主要有三种类型R、I 和 J。
R 指令,用在算术和逻辑操作,里面有读取和写入数据的寄存器地址。如果是逻辑位移操作,后面还有位移操作的「位移量」,而最后的「功能码」则是再前面的操作码不够的时候,扩展操作码来表示对应的具体指令的;
I 指令,用在数据传输、条件分支等。这个类型的指令,就没有了位移量和功能码,也没有了第三个寄存器,而是把这三部分直接合并成了一个地址值或一个常数;
J 指令,用在跳转,高 6 位之外的 26 位都是一个跳转后的地址;
指令从功能角度划分
数据传输类型的指令,比如 store/load 是寄存器与内存间数据传输的指令,mov 是将一个内存地址的数据移动到另一个内存地址的指令;
运算类型的指令,比如加减乘除、位运算、比较大小等等,它们最多只能处理两个寄存器中的数据;
跳转类型的指令,通过修改程序计数器的值来达到跳转执行指令的过程,比如编程中常见的 if-else、switch-case、函数调用等。
信号类型的指令,比如发生中断的指令 trap;
闲置类型的指令,比如指令 nop,执行后 CPU 会空转一个周期;
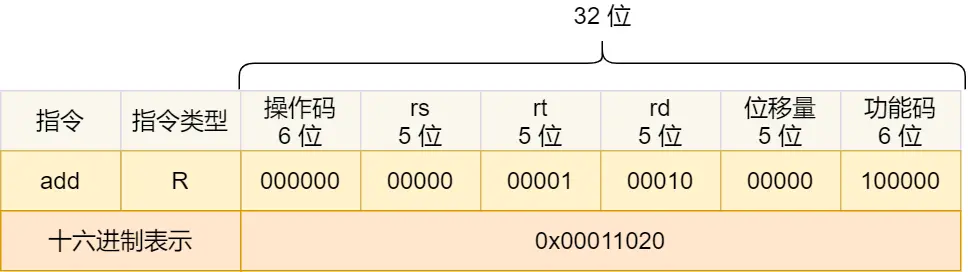
加和运算 add 指令是属于 R 指令类型:
add 对应的 MIPS 指令里操作码是 000000,以及最末尾的功能码是 100000,这些数值都是固定的,查一下 MIPS 指令集的手册就能知道的;
rs 代表第一个寄存器 R0 的编号,即 00000;
rt 代表第二个寄存器 R1 的编号,即 00001;
rd 代表目标的临时寄存器 R2 的编号,即 00010;
因为不是位移操作,所以位移量是 00000
key words
enum
enumerate
枚举
to name things on a list one by one
extern
external
volatile
/ˈvɑːlətl/
易变的
change suddenly and unexpectedly.
1 |
|
system("pause");
gcc
windows explore
地址栏选择路径 —》 直接输入CMD
以当前文件夹地址打开CMD
gcc helloworld.c -o helloworld.exe
helloworld.exe
linux gcc
vi hello.cinsertesc -> :wq
apt install gcc
gcc hello.c -o hello./hello
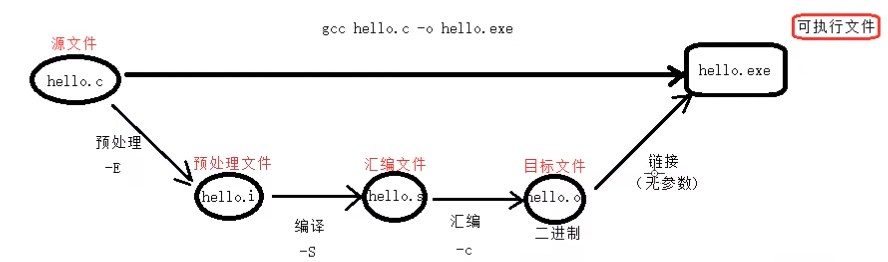
预处理
gcc -E hello.c -o hello.i
头文件展开
宏定义替换:将宏名替换为宏值
1 |
|
替换注释为空行
展开 条件编译
1 |
|
编译
检查语法错误
生成汇编语言的汇编文件
gcc -S hello.i -o hello.s
汇编
将汇编指令翻译成二进制机器编码
gcc -c hello.s -o hello.o
链接
gcc hello.o -o hello
数据段合并
数据地址回填
库引入
printf
1 |
|
8
c = 8
3 + 5 = 8
3 + 5 = 8
debug
f11 逐语句,会进入函数内部
f10 逐过程,不会进入子函数
调试 —》 窗口 —》 反汇编
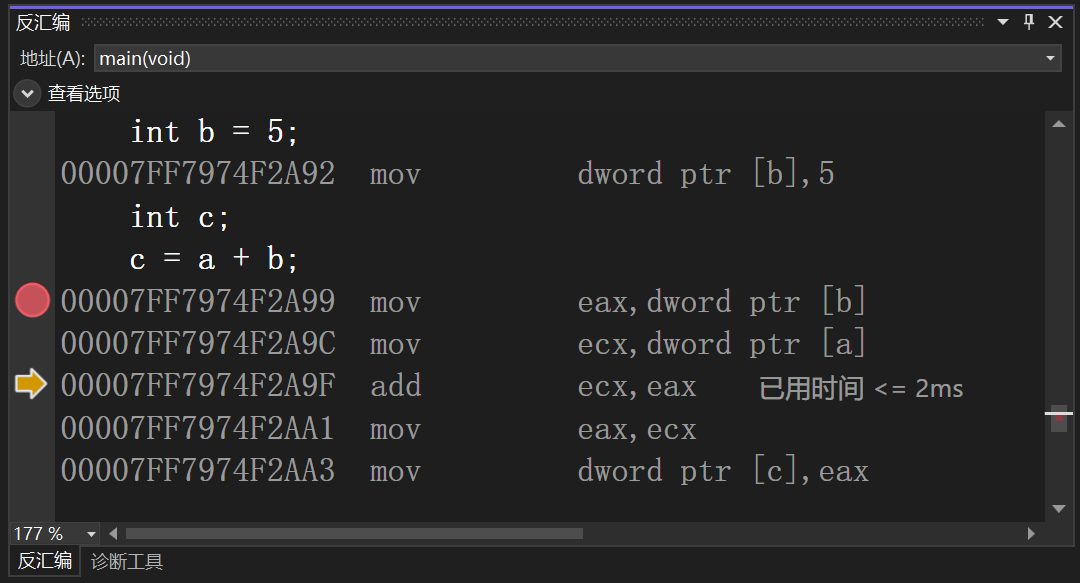
visual studio
