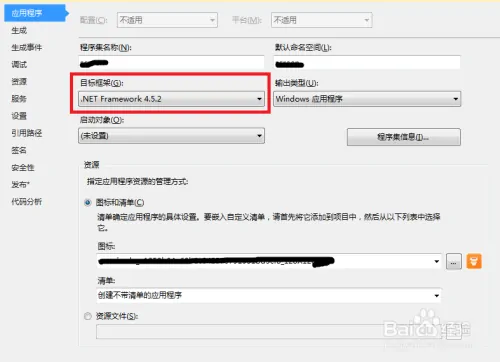
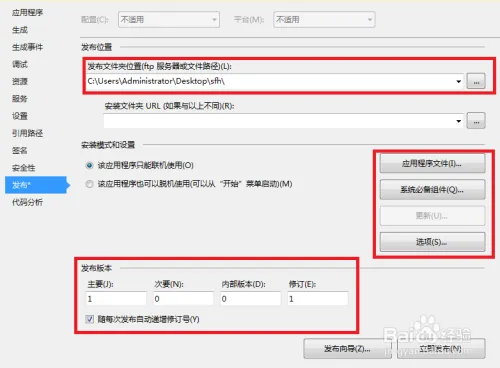
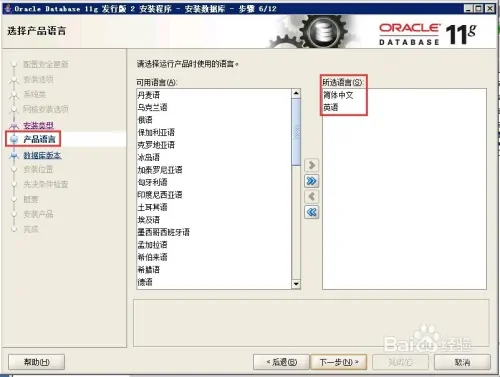
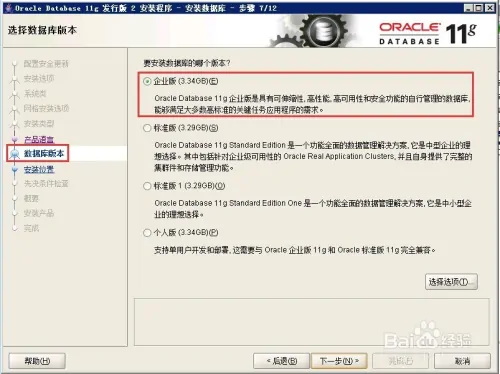
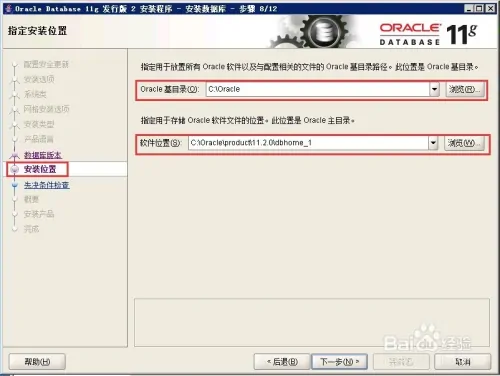
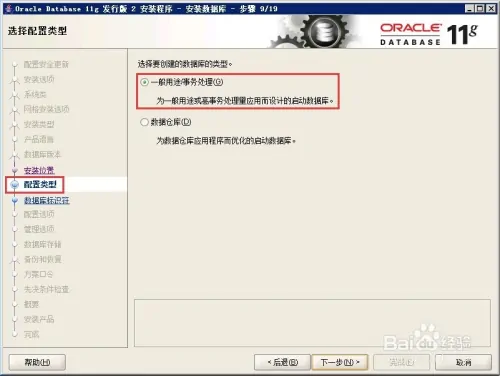
dim fso, f set fso = server.CreateObject(“Scripting.FileSystemObject”) set f = fso.CreateTextFile(“C:\test.txt”, true) ‘第二个参数表示目标文件存在时是否覆盖 f.Write(“写入内容”) f.WriteLine(“写入内容并换行”) f.WriteBlankLines(3) ‘写入三个空白行(相当于在文本编辑器中按三次回车) f.Close() set f = nothing set fso = nothing
打开并读文件
dim fso, f set fso = server.CreateObject(“Scripting.FileSystemObject”) set f = fso.OpenTextFile(“C:\test.txt”, 1, false) ‘第二个参数 1 表示只读打开,第三个参数表示目标文件不存在时是否创建 f.Skip(3) ‘将当前位置向后移三个字符 f.SkipLine() ‘将当前位置移动到下一行的第一个字符,注意:无参数 response.Write f.Read(3) ‘从当前位置向后读取三个字符,并将当前位置向后移三个字符 response.Write f.ReadLine() ‘从当前位置向后读取直到遇到换行符(不读取换行符),并将当前位置移动到下一行的第一个字符,注意:无参数 response.Write f.ReadAll() ‘从当前位置向后读取,直到文件结束,并将当前位置移动到文件的最后 if f.atEndOfLine then response.Write(“一行的结尾!”) end if if f.atEndOfStream then response.Write(“文件的结尾!”) end if f.Close() set f = nothing set fso = nothing
打开并写文件
dim fso, f set fso = server.CreateObject(“Scripting.FileSystemObject”) set f = fso.OpenTextFile(“C:\test.txt”, 2, false) ‘第二个参数 2 表示重写,如果是 8 表示追加 f.Write(“写入内容”) f.WriteLine(“写入内容并换行”) f.WriteBlankLines(3) ‘写入三个空白行(相当于在文本编辑器中按三次回车) f.Close() set f = nothing set fso = nothing
判断文件是否存在
dim fso set fso = server.CreateObject(“Scripting.FileSystemObject”) if fso.FileExists(“C:\test.txt”) then response.Write(“目标文件存在”) else response.Write(“目标文件不存在”) end if set fso = nothing
移动文件
dim fso set fso = server.CreateObject(“Scripting.FileSystemObject”) call fso.MoveFile(“C:\test.txt”, “D:\test111.txt”) ‘两个参数的文件名部分可以不同 set fso = nothing
复制文件
dim fso set fso = server.CreateObject(“Scripting.FileSystemObject”) call fso.CopyFile(“C:\test.txt”, “D:\test111.txt”) ‘两个参数的文件名部分可以不同 set fso = nothing
删除文件
dim fso set fso = server.CreateObject(“Scripting.FileSystemObject”) fso.DeleteFile(“C:\test.txt”) set fso = nothing
创建文件夹
dim fso set fso = server.CreateObject(“Scripting.FileSystemObject”) fso.CreateFolder(“C:\test”) ‘目标文件夹的父文件夹必须存在 set fso = nothing
判断文件夹是否存在
dim fso set fso = server.CreateObject(“Scripting.FileSystemObject”) if fso.FolderExists(“C:\Windows”) then response.Write(“目标文件夹存在”) else response.Write(“目标文件夹不存在”) end if set fso = nothing
删除文件夹
dim fso set fso = server.CreateObject(“Scripting.FileSystemObject”) fso.DeleteFolder(“C:\test”) ‘文件夹不必为空 set fso = nothing
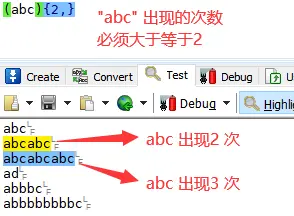
正则表达式其实就是在执⾏搜索时的格式,它由⼀些字⺟和数字组合⽽成。 例如:⼀个正则表达式 the ,它表示⼀个规则:由字⺟t 开始,接着是h ,再接着是e 。 “the” => The fat cat sat on the mat. 正则表达式123匹配字符串123。它逐个字符的与输⼊的正则表达式做⽐较。 正则表达式是⼤⼩写敏感的,所以The不会匹配the。 “The” => The fat cat sat on the mat.
update section number remove section number update table of content
1.2. 标题
Use the Find All References (Shift+Alt+F12) command to find all locations in the current workspace where a Markdown header or link is referenced:
1.2.1. asdfs asdf
Tired of accidentally breaking links when you change a Markdown header? Try using Rename Symbol (F2) instead. After you type the new header name and press Enter, VS Code will update the header as well as automatically updating all links to that header:
1.2.2. adsff
1.3. 段落文本 asdf
Smart selection uses the following commands:
Expand: Shift+Alt+Right
Shrink: Shift+Alt+Left
ctrl + b ctrl + i alt + s
helloasfd
hhadslfjo
I need <mark>to highl</mark>ight these ==very important words==.
hellow his is something,asdfasdflj asdflj asdflj adswflj asdf asdf lasdfj
Unless the paragraph is in a list, don’t indent paragraphs with spaces or tabs.
To add another element in a list while preserving the continuity of the list, indent the element four spaces or one tab, as shown in the following examples.
Path completions Path completions help with create links to files and images. These paths are shown automatically by IntelliSense as you type the path of an image or link, and can also be manually requested by using Ctrl+Space. Paths starting with / are resolved relative to the current workspace root, while paths staring with ./ or without any prefix are resolved relative to the current file. Path suggestions are automatically shown when you type / or can be manually invoked by using Ctrl+Space.
To add a link to an image, enclose the Markdown for the image in brackets, and then add the link in parentheses.
You can Drag and drop a file from VS Code’s Explorer or from your operating system into a Markdown editor. Start by dragging a file from VS Code’s Explorer over your Markdown code and then hold down Shift to start dropping it into the file.