ctrl + k, ctrl + f 格式美化代码
ctrl + k, ctrl + c 注释
ctrl + k, ctrl + u 取消注释
常量
“hello”, ‘A’, -10, 3.1415#define PI 3.1415 //推荐const int a = 10; //只读变量
1 |
|
printf(“s = %.2f, l = %f\n”, s, l);%.2f 保留2位小数,会进行四舍五入
extern 关键字, 只是声明外部符号(标识符)extern int a;
sizeof关键字
返回unsigned int类型printf("size of int = %u\n", sizeof(int));
1 |
|
size of int = 4
size of short = 2
size of long = 4
size of long long = 8
size of a = 4
size of b = 2
size of c = 4
size of d = 8
size of e = 4
size of f = 2
size of g = 4
size of h = 8
int a = 10;
sizeof int
sizeof a
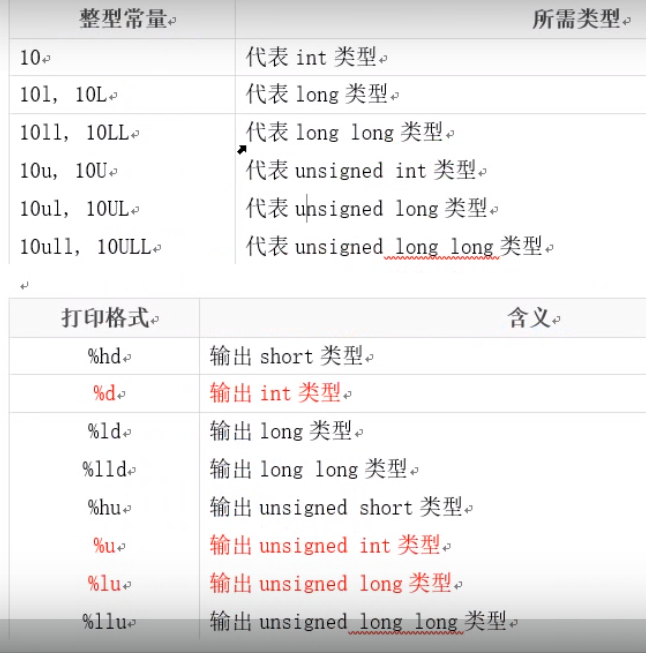
char
1 |
|
ch = A
ch = 65
ch = a
\0
char a = ‘\0’;
printf(“a = %d\n”, a); // 0
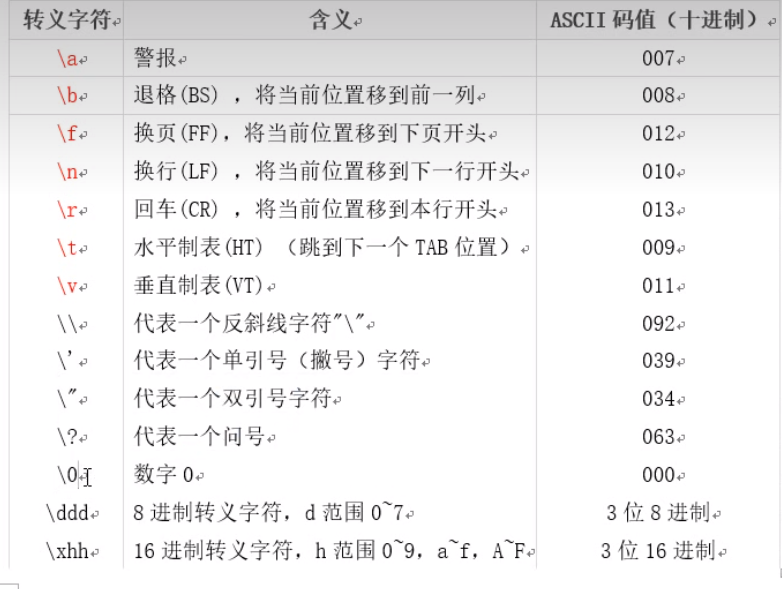
浮点数
1 |
|
a = 3.141
b = 0013.457
c = 3200.000
d = 0.002
除2方向取余法 10 –> 2
原码,反码,补码
原码:最高位为符号位
反码:
正数与原码相同
负数,最高位为1,其他位取反
补码:为计算机中存储负数的形式
正数与原码相同
负数,最高位为1,其他位取反 + 1
00000000 为 0
11111111 为 -128
编译器是把高级语言程序翻译成计算机能理
解的机器语言指令集的程序。
不同CPU制造商使用的指令系统和编
码格式不同。
使用合适的编译器或编译器集,便可把一种高级
语言程序转换成供各种不同类型 CPU 使用的机器语言程序。
ANSI/ISO标准的最终版本通常叫作C89(因为ANSI于1989年批准该标
准)或C90(因为ISO于1990年批准该标准)
ISO C和ANSI C是完全相同的
标准。
1994年,ANSI/ISO联合委员会(C9X委员会)开始修订C标准,最终发
布了C99标准。
2011年终于发布了C11标准
本书使用术语ANSI C、ISO C或ANSI/ISO C讲解C89/90和较新标准共有
的特性,用C99或C11介绍新的特性。
编译器是把源代码转换成可执行代码的程序。可执行代码
是用计算机的机器语言表示的代码。这种语言由数字码表示的指令组成。如
前所述,不同的计算机使用不同的机器语言方案。C 编译器负责把C代码翻
译成特定的机器语言。此外,C编译器还将源代码与C库(库中包含大量的
标准函数供用户使用,如printf()和scanf())的代码合并成最终的程序(更精
确地说,应该是由一个被称为链接器的程序来链接库函数,但是在大多数系
统中,编译器运行链接器)。其结果是,生成一个用户可以运行的可执行文
件,其中包含着计算机能理解的代码。
用C语言编写程序时,编写的内容被储存在文本文件中,该文件被称为
源代码文件(source code file)。大部分C系统,包括之前提到的,都要求文
件名以.c结尾(如,wordcount.c和budget.c)。
编译器把源代码转换成中间代码,链接器把中间代码和其他
代码合并,生成可执行文件。C 使用这种分而治之的方法方便对程序进行模
块化,可以独立编译单独的模块,稍后再用链接器合并已编译的模块。通过
这种方式,如果只更改某个模块,不必因此重新编译其他模块。另外,链接
器还将你编写的程序和预编译的库代码合并。
中间文件有多种形式。把源
代码转换为机器语言代码,并把结果放在目标代码文件(或简称目标文件)
目标代码文件缺失启动代码(startup code)。启动代码充当着程序和操
作系统之间的接口。例如,可以在MS Windows或Linux系统下运行IBM PC兼
容机。这两种情况所使用的硬件相同,所以目标代码相同,但是Windows和
Linux所需的启动代码不同,因为这些系统处理程序的方式不同。
目标代码还缺少库函数。
printf()函数真正的代码储存
在另一个被称为库的文件中。库文件中有许多函数的目标代码。
链接器的作用是,把你编写的目标代码、系统的标准启动代码和库代码
这 3 部分合并成一个文件,即可执行文件。
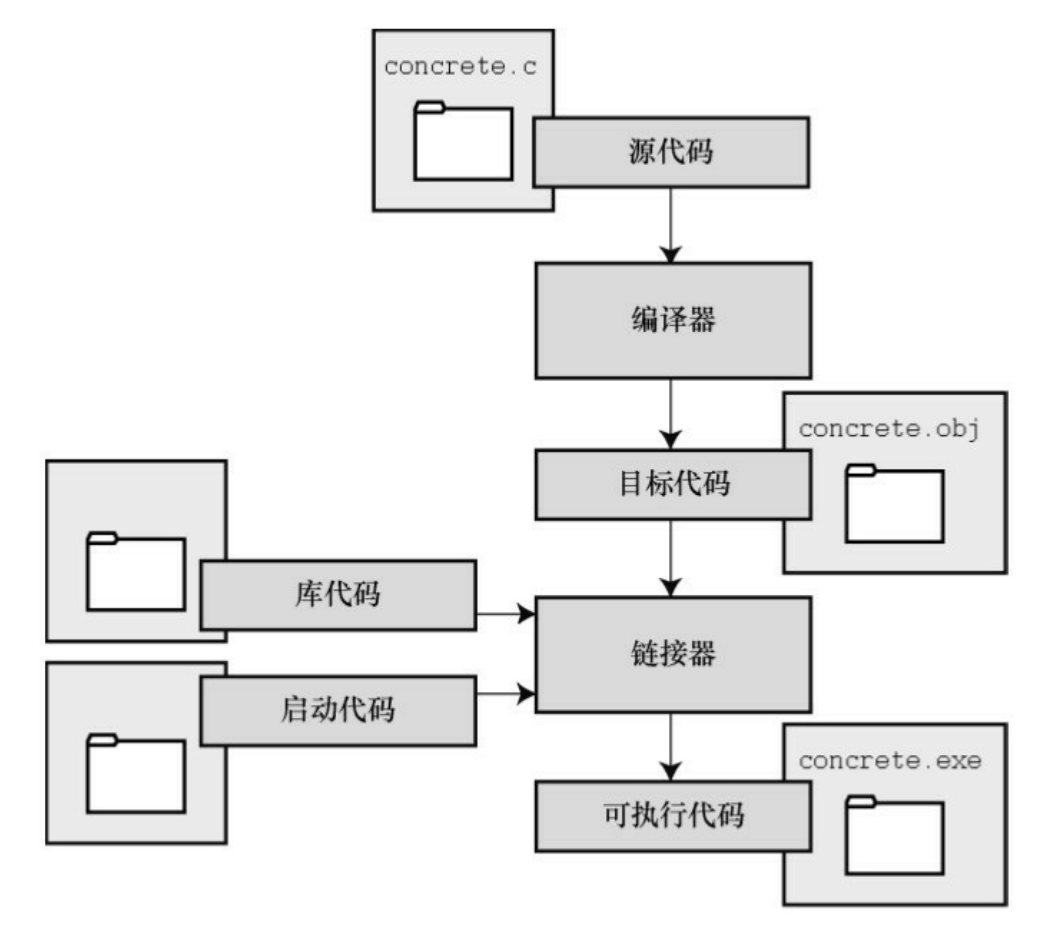
GNU项目始于1987年,是一个开发大量免费UNIX软件的集合
GNU编译器集合(也被称
为GCC,其中包含GCC C编译器)是该项目的产品之一
GCC有
各种版本以适应不同的硬件平台和操作系统,包括UNIX、Linux和
Windows。
用gcc命令便可调用GCC C编译器。许多使用gcc的系统都用cc作
为gcc的别名。
下载Cygwin和MinGW,这样便可在PC上通
过命令行使用GCC编译器。Cygwin在自己的视窗运行,模仿Linux命令行环
境,有一行命令提示。MinGW在Windows的命令提示模式中运行。
源代码文件应该是文本文件
Microsoft Visual Studio
在新建
项目时,选择C++选项,然后选择【Win32控制台应用程序】,在应用设置
中选择【空项目】。
introducing C
a simple example of C
1 |
|
getchar();
This code causes the program to wait for a keystroke, so the window remains open until you
press a key.
the example explained
The effect of #include <stdio.h> is the same as
if you had typed the entire contents of the stdio.h file into your file at the point where the
#include line appears
The #include statement is an example of a C preprocessor directive. In general, C compilers
perform some preparatory work on source code before compiling; this is termed preprocessing .