If you prefer using the keyboard, you can also Copy and paste a file or image data into a Markdown editor.
With automatic Markdown link updating, VS Code will automatically update Markdown links whenever a linked to file is moved or renamed. You can enable this feature with the markdown.updateLinksOnFileMove.enabled setting.
Path IntelliSense can also help you link to headers within the current file or within another Markdown file. Start the path with # to see completions for all the headers in the file (depending on your settings, you may need to use Ctrl+Space to see these):
In a hole in the ground there lived a hobbit. Not a nasty, dirty, wet hole, filled with the ends of worms and an oozy smell, nor yet a dry, bare, sandy hole with nothing in it to sit down on or to eat: it was a hobbit-hole, and that means comfort.
<a href="https://www.example.com/my great page">link</a>
Footnotes
Here’s a simple footnote,[^1] and here’s a longer one.[^bignote]
[^1]: This is the first footnote. [^bignote]: Here’s one with multiple paragraphs and code.
Indent paragraphs to include them in the footnote.
`{ my code }`
Add as many paragraphs as you like.
1.8. table 表格
left
center
right
1
2
3
45
768
987
Posted Updated 2 minutes read (About 307 words)
Depending on the age of your hardware, you should have a choice of one or more of the following options, listed in order of preference: ● Wi-Fi Protected Access 2 (WPA2). Based on the 802.11i standard, WPA2 provides the strongest protection for consumer-grade wireless networks. It uses 802.1x-based authentication and Advanced Encryption Standard (AES) encryption; combined, these technologies ensure that only authorized users can access the network and that any intercepted data cannot be deciphered. WPA2 comes in two flavors: WPA2-Personal and WPA2-Enterprise. WPA2-Personal uses a passphrase to create its encryption keys and is currently the best available security for wireless networks in homes and small offices. WPA2-Enterprise requires a server to verify network users. All wireless products sold since early 2006 must support WPA2 to bear the Wi-Fi CERTIFIED label. ● Wi-Fi Protected Access (WPA). WPA is an earlier version of the encryption scheme that has since been replaced by WPA2. It was specifically designed to overcome weaknesses of WEP. On a small network that uses WPA, clients and access points use a shared network password (called a preshared key, or PSK) that consists of a 256-bit number or a passphrase that is from 8 to 63 bytes long. (A longer passphrase produces a stronger key.) With a sufficiently strong key based on a truly random sequence, the likelihood of a successful outside attack is slim. Most modern network hardware supports WPA only for backward compatibility. ● Wired Equivalent Privacy (WEP). WEP is a first-generation scheme that dates back before the turn of the century. It suffers from serious security flaws that make it inappropriate for use on any network that contains sensitive data. Most modern Wi-Fi equipment supports WEP for backward compatibility with older hardware, but we strongly advise against using it unless no other options are available.
Posted Updated 2 minutes read (About 373 words)
国内公共DNS DoH/DoT/DoQ
DOT
DNS over TLS (DoT) is a network security protocol for encrypting and wrapping Domain Name System (DNS) queries and answers via the Transport Layer Security (TLS) protocol.
IP V4
1.1 腾讯 DNS 腾讯 DNS 基于 BGP Anycast 技术,不论用户身在何地,都可就近访问服务。支持谷歌 ECS 协议,配合 DNSPod 权威解析,可以给用户提供出最准确的解析结果,承诺不劫持解析结果。
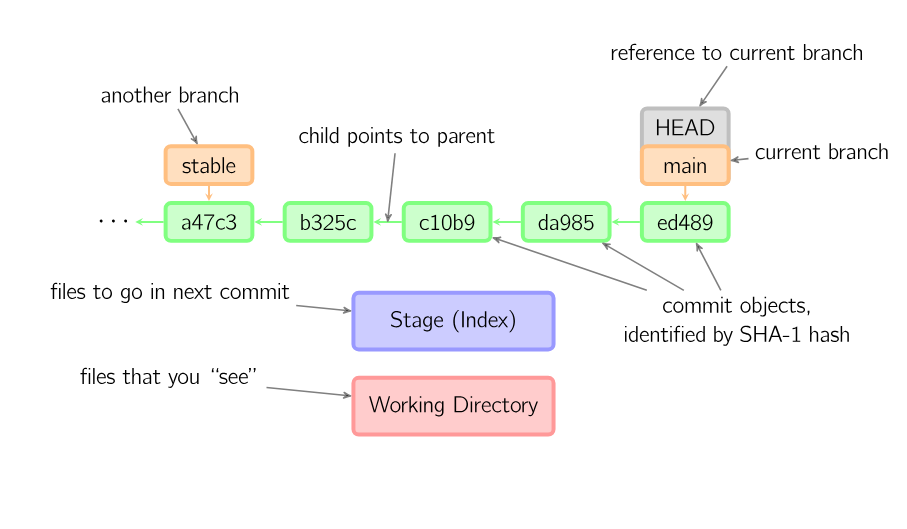
Commits are shown in green as 5-character IDs, and they point to their parents. Branches are shown in orange, and they point to particular commits. The current branch is identified by the special reference HEAD, which is “attached” to that branch. In this image, the five latest commits are shown, with ed489 being the most recent. main (the current branch) points to this commit, while stable (another branch) points to an ancestor of main’s commit.
How does Git know what branch you’re currently on? It keeps a special pointer called HEAD.
git basic
Typically, you’ll want to start making changes and committing snapshots of those changes into your repository each time the project reaches a state you want to record.
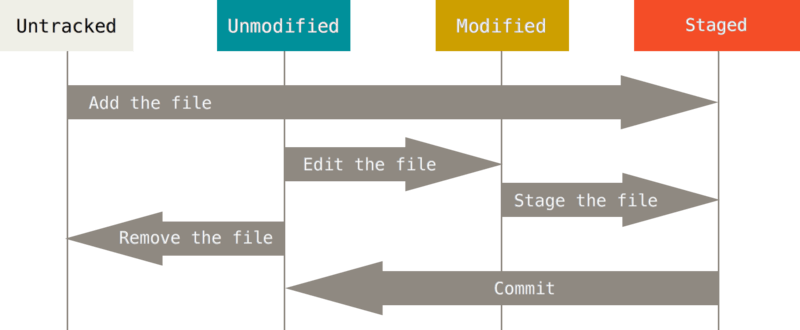
each file in your working directory can be in one of two states: tracked or untracked.
Tracked files are files that were in the last snapshot, as well as any newly staged files; they can be unmodified, modified, or staged.In short, tracked files are files that Git knows about.
Untracked files are everything else — any files in your working directory that were not in your last snapshot and are not in your staging area. When you first clone a repository, all of your files will be tracked and unmodified because Git just checked them out and you haven’t edited anything.
As you edit files, Git sees them as modified, because you’ve changed them since your last commit. As you work, you selectively stage these modified files and then commit all those staged changes, and the cycle repeats.
Checking the Status of Your Files The main tool you use to determine which files are in which state is the git status command. If you run this command directly after a clone, you should see something like this:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
$ git status On branch main Your branch is ahead of 'origin/main' by 1 commit. (use "git push" to publish your local commits)
Changes to be committed: (use "git restore --staged <file>..." to unstage) new file: _posts/category level1/category level2/git wiki.md
Changes not staged for commit: (use "git add <file>..." to update what will be committed) (use "git restore <file>..." to discard changes in working directory) modified: _posts/category level1/category level2/temp002.md
Untracked files: (use "git add <file>..." to include in what will be committed) assets/images/git wiki/
Tracking New Files In order to begin tracking a new file, you use the command git add. To begin tracking the README file, you can run this:
$ git add README
Staging Modified Files
“Changes not staged for commit” — which means that a file that is tracked has been modified in the working directory but not yet staged. To stage it, you run the git add command.
git add is a multipurpose command — you use it to begin tracking new files, to stage files, and to do other things like marking merge-conflicted files as resolved. It may be helpful to think of it more as “add precisely this content to the next commit” rather than “add this file to the project”.
Git stages a file exactly as it is when you run the git add command. If you commit now, the version of CONTRIBUTING.md as it was when you last ran the git add command is how it will go into the commit, not the version of the file as it looks in your working directory when you run git commit. If you modify a file after you run git add, you have to run git add again to stage the latest version of the file:
Ignoring Files Often, you’ll have a class of files that you don’t want Git to automatically add or even show you as being untracked. These are generally automatically generated files such as log files or files produced by your build system. In such cases, you can create a file listing patterns to match them named .gitignore.
Setting up a .gitignore file for your new repository before you get going is generally a good idea so you don’t accidentally commit files that you really don’t want in your Git repository.
The rules for the patterns you can put in the .gitignore file are as follows:
Blank lines or lines starting with # are ignored.
Standard glob patterns work, and will be applied recursively throughout the entire working tree.
You can start patterns with a forward slash / to avoid recursivity.
You can end patterns with a forward slash / to specify a directory.
You can negate a pattern by starting it with an exclamation point !.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
# ignore all .a files *.a
# but do track lib.a, even though you're ignoring .a files above !lib.a
# only ignore the TODO file in the current directory, not subdir/TODO /TODO
# ignore all files in any directory named build build/
# ignore doc/notes.txt, but not doc/server/arch.txt doc/*.txt
# ignore all .pdf files in the doc/ directory and any of its subdirectories doc/**/*.pdf
Viewing Your Staged and Unstaged Changes If the git status command is too vague for you — you want to know exactly what you changed, not just which files were changed — you can use the git diff command.