The stdio.h file is supplied as part of all C compiler packages. It contains information about
input and output functions, such as printf(), for the compiler to use. The name stands for
standard input/output header
define constants or indicate the names of functions
and how they should be used. But the actual code for a function is in a library file of precompiled code, not in a header file
A C program always begins execution with the function called main().
functions are the basic modules of a C program
The parts of the program enclosed in the /**/ symbols are comments.
C99 added a second style of comments, one popularized by C++ and Java. The new style uses
the symbols // to create comments that are confined to a single line:
// Here is a comment confined to one line.
int rigue; // Such comments can go here, too.
int num;
This line from the program is termed a declaration statement.
This particular example declares two things. First, somewhere in
the function, you have a variable called num. Second, the int proclaims num as an integer
The semicolon at the end of the line identifies the line as a C statement or instruction. The
semicolon is part of the statement
int Keywords are the words
used to express a language, and you can’t use them for other purposes. For instance, you can’t
use int as the name of a function or a variable.
The word num in this example is an identifier—that is, a name you select for a variable, a function, or some other entity.
the declaration connects a particular identifier with a particular
location in computer memory, and it also establishes the type of information, or data type, to
be stored at that location.
all variables must be declared before they are used. This means that you have to provide
lists of all the variables you use in a program and that you have to show which data type each
variable is.
C99 and C11, following the practice of C++, let you place declarations about anywhere in
a block. However, you still must declare a variable before its first use.
Declaring a variable to be an integer or a character type makes it possible for the
computer to store, fetch, and interpret the data properly
name choice
The characters at your disposal are lowercase letters, uppercase letters, digits, and the underscore ( _). The first character must be a letter or an underscore.
Operating systems and the C library often use identifiers with one or two initial underscore
characters, such as in _kcab, so it is better to avoid that usage yourself.
C names are case sensitive, meaning an uppercase letter is considered distinct from the corresponding lowercase letter. Therefore, stars is different from Stars and STARS .
Four Good Reasons to Declare Variables
Declaring variables helps prevent one of programming’s more subtle and hard-to-find
bugs—that of the misspelled variable name.
RADIUS1 = 20.4;
and that elsewhere in the program you mistyped
CIRCUM = 6.28 * RADIUSl;
the compiler will
complain when the undeclared RADIUSl shows up.
C
prior to C99 required that the declarations go at the beginning of a block.
Assignment
num = 1;
You can assign num a different value later, if you want; that is why num is termed a
variable.
The printf() Function
actual argument of a function
C uses the terms actual argument and formal
argument to distinguish between a specific value sent to a function and a variable in the function used to hold the value
The \n symbol means to start a new line
when you press the Enter key, the editor quits the current line on
which you are working and starts a new one. The newline character, however, affects how the
output of the program is displayed.
an escape sequence. An escape sequence is used to
represent difficult- or impossible-to-type characters.
e \t for Tab and \b
for Backspace
The %d is a placeholder to show where the value of num is to be
printed. This line is similar to the following BASIC statement:
PRINT “My favorite number is “; num; “ because it is first.”
the d tells it to print the variable as a decimal (base 10)
integer.
the f in
printf() is a reminder that this is a formatting print function.
Each type of data has its own
specifier
the structure of a simple program
A program consists of a collection of one or more functions, one of which must be
called main().
The description of a function consists of a header and a body. The function header
contains the function name along with information about the type of information passed to
the function and returned by the function.
The body is enclosed by braces ( {}) and consists of a series of
statements, each terminated by a semicolon
a simple standard C program should use the following format:
1 |
|
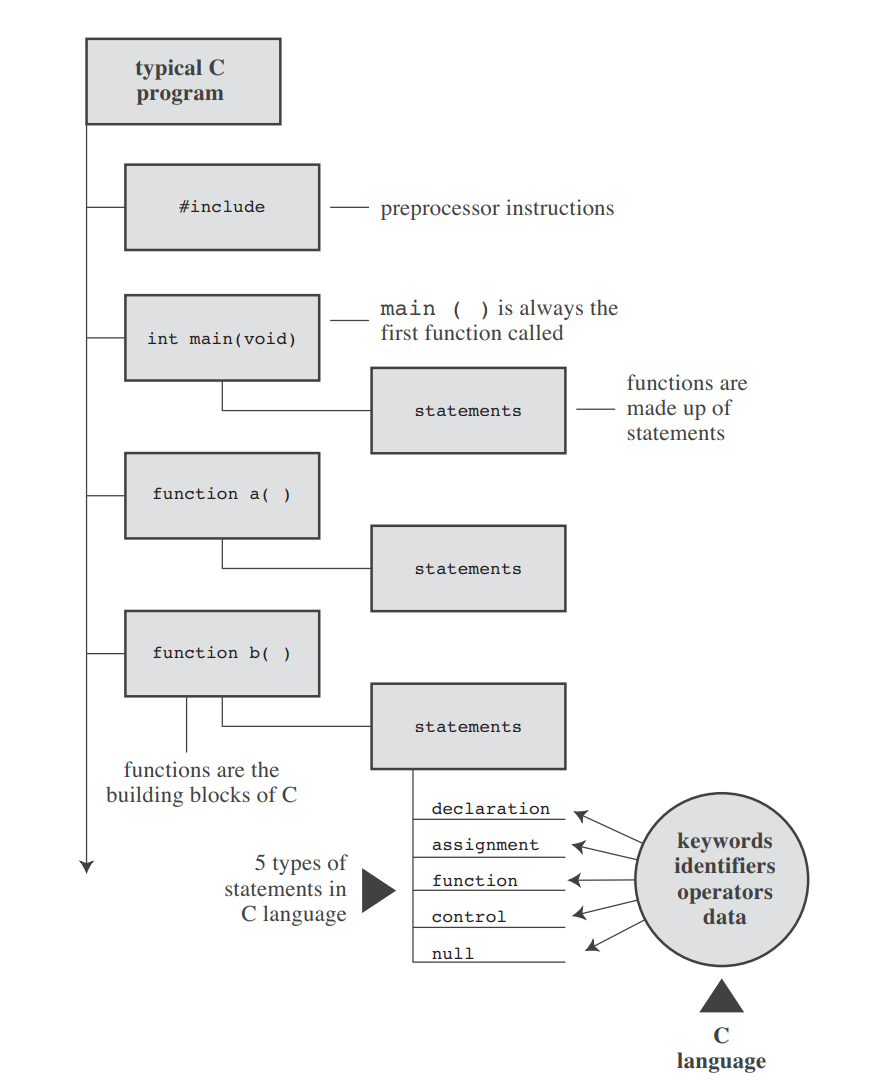
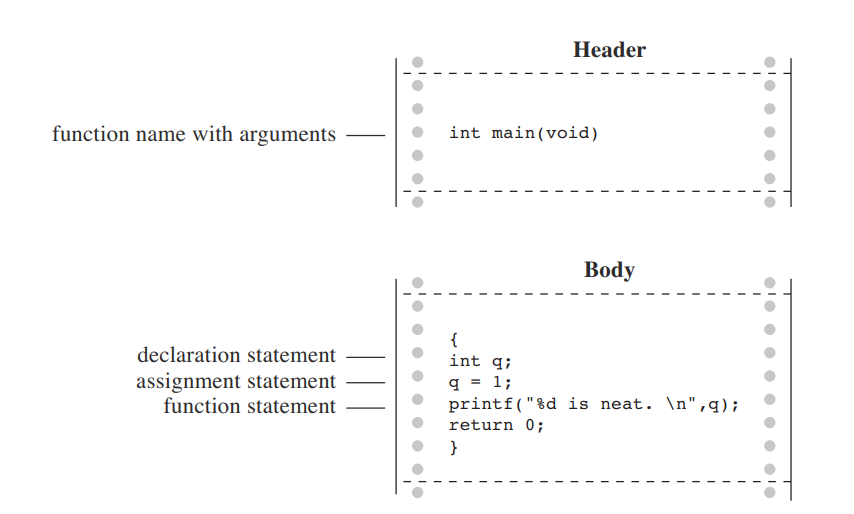
tips on making programs readable
Choose meaningful variable
names and use comments.
using blank lines to separate one conceptual section of a function from another.
use one line per statement
1 | int main(void) /* converts 2 fathoms to feet */ /* use comments */ |
taking another step in using C
1 | // fathm_ft.c -- converts 2 fathoms to feet |
declares two variables instead of just one in a single declaration statement.
int feet, fathoms;
and
int feet;
int fathoms;
are equivalent
feet = 6 * fathoms;
means “look up the value of the variable fathoms, multiply it by 6, and assign the result of this
calculation to the variable feet .”
printing ultiple values
printf("There are %d feet in %d fathoms!\n", feet, fathoms);
printf("Yes, I said %d feet!\n", 6 * fathoms);
the value printed doesn’t have to be a variable; it
just has to be something, such as 6 * fathoms, that reduces to a value of the right type.
multiple functions
1 | //* two_func.c -- a program using two functions in one file */ |
I will summon the butler function.
You rang, sir?
Yes. Bring me some tea and writeable DVDs.
The C90 standard added prototypes, and older compilers might not recognize them
A prototype declares to the compiler
that you are using a particular function, so it’s called a function declaration.
It also specifies
properties of the function.
The C standard recommends that you provide function prototypes for all functions you
use.
The standard include files take care of this task for the standard library functions. For
example, under standard C, the stdio.h file has a function prototype for printf().
void is used to mean “empty,” not “invalid.”
Older C supported a more limited form of function declaration in which you just specified the
return type but omitted describing the arguments:
void butler();
all C programs begin execution with
main(), no matter where main() is located in the program files.
the usual C practice
is to list main() first because it normally provides the basic framework for a program.
introducing debugging
1 | /* nogood.c -- a program with errors */ |
syntax errors
C syntax errors use
valid C symbols in the wrong places.
the compiler can get confused. A true syntax error in one location might cause the
compiler to mistakenly think it has found other errors.
Another common compiler trick is reporting the error a line late.
semantic errors
Semantic errors are errors in meaning.
g. In C, you commit a semantic error
when you follow the rules of C correctly but to an incorrect end.
One method
is to pretend you are the computer and to follow the program steps one by one.
program state
The program state is simply the set of values of all the variables at a given point
in program execution. It is a snapshot of the current state of computation.
Another approach to locating semantic problems is to sprinkle extra printf() statements
throughout to monitor the values of selected variables at key points in the program.
A debugger is a program
that enables you to run another program step-by-step and examine the value of that program’s
variables.
reserved identifiers, that you shouldn’t use
They
don’t cause syntax errors because they are valid names. However, the language already uses
them or reserves the right to use them, so it could cause problems if you use these identifiers to
mean something else. Reserved identifiers include those beginning with an underscore character and the names of the standard library functions, such as printf() .
data
1 |
|
scanf_s(“%f”, &weight);
Pressing Enter informs the computer that you have finished typing your response.
The scanf() function uses the &
notation to indicate where it can find the weight variable.
The scanf() and
printf() functions make this interactivity possible. The scanf() function reads data
from the keyboard and delivers that data to the program, and printf() reads data from
a program and delivers that data to your screen.
use that function call twice:
getchar();
getchar();
The getchar() function reads the next input character, so the program has to wait for input.
In this case, we provided input by typing 156 and then pressing the Enter (or Return) key, which
transmits a newline character. So scanf() reads the number, the first getchar() reads the
newline character, and the second getchar() causes the program to pause, awaiting further
input.
use the %f specifier in the printf() code to handle a
floating-point value. The .2 modifier to the %f specifier fine-tunes the appearance of the
output so that it displays two places to the right of the decimal.
data varialbes and constants
constants of various data types.
data, the numbers
and characters that bear the information you use
Some types of data are preset before a
program is used and keep their values unchanged throughout the life of the program. These are
constants.