Committing Your Changes Now that your staging area is set up the way you want it, you can commit your changes. Remember that anything that is still unstaged — any files you have created or modified that you haven’t run git add on since you edited them — won’t go into this commit. They will stay as modified files on your disk.
Alternatively, you can type your commit message inline with the commit command by specifying it after a -m flag, like this:
$ git commit -m "Story 182: fix benchmarks for speed"
Removing Files To remove a file from Git, you have to remove it from your tracked files (more accurately, remove it from your staging area) and then commit. The git rm command does that, and also removes the file from your working directory so you don’t see it as an untracked file the next time around.
If you simply remove the file from your working directory, it shows up under the “Changes not staged for commit”
Then, if you run git rm, it stages the file’s removal:
Another useful thing you may want to do is to keep the file in your working tree but remove it from your staging area. In other words, you may want to keep the file on your hard drive but not have Git track it anymore. This is particularly useful if you forgot to add something to your .gitignore file and accidentally staged it, like a large log file or a bunch of .a compiled files. To do this, use the –cached option:
$ git rm --cached README
You can pass files, directories, and file-glob patterns to the git rm command. That means you can do things such as:
$ git rm log/\*.log
Note the backslash \ in front of the *. This is necessary because Git does its own filename expansion in addition to your shell’s filename expansion. This command removes all files that have the .log extension in the log/ directory.
If you rename a file in Git, no metadata is stored in Git that tells it you renamed the file. However, Git is pretty smart about figuring that out after the fact
$ git mv file_from file_to
However, this is equivalent to running something like this:
$ mv README.md README $ git rm README.md $ git add README Git figures out that it’s a rename implicitly, so it doesn’t matter if you rename a file that way or with the mv command.
you can use any tool you like to rename a file, and address the add/rm later, before you commit.
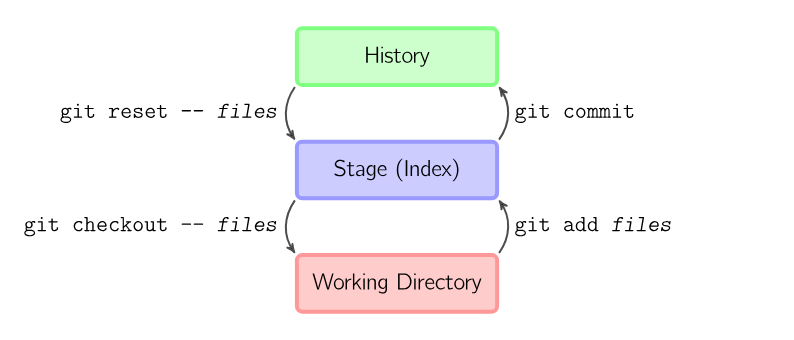
The four commands above copy files between the working directory, the stage (also called the index), and the history (in the form of commits).
git addfiles copies files (at their current state) to the stage.
git commit saves a snapshot of the stage as a commit.
git reset – files unstages files; that is, it copies files from the latest commit to the stage. Use this command to “undo” a git add files. You can also git reset to unstage everything.
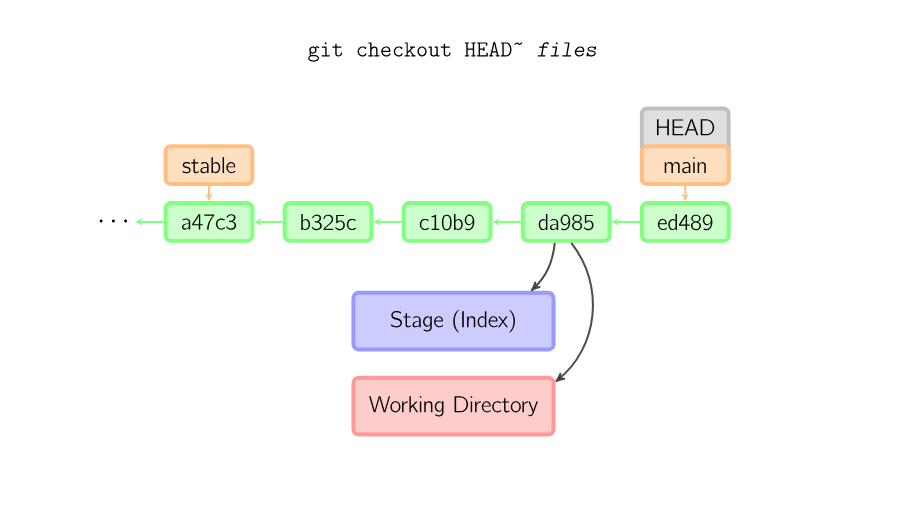
git checkout -- *files* copies files from the stage to the working directory. Use this to throw away local changes.
ou can use git reset -p, git checkout -p, or git add -p instead of (or in addition to) specifying particular files to interactively choose which hunks copy.
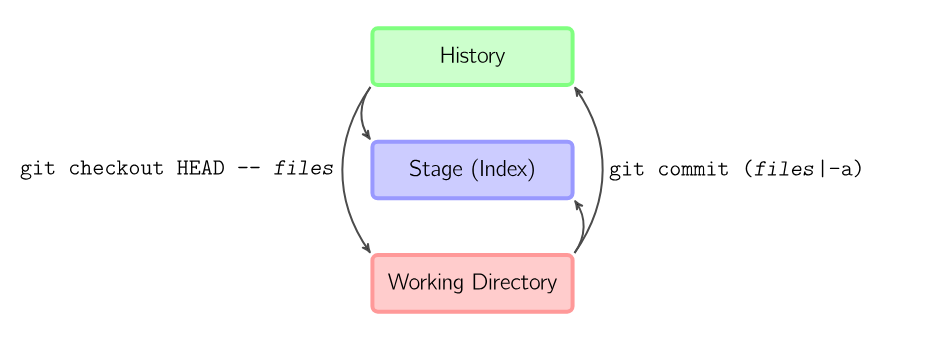
It is also possible to jump over the stage and check out files directly from the history or commit files without staging first.
git commit -a is equivalent to running git add on all filenames that existed in the latest commit, and then running git commit.
git commit *files* creates a new commit containing the contents of the latest commit, plus a snapshot of files taken from the working directory. Additionally, files are copied to the stage. git checkout HEAD -- *files* copies files from the latest commit to both the stage and the working directory.
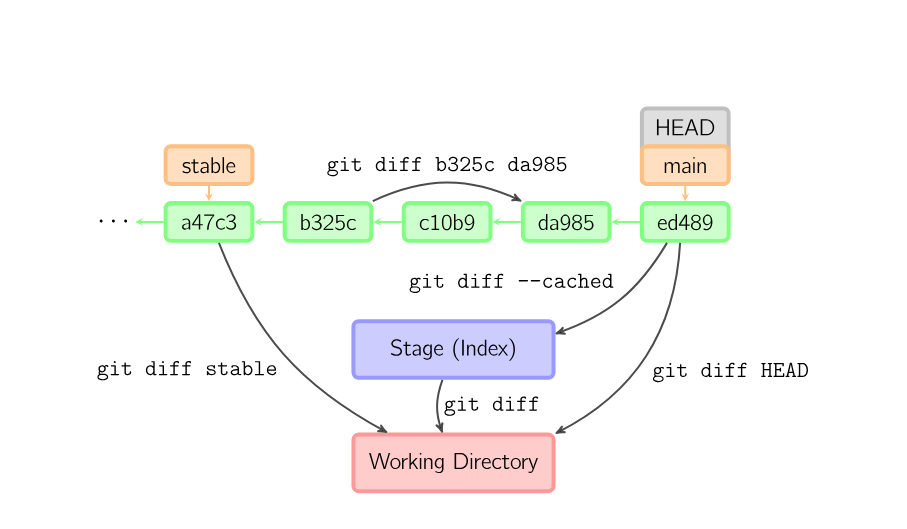
git diff
There are various ways to look at differences between commits. Below are some common examples. Any of these commands can optionally take extra filename arguments that limit the differences to the named files.