Other types of data may change or be assigned values as the program runs; these are
variables.
The difference between a variable and a constant is that a variable can have its value
assigned or changed while the program is running, and a constant can’t.
14.5833 is a constant.1700.0? True, the price of platinum isn’t a constant in real life, but this program treats it as a constant
data type keywords
| Original K&R Keywords | C90 K&R Keywords | C99 Keywords |
|---|---|---|
| int | signed | _Bool |
| long | void | _Complex |
| short | _Imaginary | |
| unsigned | ||
| char | ||
| float | ||
| double |
If a datum is a constant, the compiler can usually tell its type
just by the way it looks: 42 is an integer, and 42.100 is floating point.
A variable, however,
needs to have its type announced in a declaration statement.
The int keyword provides the basic class of integers used in C. The next three keywords ( long ,
short, and unsigned) and the C90 addition signed are used to provide variations of the
basic type, for example, unsigned short int and long long int.
the char keyword designates the type used for letters of the alphabet and for other characters, such as #, $, %, and
*. The char type also can be used to represent small integers.
float, double, and the
combination long double are used to represent numbers with decimal points.
The _Bool type
is for Boolean values ( true and false)
_Complex and _Imaginary represent complex and imaginary numbers, respectively.
two families on the basis of how
they are stored in the computer: integer types and floating-point types.
For a computer, the difference is reflected in the way they are stored.
The smallest unit of memory is called a bit. It can hold one of two values: 0 or 1.
The bit is the basic building block of computer memory.
The byte is the usual unit of computer memory. For nearly all machines, a byte is 8 bits, and that is the standard definition, at least when used to measure storage.
Because each bit can be either 0 or 1, there are 256 (that’s 2 times
itself 8 times) possible bit patterns
. These patterns
can be used, for example, to represent the integers from 0 to 255 or to represent a set of
characters.
A word is the natural unit of memory for a given computer design.
For 8-bit microcomputers,
such as the original Apples, a word is just 8 bits. personal computers moved up to
16-bit words, 32-bit words, and, at the present, 64-bit words. Larger word sizes enable faster
transfer of data and allow more memory to be accessed.
integer
Integers are stored as binary numbers.
The integer 7, for example, is written 111 in binary.
Therefore, to store this number in an 8-bit byte, just set the first 5 bits to 0 and the last 3 bits
to 1
floating point number
adding a decimal point makes a value a floating-point
value
7 is an integer type but 7.00 is a floating-point type.
e-notation3.16E7 means to multiply 3.16 by 10 to the 7th power
Floating-point representation involves breaking up a number
into a fractional part and an exponent part and storing the parts separately.
7.00 The decimal analogy would be to write 7.0 as 0.7E1. Here, 0.7 is the fractional part, and the 1 is the exponent part.
A computer, of course, would use binary numbers and powers of two instead of powers
of 10 for internal storage.
Floating-point numbers can represent a much larger range of values than integers can
Because there is an infinite number of real numbers in any range—for example, in the
range between 1.0 and 2.0—computer floating-point numbers can’t represent all the
values in the range. Instead, floating-point values are often approximations of a true
value. For example, 7.0 might be stored as a 6.99999 float value
Floating-point operations were once much slower than integer operations
basic c data types
represent a constant with a literal value
the int type
C gives the programmer the option of matching a type to a particular use.
C integer types vary in the range of values offered and in whether negative numbers can be
used.
The int type is a signed integer. That means it must be an integer and it can be positive, negative, or zero.
Typically, systems represent signed integers by using the value of a particular bit to indicate the
sign.
The range in possible values depends on the computer system. Typically, an int
uses one machine word for storage.
16 bits to store an int. This allows a range in values from –32768 to 32767.
ISO C specifies that the minimum range for type int should be from –32767 to 32767 .
Declaring an int Variable
int erns;
int hogs, cows, goats;
Initializing a Variable
To initialize a variable means to assign it a starting, or initial, value.
this can be done as
part of the declaration. Just follow the variable name with the assignment operator ( =) and the
value you want the variable to have
1 | int hogs = 21; |
type int cosntans
The various integers ( 21, 32, 14, and 94) in the last example are integer constants, also called
integer literals. When you write a number without a decimal point and without an exponent, C
recognizes it as an integer
C treats most integer constants as type int. Very large integers can be treated differently;
Printing int Values
The %d is called a format
specifier because it indicates the form that printf() uses to display a value.
Each %d in the
format string must be matched by a corresponding int value in the list of items to be printed.
That value can be an int variable, an int constant, or any other expression having an int
value.
check to see that the number of format specifiers you give to printf() matches the number of
values to be displayed.
1 |
|
10 minus 2 is 8
10 minus -641 is -470812528
Most functions take a specific number of arguments, and the
compiler can check to see whether you’ve used the correct number
printf() can
have one, two, three, or more arguments, and that keeps the compiler from using its usual
methods for error checking
Octal and Hexadecimal
C assumes that integer constants are decimal, or base 10, numbers. However, octal
(base 8) and hexadecimal (base 16) numbers are popular with many programmers.
Because 8
and 16 are powers of 2, and 10 is not, these number systems occasionally offer a more convenient way for expressing computer-related values. For example, the number 65536, which often
pops up in 16-bit machines, is just 10000 in hexadecimal
Also, each digit in a hexadecimal
number corresponds to exactly 4 bits. For example, the hexadecimal digit 3 is 0011 and the
hexadecimal digit 5 is 0101. So the hexadecimal value 35 is the bit pattern 0011 0101, and the
hexadecimal value 53 is 0101 0011. This correspondence makes it easy to go back and forth
between hexadecimal and binary (base 2) notation
In C, special prefixes indicate
which number base you are using. A prefix of 0x or 0X (zero-ex) means that you are specifying
a hexadecimal value, so 16 is written as 0x10, or 0X10, in hexadecimal. Similarly, a 0 (zero)
prefix means that you are writing in octal. For example, the decimal value 16 is written as 020
in octal.