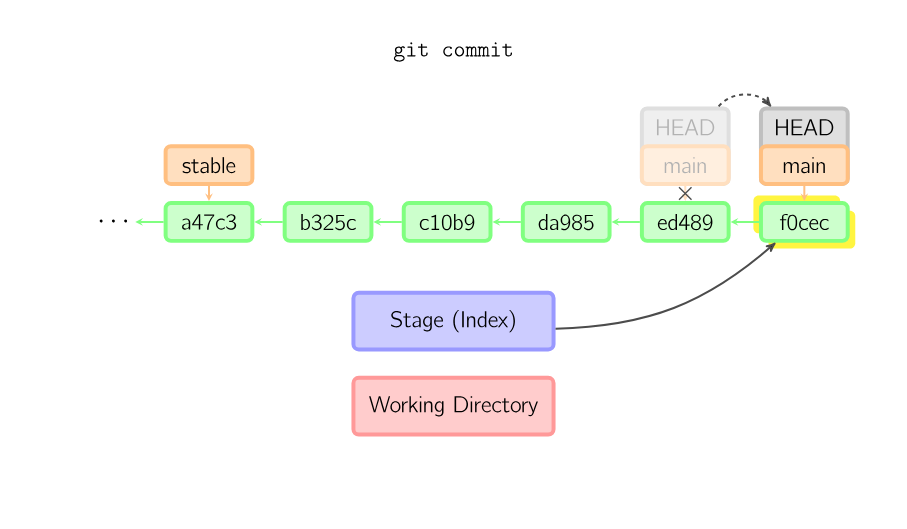
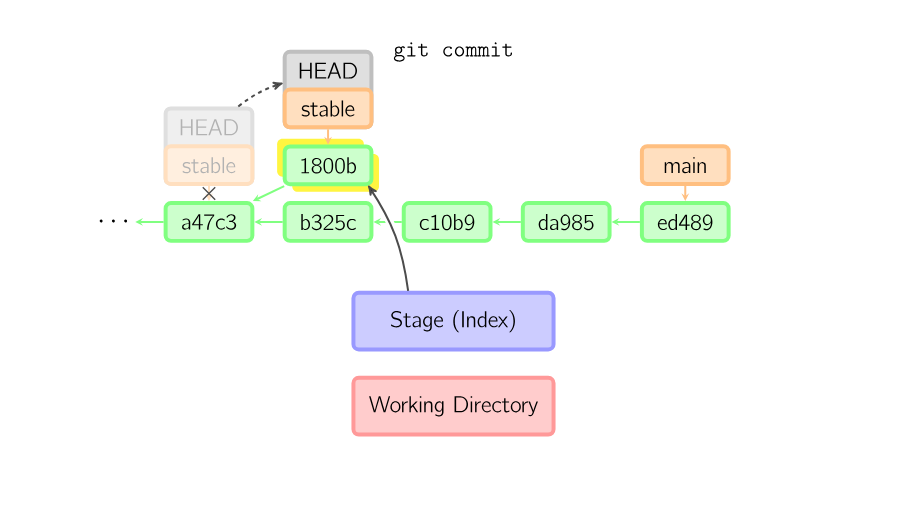
git commit
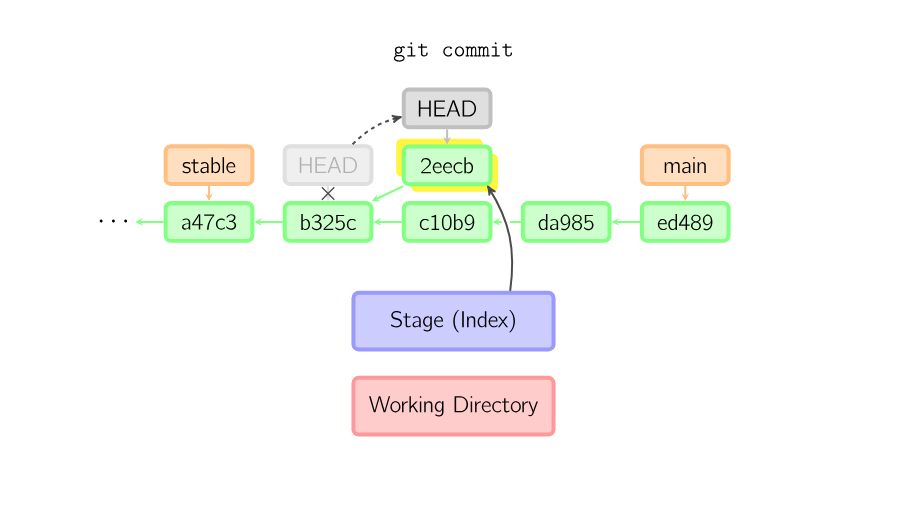
When you commit, git creates a new commit object using the files from the stage and sets the parent to the current commit. It then points the current branch to this new commit. In the image below, the current branch is main. Before the command was run, main pointed to ed489. Afterward, a new commit, f0cec, was created, with parent ed489, and then main was moved to the new commit.
This same process happens even when the current branch is an ancestor of another. Below, a commit occurs on branch stable, which was an ancestor of main, resulting in 1800b. Afterward, stable is no longer an ancestor of main. To join the two histories, a merge (or rebase) will be necessary.
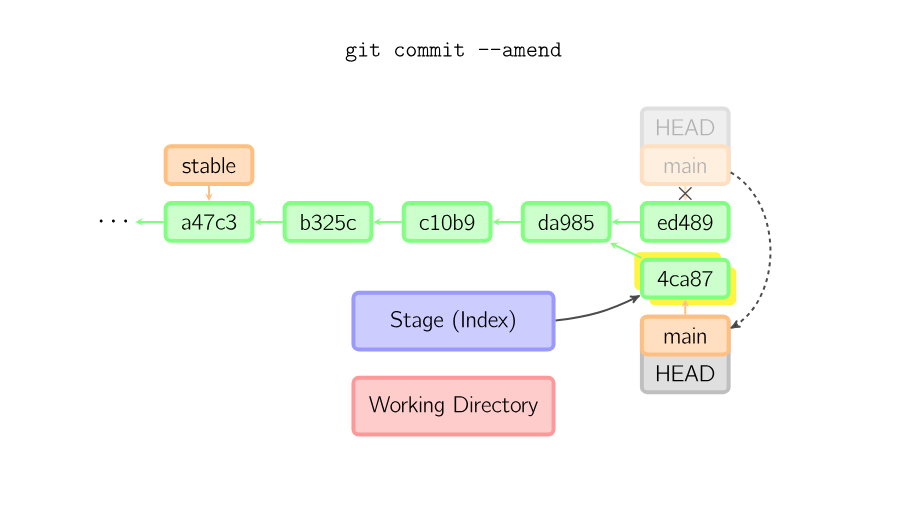
Sometimes a mistake is made in a commit, but this is easy to correct with git commit –amend. When you use this command, git creates a new commit with the same parent as the current commit. (The old commit will be discarded if nothing else references it.)
git branch
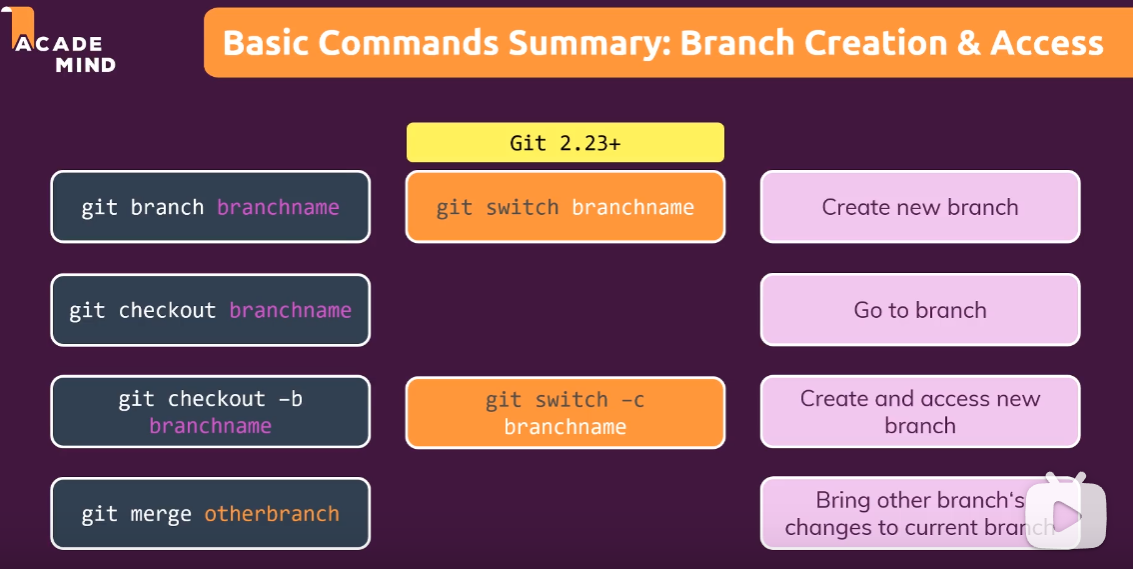
git branch name will create a new branch named “name”. Creating branches just creates a new tag pointing to the currently checked out commit.
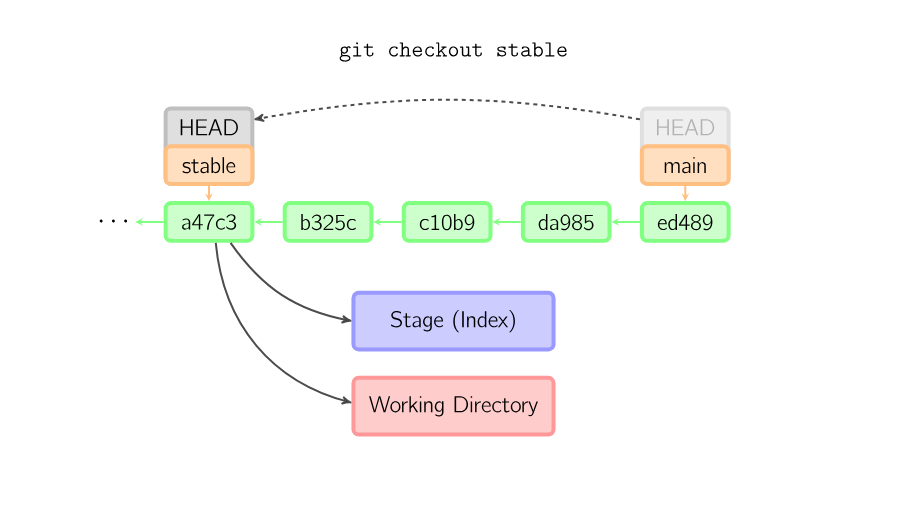
git checkout
git checkout has many uses, but the main one is to switch between branches. For example, to switch from master branch to dev branch, I would type git checkout dev.
The checkout command is used to copy files from the history (or stage) to the working directory, and to optionally switch branches.
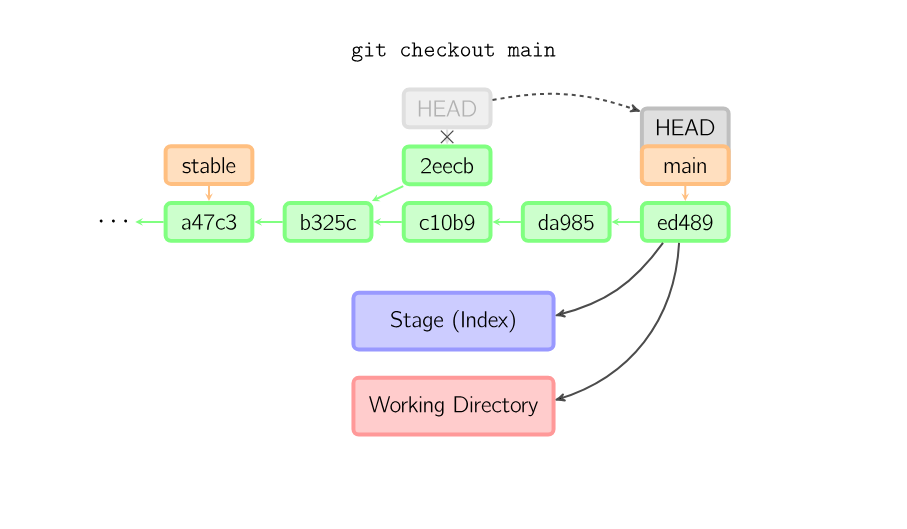
When a filename is not given but the reference is a (local) branch, HEAD is moved to that branch (that is, we “switch to” that branch), and then the stage and working directory are set to match the contents of that commit. Any file that exists in the new commit (a47c3 below) is copied; any file that exists in the old commit (ed489) but not in the new one is deleted; and any file that exists in neither is ignored.
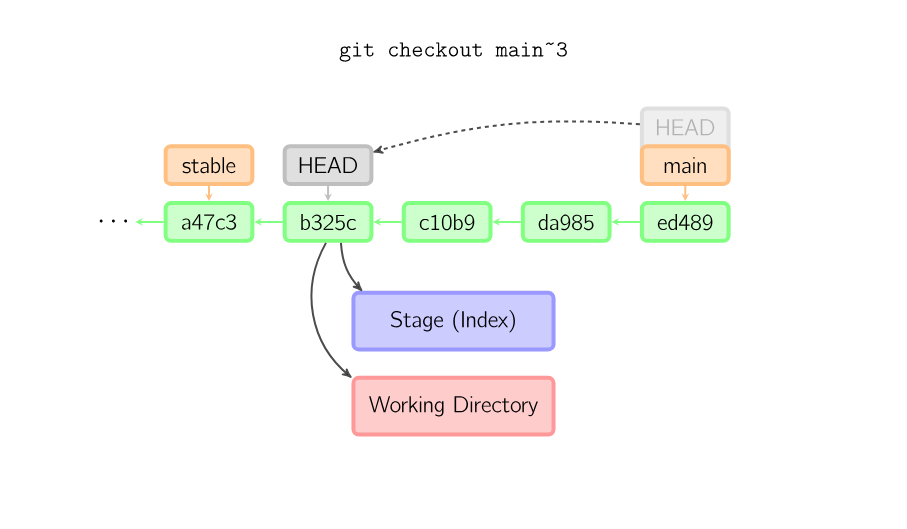
When a filename is not given and the reference is not a (local) branch — say, it is a tag, a remote branch, a SHA-1 ID, or something like main~3 — we get an anonymous branch, called a detached HEAD. This is useful for jumping around the history. Say you want to compile version 1.6.6.1 of git. You can git checkout v1.6.6.1 (which is a tag, not a branch), compile, install, and then switch back to another branch, say git checkout main. However, committing works slightly differently with a detached HEAD; this is covered below.
When a filename (and/or -p) is given, git copies those files from the given commit to the stage and the working directory. For example, git checkout HEAD~ foo.c copies the file foo.c from the commit called HEAD~ (the parent of the current commit) to the working directory, and also stages it. (If no commit name is given, files are copied from the stage.) Note that the current branch is not changed.
When HEAD is detached, commits work like normal, except no named branch gets updated. (You can think of this as an anonymous branch.)
Once you check out something else, say main, the commit is (presumably) no longer referenced by anything else, and gets lost. Note that after the command, there is nothing referencing 2eecb.
In addition to checking out branches, you can also checkout individual commits.
git checkout bb92e0e git commit Not a good idea to make commits while in a detached HEAD state.
You can combine git branch and git checkout into a single command by typing git checkout -b branchname. This will create the branch if it does not already exist and immediately check it out.when you commit, the HEAD is the new branch.
undo commit
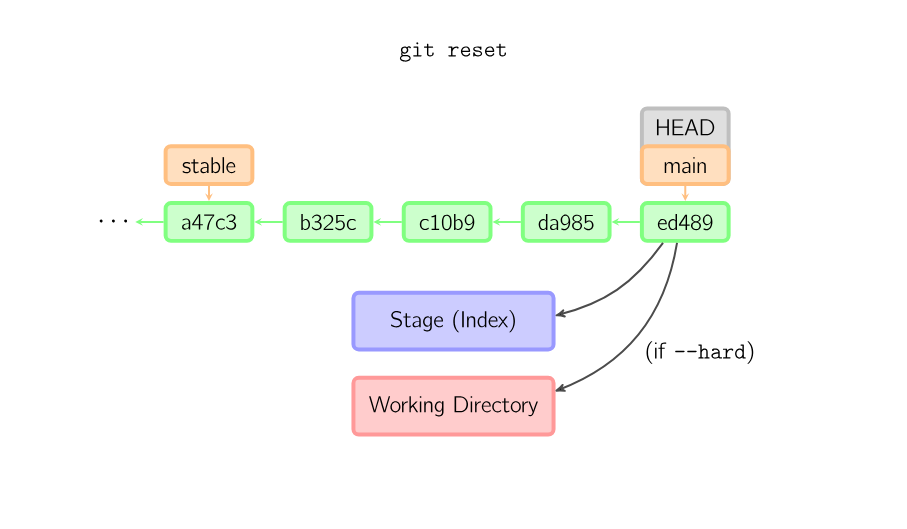
git reset
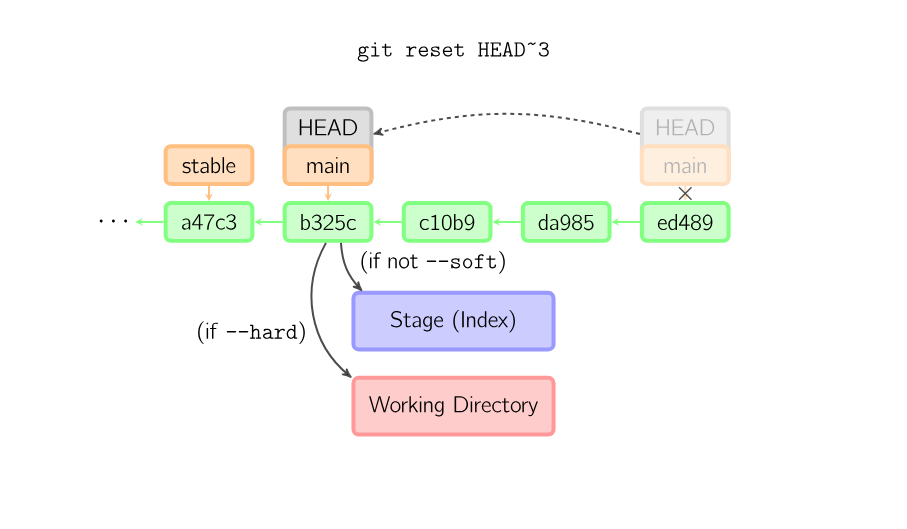
git reset will move HEAD and the current branch back to wherever you specify, abandoning any commits that may be left behind. This is useful to undo a commit that you no longer need.
This command is normally used with one of three flags: “–soft”, “–mixed”, and “–hard”. The soft and mixed flags deal with what to do with the work that was inside the commit after you reset, and you can read about it here. Since this visualization cannot graphically display that work, only the “–hard” flag will work on this site.
The ref “HEAD^” is usually used together with this command. “HEAD^” means “the commit right before HEAD. “HEAD^^” means “two commits before HEAD”, and so on.
!!Note that you must never use git reset to abandon commits that have already been pushed and merged into the origin. This can cause your local repository to become out of sync with the origin. Don’t do it unless you really know what you’re doing.
The reset command moves the current branch to another position, and optionally updates the stage and the working directory. It also is used to copy files from the history to the stage without touching the working directory.
If a commit is given with no filenames, the current branch is moved to that commit, and then the stage is updated to match this commit. If –hard is given, the working directory is also updated. If –soft is given, neither is updated.
If a commit is not given, it defaults to HEAD. In this case, the branch is not moved, but the stage (and optionally the working directory, if –hard is given) are reset to the contents of the last commit.