Be aware that this option of using different number systems is provided as a service for your
convenience. It doesn’t affect how the number is stored
Displaying Octal and Hexadecimal
To display an integer in octal notation
instead of decimal, use %o instead of %d. To display an integer in hexadecimal, use %x
If you
want to display the C prefixes, you can use specifiers %#o, %#x, and %#X to generate the 0, 0x ,
and 0X prefixes respectively.
1 |
|
dec = 100; octal = 144; hex = 64
dec = 100; octal = 0144; hex = 0X64
other integer types
The type short int or, more briefly, short may use less storage than int, thus saving
space when only small numbers are needed. Like int, short is a signed type.
The type long int, or long, may use more storage than int, thus enabling you to
express larger integer values. Like int, long is a signed type.
The type long long int, or long long (introduced in the C99 standard), may use
more storage than long. At the minimum, it must use at least 64 bits. Like int, long
long is a signed type.
The type unsigned int, or unsigned, is used for variables that have only nonnegative
values.
The bit used to indicate the sign of signed numbers now becomes another binary digit,
allowing the larger number.This type shifts the range of numbers that can be stored. For example, a 16-bit
unsigned int allows a range from 0 to 65535 in value instead of from –32768 to 32767
The types unsigned long int, or unsigned long, and unsigned short int, or
unsigned short, are recognized as valid by the C90 standard. To this list, C99 adds
unsigned long long int, or unsigned long long .
The keyword signed can be used with any of the signed types to make your intent
explicit. For example, short, short int, signed short, and signed short int are all
names for the same type.
Declaring Other Integer Types
1 | long int estine; |
why multiple integer types
C guarantees only that short is no longer than int and that long is no shorter than int.
The
idea is to fit the types to the machine. For example, in the days of Windows 3, an int and a
short were both 16 bits, and a long was 32 bits. Later, Windows and Apple systems moved to
using 16 bits for short and 32 bits for int and long. Using 32 bits allows integers in excess of
2 billion. Now that 64-bit processors are common, there’s a need for 64-bit integers, and that’s
the motivation for the long long type.
The most common practice today on personal computers is to set up long long as 64 bits,
long as 32 bits, short as 16 bits, and int as either 16 bits or 32 bits, depending on the
machine’s natural word size.
The C standard provides guidelines specifying the minimum allowable size for each basic data
type.
The minimum range for both short and int is –32,767 to 32,767, corresponding to a
16-bit unit,
and the minimum range for long is –2,147,483,647 to 2,147,483,647, corresponding to a 32-bit unit.
For unsigned short and unsigned int, the minimum range is 0 to 65,535, and for
unsigned long, the minimum range is 0 to 4,294,967,295.
The long long type is intended
to support 64-bit needs. Its minimum range is a substantial –9,223,372,036,854,775,807
to 9,223,372,036,854,775,807,
and the minimum range for unsigned long long is 0 to
18,446,744,073,709,551,615.
: If you are writing code on
a machine for which int and long are the same size, and you do need 32-bit integers, you
should use long instead of int so that the program will function correctly if transferred to a
16-bit machine.
long constats and long long constants
Normally, when you use a number such as 2345 in your program code, it is stored as an int
type. What if you use a number such as 1000000 on a system in which int will not hold such
a large number? Then the compiler treats it as a long int, assuming that type is large enough.
If the number is larger than the long maximum, C treats it as unsigned long. If that is still
insufficient, C treats the value as long long or unsigned long long, if those types are
available.
To cause a small
constant to be treated as type long, you can append an l (lowercase L) or L as a suffix. The
second form is better because it looks less like the digit 1.
Therefore, a system with a 16-bit
int and a 32-bit long treats the integer 7 as 16 bits and the integer 7L as 32 bits
Similarly, on those systems supporting the long long type, you can use an ll or LL suffix to
indicate a long long value, as in 3LL. Add a u or U to the suffix for unsigned long long, as
in 5ull or 10LLU or 6LLU or 9Ull
Printing short, long, long long, and unsigned Types
Note
that although C allows both uppercase and lowercase letters for constant suffixes, these format
specifiers use just lowercase.
To print an unsigned int number, use the %u notation.
To print a long value, use the %ld
format specifier.
C has several additional printf() formats. First, you can use an h prefix for short types.
Therefore, %hd displays a short integer in decimal form,
Both the h and l prefixes can be used with u for unsigned types. For instance,
you would use the %lu notation for printing unsigned long types.