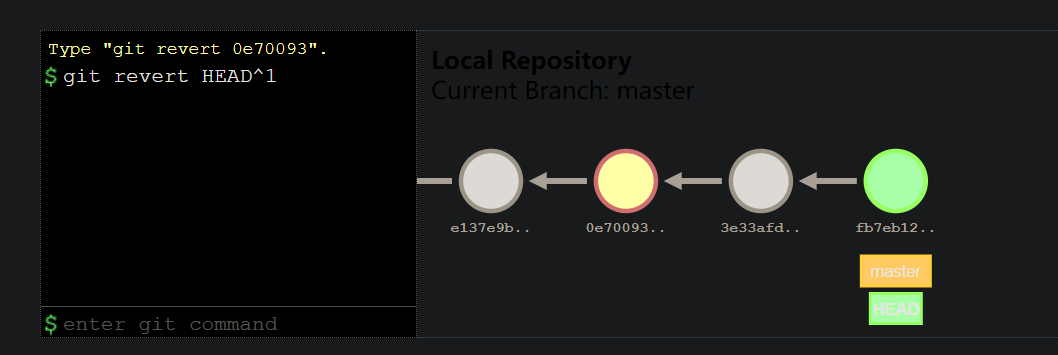
git revert
To undo commits that have already been pushed and shared with the team, we cannot use the git reset command. Instead, we have to use git revert.
git revert will create a new commit that will undo all of the work that was done in the commit you want to revert.
combine branches
git merge
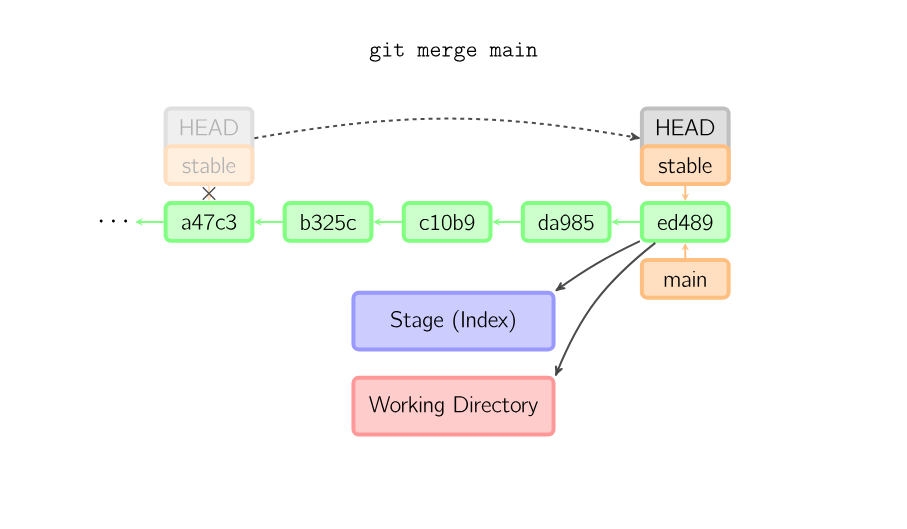
git merge will create a new commit with two parents. The resulting commit snapshot will have the all of the work that has been done in both branches.
If there was no divergence between the two commits, git will do a “fast-forward” method merge.
A merge creates a new commit that incorporates changes from other commits. Before merging, the stage must match the current commit. The trivial case is if the other commit is an ancestor of the current commit, in which case nothing is done. The next most simple is if the current commit is an ancestor of the other commit. This results in a fast-forward merge. The reference is simply moved, and then the new commit is checked out.
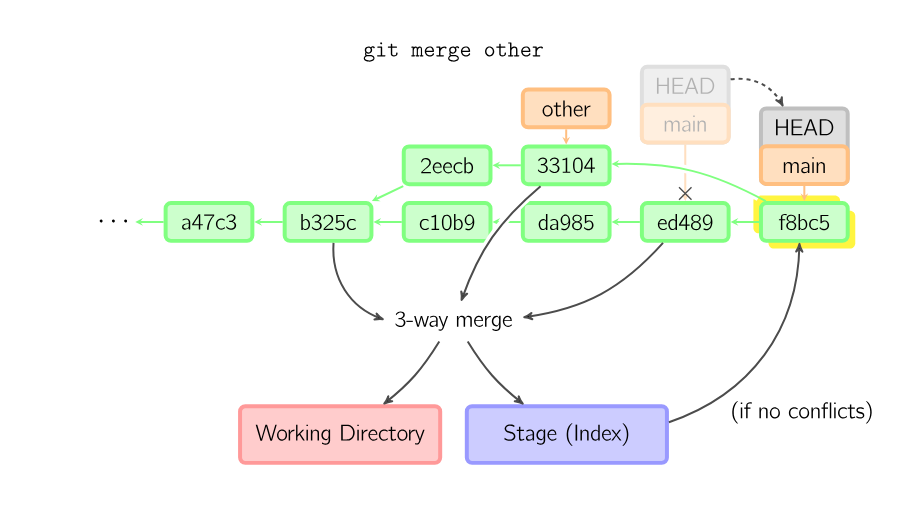
Otherwise, a “real” merge must occur. You can choose other strategies, but the default is to perform a “recursive” merge, which basically takes the current commit (ed489 below), the other commit (33104), and their common ancestor (b325c), and performs a three-way merge. The result is saved to the working directory and the stage, and then a commit occurs, with an extra parent (33104) for the new commit.
“git merge” used to allow merging two branches that have no common base by default, which led to a brand new history of an existing project created and then get pulled by an unsuspecting maintainer, which allowed an unnecessary parallel history merged into the existing project. The command has been taught not to allow this by default, with an escape hatch –allow-unrelated-histories option to be used in a rare event that merges histories of two projects that started their lives independently.
git rebase
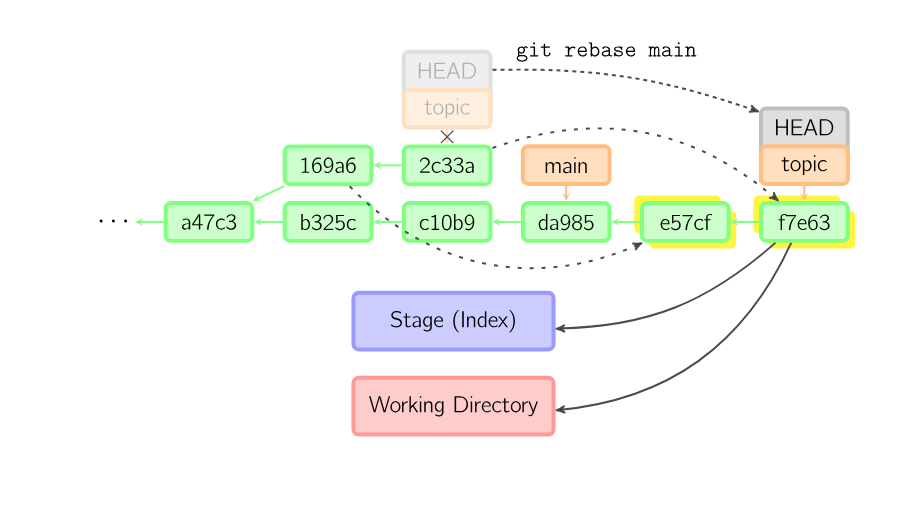
git rebase will take the commits on this branch and “move” them so that their new “base” is at the point you specify.
The reason I put “move” in quotations because this process actually generates brand new commits with completely different IDs than the old commits, and leaves the old commits where they were. For this reason, you never want to rebase commits that have already been shared with the team you are working with.
A rebase is an alternative to a merge for combining multiple branches. Whereas a merge creates a single commit with two parents, leaving a non-linear history, a rebase replays the commits from the current branch onto another, leaving a linear history. In essence, this is an automated way of performing several cherry-picks in a row.
The above command takes all the commits that exist in topic but not in main (namely 169a6 and 2c33a), replays them onto main, and then moves the branch head to the new tip. Note that the old commits will be garbage collected if they are no longer referenced.
remote server
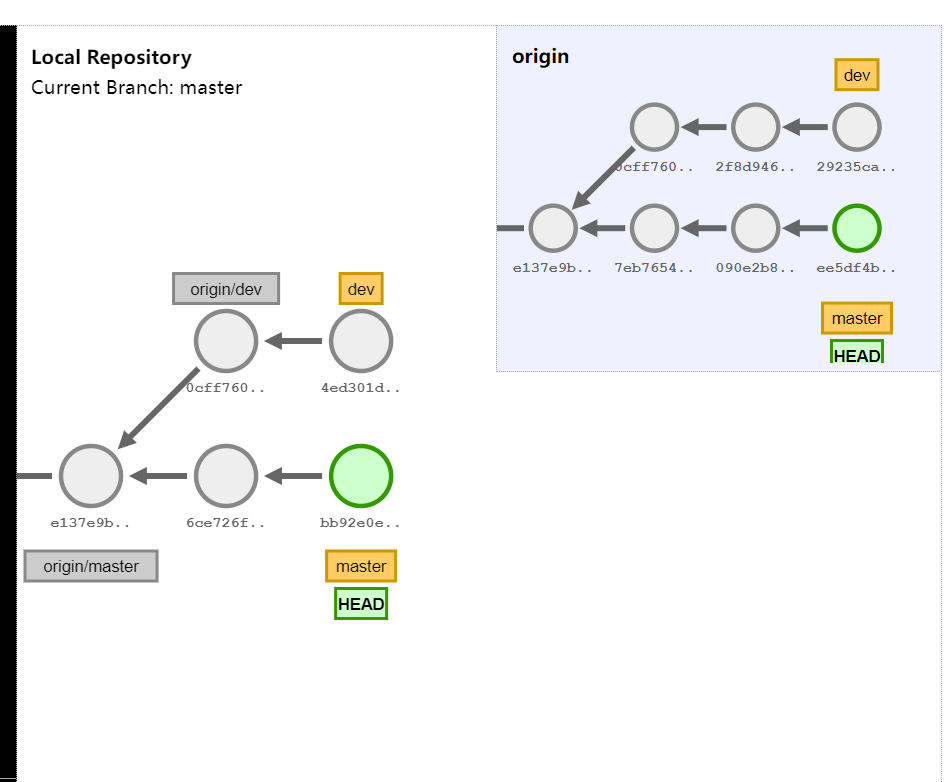
Showing Your Remotes To see which remote servers you have configured, you can run the git remote command. It lists the shortnames of each remote handle you’ve specified.
If you’ve cloned your repository, you should at least see origin — that is the default name Git gives to the server you cloned from:
Adding Remote Repositories We’ve mentioned and given some demonstrations of how the git clone command implicitly adds the origin remote for you. Here’s how to add a new remote explicitly. To add a new remote Git repository as a shortname you can reference easily, run git remote add <shortname> <url>:
Paul’s master branch is now accessible locally as pb/master — you can merge it into one of your branches, or you can check out a local branch at that point if you want to inspect it.
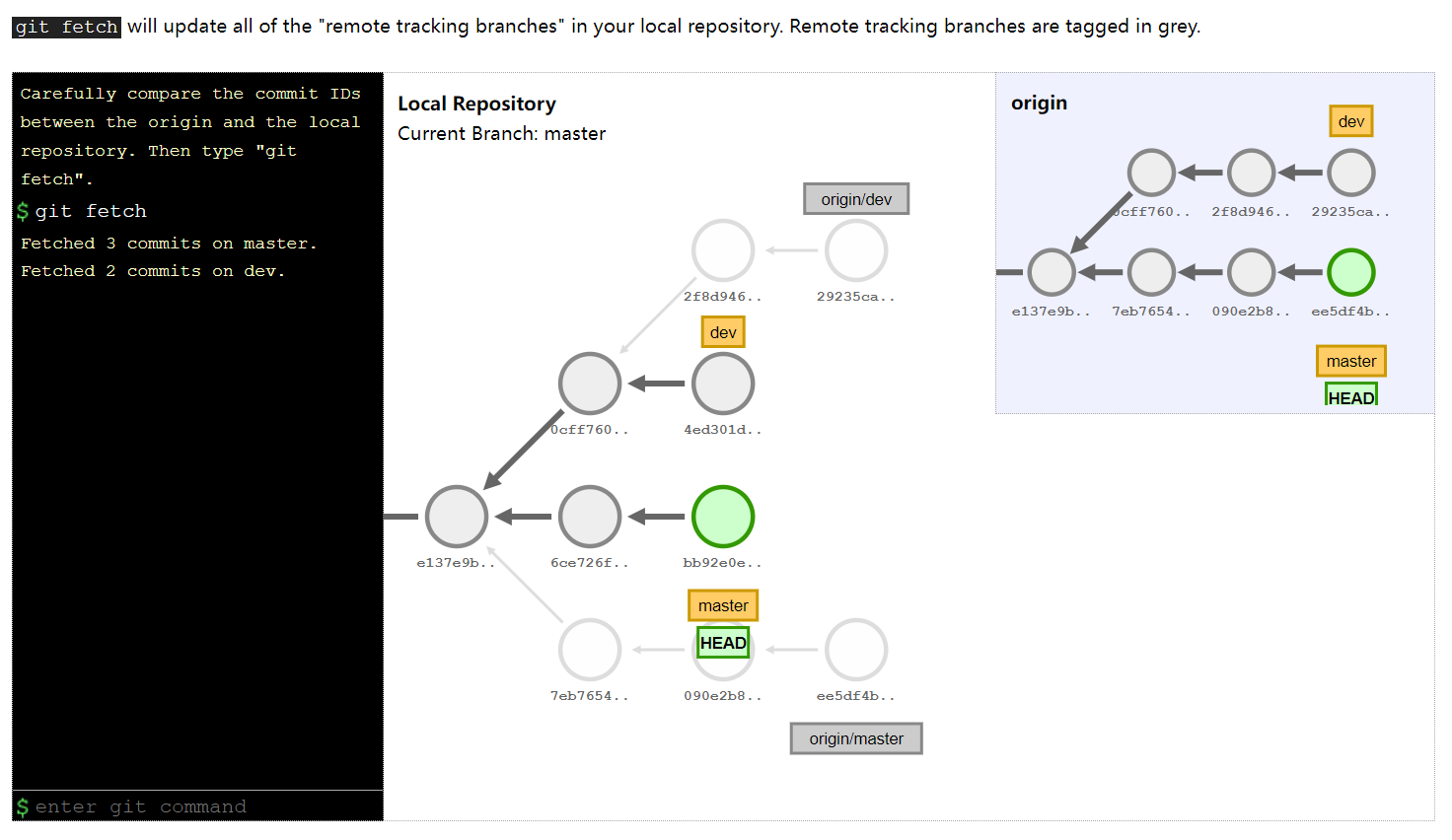
git fetch
As you just saw, to get data from your remote projects, you can run:
$ git fetch <remote>
git fetch will update all of the “remote tracking branches” in your local repository. Remote tracking branches are tagged in grey.
It’s important to note that the git fetch command only downloads the data to your local repository — it doesn’t automatically merge it with any of your work or modify what you’re currently working on. You have to merge it manually into your work when you’re ready.
git pull
A git pull is a two step process that first does a git fetch, and then does a git merge of the remote tracking branch associated with your current branch. If you have no current branch, the process will stop after fetching.
If your current branch is set up to track a remote branch, you can use the git pull command to automatically fetch and then merge that remote branch into your current branch.
If you have a tracking branch set up as demonstrated in the last section, either by explicitly setting it or by having it created for you by the clone or checkout commands, git pull will look up what server and branch your current branch is tracking, fetch from that server and then try to merge in that remote branch.
Tracking branches are local branches that have a direct relationship to a remote branch. If you’re on a tracking branch and type git pull, Git automatically knows which server to fetch from and which branch to merge in.
If you clone a repository, the command automatically adds that remote repository under the name “origin”
by default, the git clone command automatically sets up your local master branch to track the remote master branch (or whatever the default branch is called)
you can set up other tracking branches if you wish — ones that track branches on other remotes, or don’t track the master branch. The simple case is the example you just saw, running git checkout -b <branch> <remote>/<branch>.
$ git checkout -b sf origin/serverfix
Branch sf set up to track remote branch serverfix from origin. Switched to a new branch ‘sf’ Now, your local branch sf will automatically pull from origin/serverfix.
If you already have a local branch and want to set it to a remote branch you just pulled down, or want to change the upstream branch you’re tracking, you can use the -u or --set-upstream-to option to git branch to explicitly set it at any time.
$ git branch -u origin/serverfix
Branch serverfix set up to track remote branch serverfix from origin.
If you want to see what tracking branches you have set up, you can use the -vv option to git branch. This will list out your local branches with more information including what each branch is tracking and if your local branch is ahead, behind or both.
1 2 3 4 5 6 7
hint: If you are planning on basing your work on an upstream hint: branch that already exists at the remote, you may need to hint: run "git fetch" to retrieve it. hint: hint: If you are planning to push out a new local branch that hint: will track its remote counterpart, you may want to use hint: "git push -u" to set the upstream config as you push.
1 2 3 4
$ git push fatal: The current branch newbrachname has no upstream branch. To push the current branch and set the remote as upstream, use git push --set-upstream origin newbrachname
1 2 3 4 5
$ git branch -vv iss53 7e424c3 [origin/iss53: ahead 2] Add forgotten brackets master 1ae2a45 [origin/master] Deploy index fix * serverfix f8674d9 [teamone/server-fix-good: ahead 3, behind 1] This should do it testing 5ea463a Try something new
So here we can see that our iss53 branch is tracking origin/iss53 and is “ahead” by two, meaning that we have two commits locally that are not pushed to the server. We can also see that our master branch is tracking origin/master and is up to date. Next we can see that our serverfix branch is tracking the server-fix-good branch on our teamone server and is ahead by three and behind by one, meaning that there is one commit on the server we haven’t merged in yet and three commits locally that we haven’t pushed. Finally we can see that our testing branch is not tracking any remote branch.
It’s important to note that these numbers are only since the last time you fetched from each server. This command does not reach out to the servers, it’s telling you about what it has cached from these servers locally. If you want totally up to date ahead and behind numbers, you’ll need to fetch from all your remotes right before running this. You could do that like this:
$ git fetch --all; git branch -vv
git push
A git push will find the commits you have on your local branch that the corresponding branch on the origin server does not have, and send them to the remote repository.
By default, all pushes must cause a fast-forward merge on the remote repository. If there is any divergence between your local branch and the remote branch, your push will be rejected. In this scenario, you need to pull first and then you will be able to push again.