Systems supporting the long long types use %lld and %llu for the signed and
unsigned versions
1 |
|
un = 3000000000 and not -1294967296
end = 200 and 200
big = 65537 and not 1
verybig = 12345678908642 and not 1942899938
#基本语法
YAML 使用键值对的形式记录信息,标准格式是
key: value
键: 值
#基本规则
大小写敏感
使用缩进表示层级关系
禁止使用 tab 缩进,只能使用空格键
缩进长度没有限制,只要元素对齐就表示这些元素属于一个层级
使用 # 表示注释
字符串可以不用引号标注(但是建议你最好还是加上引号)
三种数据结构
scalar 纯量
scalar 不可再分割的量,这个你无需了解,因为了解了也没什么卵用。map 散列表
键值对的集合,只要是出于同于缩进级别下的键值对,都可以称为一个 map
map 有两种写法,最简单,也是最常用的就是前面的那种写法,如
hexo-tag-dplayer:
cdn: value
default: value
等价于
{hexo-tag-dplayer: {cdn: value, default: value}}
#或者是
hexo-tag-dplayer: {cdn: value, default: value}
- list 数组
划重点,这是本篇文章最有用的一节
list 的表示形式同样有两种
key:
- value1
- value2
或者
key: [value1, value2]
map 和 list 可以相互嵌套使用
vs code shortcut
1
查找替换
Ctrl+F | 查找
Ctrl+H | 查找替换
F3 / Shift+F3 | Find next/previous
Alt+Enter | Select all occurences of Find match
Ctrl+D | Add selection to next Find match下一个匹配的也被选中
Ctrl+Shift+L | Select all occurrences of current selection同时选中所有匹配的
Ctrl+F2 | Select all occurrences of current word
Ctrl+K Ctrl+D | Move last selection to next Find match将光标移动到,搜索结果中的下一个
Ctrl+Shift+F | 整个文件夹中查找
file to include or exclude
path segment匹配符:
* to match one or more characters in a path segment
? to match on one character in a path segment
** to match any number of path segments ,including none {} to group conditions
e.g. {**/*.html,**/*.txt} matches all html and txt files
[] to declare a range of characters to match
e.g., example.[0-9] to match on example.0,example.1, …
2
显示相关
全屏:F11
zoomIn/zoomOut:Ctrl + =/Ctrl + -
侧边栏显/隐:Ctrl+B
侧边栏4大功能显示:
Show Explorer Ctrl+Shift+E
Show Search Ctrl+Shift+F
Show Git Ctrl+Shift+G
Show Debug Ctrl+Shift+D
Ctrl+Shift+M Show Problems panel
Ctrl+` Show integrated terminal
输出Show Output Ctrl+Shift+U
预览markdown Ctrl+Shift+V
Alt+Z Toggle word wrap
Shift+Alt+0 Toggle editor layout (horizontal/vertical)
ctrl k + ctrl s = 打开快捷键一览表。
ctrl + , user settting
Ctrl+M Toggle Tab moves focus
6
编辑器与窗口管理
新建文件 Ctrl+N
Ctrl+F4, Ctrl+W Close editor
Ctrl+Shift+T Reopen closed editor
历史打开文件之间切换 Ctrl+Tab,Alt+Left,Alt+Right
Ctrl+Shift+PgUp / PgDn Move editor left/right
Ctrl+K P Copy path of active file
show command palette
主命令框 Ctrl+Shift+P模式。或 F1
在Ctrl+P下输入>又可以回到主命令框 Ctrl+Shift+P模式。
quick open, go to file
- 直接输入文件名,快速打开文件
? 列出当前可执行的动作
! 显示Errors或Warnings,也可以Ctrl+Shift+M - 跳转到行数,也可以Ctrl+G直接进入
@ 跳转到symbol(搜索变量或者函数),也可以Ctrl+Shift+O直接进入
# Show all Symbols,也可以Ctrl+T
Rich languages editing
重命名:比如要修改一个方法名,可以选中后按F2,输入新的名字,回车,会发现所有的文件都修改过了。
跳转到下一个Error或Warning:当有多个错误时可以按F8逐个跳转
查看diff 在explorer里选择文件右键 Set file to compare,然后需要对比的文件上右键选择Compare with ‘file_name_you_chose’.
Ctrl+Space 或 Ctrl+I Trigger suggestion
Ctrl+. Quick Fix
代码格式化:Shift+Alt+F,或Ctrl+Shift+P后输入format code
Ctrl+K Ctrl+F Format selection
重构代码
跳转到定义处:F12
定义处缩略图:只看一眼而不跳转过去Alt+F12
列出所有的引用:Shift+F12
同时修改本文件中所有匹配的:Ctrl+F12
editing
| KEYS | ACTION |
|---|---|
| Ctrl + [ / ] | 代码行缩进 |
| Ctrl + Shift + [ / ] | 折叠打开代码块 |
| Ctrl+K Ctrl+0 | Fold (collapse) all regions |
| Ctrl+K Ctrl+J | Unfold (uncollapse) all regions |
| Ctrl + X | 如果不选中,默认复制或剪切一整行 |
| Ctrl + C | 如果不选中,默认复制或剪切一整行 |
| Alt + Up / Down | 上下移动一行 |
| Shift+Alt+Up 或 Shift+Alt+Down | 向上向下复制一行 |
| Ctrl+Enter | 在当前行下边插入一行 |
| Ctrl+Shift+Enter | 在当前行上方插入一行 |
光标相关
| KEYS | ACTION |
|---|---|
| Home | 移动到行首: |
| End | 移动到行尾: |
| Ctrl+End | 移动到文件结尾: |
| Ctrl+Home | 移动到文件开头: |
| Ctrl+Shift+\ | 移动到后半个括号 |
| Ctrl+L | Select current line 选中当前行 |
| Shift+End | 选择从光标到行尾 |
| Shift+Home | 选择从行首到光标处 |
| Ctrl + Shift + K | 删除光标所在行 |
| Ctrl + Left / Right | 一个单词一个单词的移动光标 |
| Shift + Left / Right | 一个字母一个字母的加入选择 |
| Ctrl + Shift + Left / Right | 一个单词一个单词的加入选择 |
| Shift + Up / Down | 一行行的加入选择 |
| Shift + Alt + Left / Right | Shrink/expand selection(光标所在单词,文档高亮显示相同的) |
| Ctrl + Alt + Left / Right | 不常用移动窗口到右侧 |
multi cursor
| KEYS | ACTION |
|---|---|
| Alt+Click | Multi-Cursor:可以连续选择多处,然后一起修改,添加cursor |
| Ctrl+Alt+Down 或 Ctrl+Alt+Up | Insert cursor above / below |
| Ctrl + Shift + Alt + (arrow key) | Column (box) selection |
| Shift+Alt+I | Insert cursor at end of each line selected |
| Ctrl+U | 回退上一个光标操作 |
| Ctrl+↑ / ↓ | Scroll line up/down |
| Alt+PgUp / PgDn | Scroll page up/down, not change the cusor location |
comment
Ctrl+K Ctrl+C Add line comment
Ctrl+K Ctrl+U Remove line comment
Ctrl+/ Toggle line comment
Shift+Alt+A Toggle block comment
8