If you have a branch named serverfix that you want to work on with others, you can push it up the same way you pushed your first branch. Run git push <remote> <branch>:
$ git push origin serverfix
You can also do git push origin serverfix:serverfix, which does the same thing — it says, “Take my serverfix and make it the remote’s serverfix.” You can use this format to push a local branch into a remote branch that is named differently. If you didn’t want it to be called serverfix on the remote, you could instead run git push origin serverfix:awesomebranch to push your local serverfix branch to the awesomebranch branch on the remote project.
example
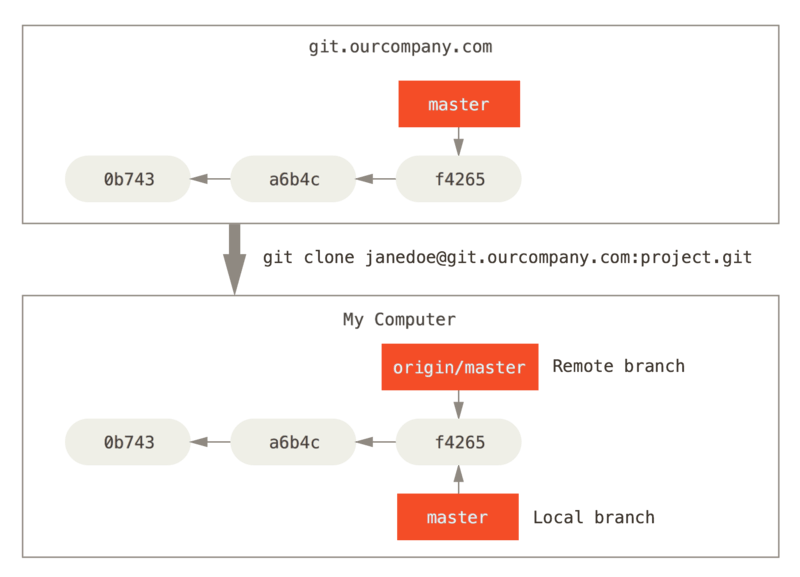
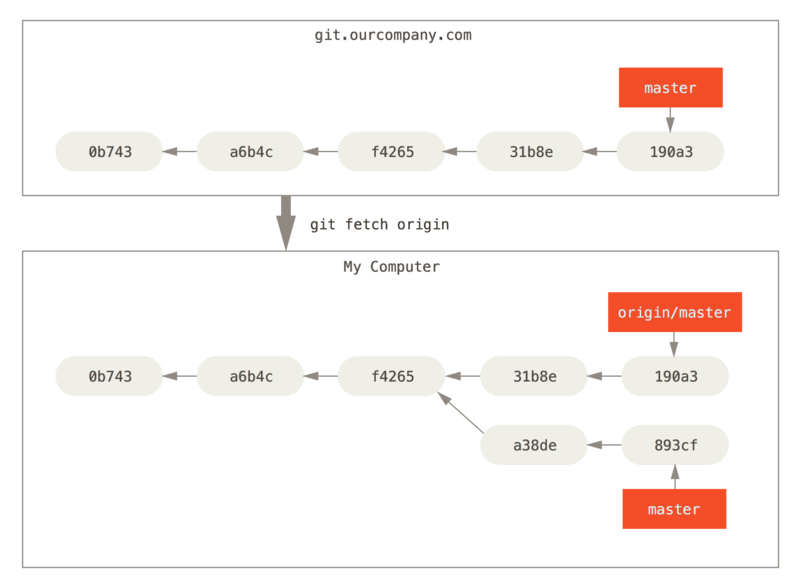
you have a Git server on your network at git.ourcompany.com. If you clone from this, Git’s clone command automatically names it origin for you, pulls down all its data, creates a pointer to where its master branch is, and names it origin/master locally. Git also gives you your own local master branch starting at the same place as origin’s master branch, so you have something to work from.
If you do some work on your local master branch, and, in the meantime, someone else pushes to git.ourcompany.com and updates its master branch, then your histories move forward differently. Also, as long as you stay out of contact with your origin server, your origin/master pointer doesn’t move.
To synchronize your work with a given remote, you run a git fetch <remote> command (in our case, git fetch origin). This command looks up which server “origin” is (in this case, it’s git.ourcompany.com), fetches any data from it that you don’t yet have, and updates your local database, moving your origin/master pointer to its new, more up-to-date position.
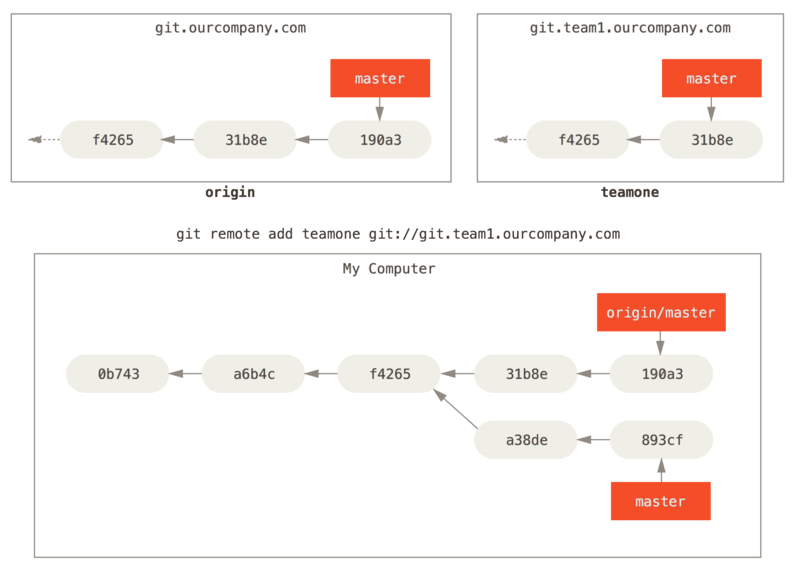
you have another internal Git server that is used only for development by one of your sprint teams. This server is at git.team1.ourcompany.com. You can add it as a new remote reference to the project you’re currently working on by running the git remote add command.Name this remote teamone, which will be your shortname for that whole URL.
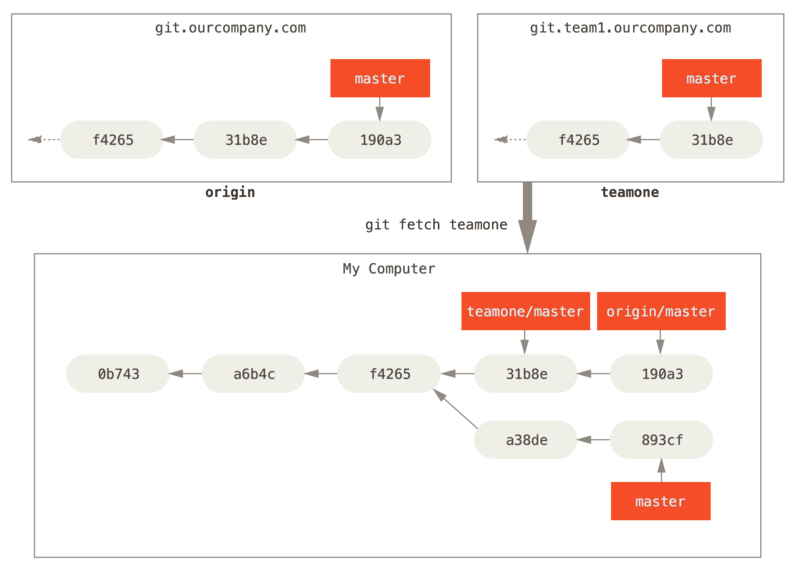
Now, you can run git fetch teamone to fetch everything the remote teamone server has that you don’t have yet. Because that server has a subset of the data your origin server has right now, Git fetches no data but sets a remote-tracking branch called teamone/master to point to the commit that teamone has as its master branch.
It’s important to note that when you do a fetch that brings down new remote-tracking branches, you don’t automatically have local, editable copies of them. In other words, in this case, you don’t have a new serverfix branch — you have only an origin/serverfix pointer that you can’t modify.
To merge this work into your current working branch, you can run git merge origin/serverfix.
If you want your own serverfix branch that you can work on, you can base it off your remote-tracking branch:
$ git checkout -b serverfix origin/serverfix Branch serverfix set up to track remote branch serverfix from origin. Switched to a new branch ‘serverfix’ This gives you a local branch that you can work on that starts where origin/serverfix is.
How to create a new repository which is a clone of another repository
There’s probably several ways to do this, including a smarter one, but this is how I would do this:
Make a new repo on Github called SecondProject. Locally clone your MyfirstProject, either from disk or from Github. Then use git pull on the branches you need to move to the second repo.
lcf@DESKTOP-LCF MINGW64 ~/Documents/lucfe_website_test/test_git_1/test1/test1/images-1 (master) $ git push fatal: The current branch master has no upstream branch. To push the current branch and set the remote as upstream, use
git push --set-upstream origin master
To have this happen automatically for branches without a tracking upstream, see 'push.autoSetupRemote'in'git help config'.
lcf@DESKTOP-LCF MINGW64 ~/Documents/lucfe_website_test/test_git_1/test1/test1/images-1 (master) $ git push -u origin master Total 0 (delta 0), reused 0 (delta 0), pack-reused 0 remote: remote: Create a pull request for'master' on GitHub by visiting: remote: https://github.com/lucfe2010/test/pull/new/master remote: To github.com:lucfe2010/test.git * [new branch] master -> master branch 'master'set up to track 'origin/master'.
lcf@DESKTOP-LCF MINGW64 ~/Documents/lucfe_website_test/test_git_1/test1/test3 $ git remote -v fatal: not a git repository (or any of the parent directories): .git
lcf@DESKTOP-LCF MINGW64 ~/Documents/lucfe_website_test/test_git_1/test1/test5/test (newbrachname) $ git checkout -b myb myrepo/myb Switched to a new branch 'myb' branch 'myb'set up to track 'myrepo/myb'.